Recommender systems drive every action that you take online, from the selection of this web page that you’re reading now to more obvious examples like online shopping. They play a critical role in driving user engagement on online platforms, selecting a few relevant goods or services from the exponentially growing number of available options. On some of the largest commercial platforms, recommendations account for as much as 30% of the revenue. A 1% improvement in the quality of recommendations can translate into billions of dollars in revenue.
With the rapid growth in scale of industry datasets, deep learning (DL) recommender models, which capitalize on very large amounts of training data, have started to gain advantages over traditional methods such as content-based, neighborhood, and latent factor methods. DL recommender models are built upon existing techniques such as embeddings to handle categorical variables and factorization to model the interactions between variables. However, they also tap into the vast and rapidly growing literature on novel network architectures and optimization algorithms to build and train more expressive models.
Consequently, the combination of more sophisticated models and rapid data growth has raised the bar for computational resources required for training while also placing new burdens on production systems. To meet the computational demands for large-scale DL recommender systems training and inference, NVIDIA introduces Merlin.
Merlin is an end-to-end recommender-on-GPU framework that aims to provide fast feature engineering and high training throughput to enable fast experimentation and production retraining of DL recommender models. Merlin also enables low latency, high-throughput, production inference.
Before diving into Merlin, we discuss more about the challenges that large-scale recommender systems are facing today.
Recommender systems overview
Figure 1 shows an example end-to-end recommender system architecture.
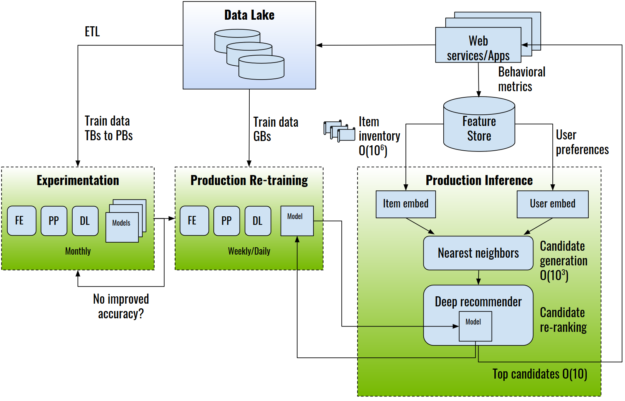
Recommender systems are trained using data gathered about the users, items, and their interactions, which include impressions, clicks, likes, mentions, and so on. This information is typically stored in a data lake or warehouse.
For the experimentation phase, extract-transform-load (ETL) operations prepare and export datasets for training, usually in the form of tabular data that can reach TB or PB scale. An example public dataset of this type is the Criteo Terabyte click logs dataset, which contains click logs of four billion interactions over a period of 24 days. Industry datasets can be orders of magnitude larger, containing years’ worth of data.
During experimentation, data scientists and machine learning engineers use feature engineering, which creates new features by transforming existing ones; and preprocessing, which prepares the engineered features for consumption by the model. Training is then performed using DL frameworks such as TensorFlow, PyTorch, or the NVIDIA recommender-specific training framework, HugeCTR.
After the models have been trained and evaluated offline, they can be moved into production for online evaluation, typically through A/B testing. The recommender system inference process involves selecting and ranking candidate items by the predicted probability that the user will interact with them.
Selection of a subset of items is necessary for large commercial databases, with millions of items to choose from. The selection method is typically a highly efficient algorithm such as approximate nearest neighbors, random forest, or filtering based on user preferences and business rules. The DL recommender model re-ranks the candidates and those with the highest predicted probability are presented to the user.
Recommender system challenges
There are many challenges when training large-scale recommender systems:
- Huge datasets: Commercial recommender systems are often trained on large datasets, often terabytes or more. At this scale, data ETL and preprocessing steps often take much more time than training the DL model.
- Complex data preprocessing and feature engineering pipelines: Datasets need to be preprocessed and transformed into a suitable form to be used with DL models and frameworks. Meanwhile, feature engineering trials create numerous sets of new features from existing ones, which are then tested for effectiveness. In addition, data loading at train time can become the input bottleneck, leading to GPU underutilization.
- Extensive repeated experimentation: The whole data ETL, engineering, training, and evaluation process likely must be repeated many times on many model architectures, requiring significant computational resources and time. Yet after being deployed, recommender systems also require periodic retraining to account for new users, items and recent trends in order to maintain high accuracy over time.
- Huge embedding tables: Embedding is a universally employed technique nowadays to handle categorical variables, most notably user and item IDs. On large commercial platforms, the user and item base can easily reach an order of hundreds of millions if not billions, requiring a large amount of memory compared to other types of DL layers. At the same time, unlike other DL operations, embedding lookup is memory bandwidth–constrained. While the CPU generally offers a larger memory pool, it has much lower memory bandwidth compared to a GPU.
- Distributed training: While distributed training is continuously setting new records in training DL models in the vision and natural language domains, as reflected by the MLPerf benchmark, distributed training is a still relatively new territory for recommender systems, due to the unique combination of large data compared to other domains and large models. It requires both model parallelism and data parallelism, therefore it is hard to achieve high scale-out efficiency.
Some notable challenges for deploying large-scale recommendation systems in production include the following:
- Real-time inference: For each query user, the number of user-item pairs to score can be as large as a few thousands even after a candidate reduction phase. This places an extremely heavy duty on the DL recommender system inference server, which must handle high throughput to serve many users concurrently, yet at low latency to satisfy stringent latency thresholds of online commerce engines.
- Monitoring and retraining: Recommender systems operate in continuously changing environments: new users registering, new items becoming available, and hot trends emerging. As such, the recommender systems need ongoing monitoring and retraining to ensure high effectiveness. The inference server must also be able to concurrently deploy different versions of a model, and load/unload models on the fly to facilitate A/B testing.
NVIDIA Merlin: End-to-end recommender systems on NVIDIA GPUs
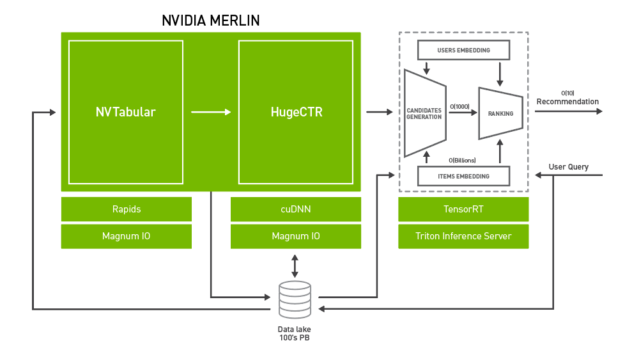
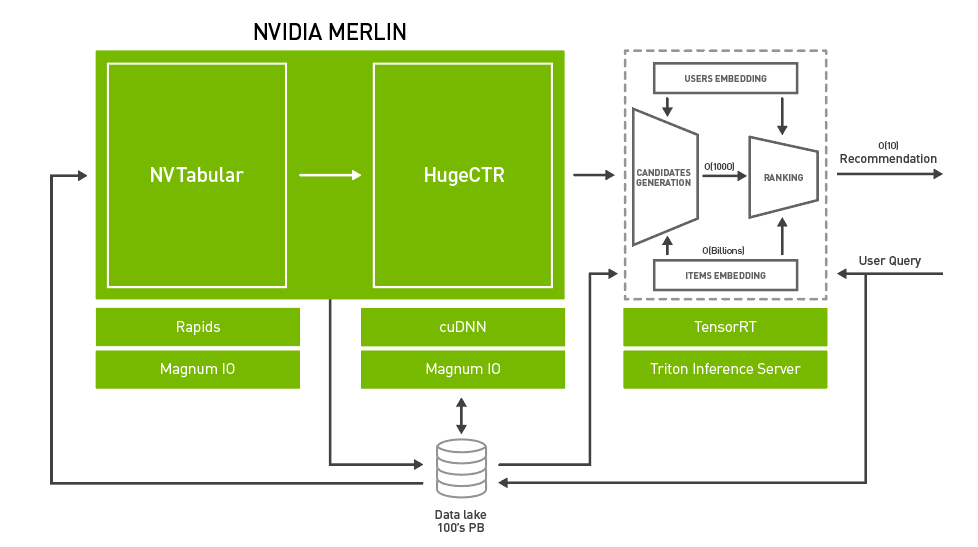
To systematically address the above-mentioned challenges, NVIDIA introduces Merlin. NVIDIA Merlin is an application framework and ecosystem created to facilitate all phases of recommender system development, from experimentation to production, accelerated on NVIDIA GPUs. Figure 2 shows an architectural diagram of Merlin, with three main components:
- Merlin ETL: A collection of tools for fast recommender system feature engineering and preprocessing on GPU. NVTabular offers high-speed, on-GPU data preprocessing and transformation capabilities to handle terabyte-scale tabular datasets. The output of NVTabular can be made available to a training framework such as HugeCTR, PyTorch, or TensorFlow at high throughput using NVTabular data loader extensions, eliminating the input bottleneck.
- Merlin training: A collection of DL recommender system models and training tools:
- HugeCTR is a highly efficient C++ recommender system dedicated training framework. It features both multi-GPU and multi-node training, and supports both model-parallel and data-parallel scaling. HugeCTR covers common and recent recommender system architectures such as Wide and Deep (W&D), Deep Cross Network, and DeepFM, with Deep Learning Recommender Model (DLRM) support coming soon.
- DLRM, Wide and Deep (W&D), Neural Collaborative Filtering (NCF), and Variational AutoEncoder (VAE) form part of the NVIDIA GPU-accelerated DL model portfolio that covers a wide range of network architectures and applications in many different domains beyond recommender systems, including image, text and speech analysis. These models are designed and optimized for training with TensorFlow and PyTorch.
- Merlin inference: NVIDIA TensorRT and NVIDIA Triton Inference Server (formerly TensorRT Inference Server).
- NVIDIA TensorRT is an SDK for high performance DL inference. It includes a DL inference optimizer and runtime that delivers low latency and high throughput for DL inference applications.
- Triton Server provides a comprehensive, GPU-optimized inferencing solution, allowing models from a variety of backends to be served, including PyTorch, TensorFlow, TensorRT, and Open Neural Network Exchange (ONNX) runtime. Triton Server automatically manages and makes use of all the available GPUs and offers capability to serve multiple versions of a model and report various performance metrics, allowing for effective model monitoring and A/B testing.
In the next sections, we explore each of these components in turn.
NVTabular: Fast tabular data transformation and loading
The time taken to perform feature engineering and preprocessing of recommender system datasets often exceeds the time it takes to train the model itself. As a concrete example, processing the Criteo Terabyte click logs dataset takes 5.5 days to complete using the open source provided script, while training DLRM on the processed dataset takes well under one hour on a single V100 GPU.
NVTabular is a feature engineering and preprocessing library, designed to quickly and easily manipulate terabyte-scale datasets. It is especially suitable for recommender systems, which require a scalable way to process additional information, such as users and item metadata and contextual information. It provides a high-level abstraction to simplify code and accelerates computation on the GPU using the RAPIDS cuDF library. Using NVTabular, with just 10-20 lines of high-level API code, you can set up a data engineering pipeline and achieve up to 10X speedup compared to optimized CPU-based approaches while experiencing no dataset size limitations, regardless of the GPU/CPU memory capacity.
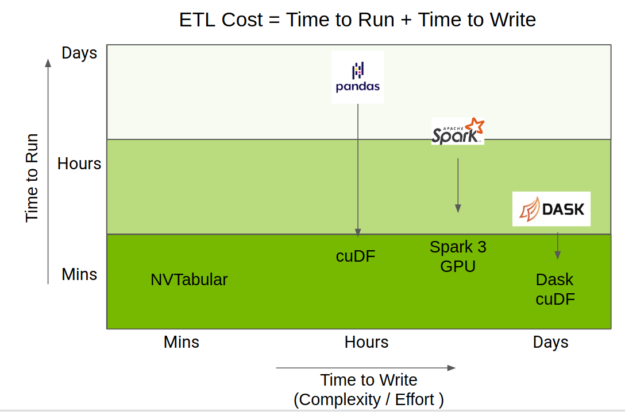
The total time taken to do ETL is a mix of the time to run the code, but also the time taken to write it. The RAPIDS team has done amazing work accelerating the Python data science ecosystem on GPU, providing acceleration through cuDF, Apache Spark 3.0, and Dask-cuDF.
NVTabular uses those accelerations but provides a higher-level API focused on recommender systems, which greatly simplifies code complexity while still providing the same level of performance. Figure 3 shows the positioning of NVTabular relative to other dataframe libraries.
The following code example shows an actual preprocessing workflow required to transform the 1-TB Criteo Ads dataset, implemented with just a dozen lines of code using NVTabular. Briefly, numerical and categorical columns are specified. Next, we define an NVTabular workflow and supply a set of train and validation files. Then, preprocessing operations are added to the workflow and data is persisted to disk. In comparison, custom-built processing codes, such as the NumPy-based data util in Facebook’s DLRM implementation, can have 500-1000 lines of code for the same pipeline.
import nvtabular as nvt
import glob
cont_names = ["I"+str(x) for x in range(1, 14)] # specify continuous feature names
cat_names = ["C"+str(x) for x in range(1, 27)] # specify categorical feature names
label_names = ["label"] # specify target feature
columns = label_names + cat_names + cont_names # all feature names
# initialize Workflow
proc = nvt.Worfklow(cat_names=cat_names, cont_names=cont_names, label_name=label_names)
# create datsets from input files
train_files = glob.glob("./dataset/train/*.parquet")
valid_files = glob.glob("./dataset/valid/*.parquet")
train_dataset = nvt.dataset(train_files, gpu_memory_frac=0.1)
valid_dataset = nvt.dataset(valid_files, gpu_memory_frac=0.1)
# add feature engineering and preprocessing ops to Workflow
proc.add_cont_feature([nvt.ops.ZeroFill(), nvt.ops.LogOp()])
proc.add_cont_preprocess(nvt.ops.Normalize())
proc.add_cat_preprocess(nvt.ops.Categorify(use_frequency=True, freq_threshold=15))
# compute statistics, transform data, export to disk
proc.apply(train_dataset, shuffle=True, output_path="./processed_data/train", num_out_files=len(train_files))
proc.apply(valid_dataset, shuffle=False, output_path="./processed_data/valid", num_out_files=len(valid_files))
Figure 5 shows the relative performance of NVTabular to the original DLRM preprocessing script, and a Spark-optimized ETL process running on a single node cluster. Of note is the percentage of time taken up by training compared to the time taken in ETL. In the baseline cases, the ratio of ETL to training almost exactly matches the common adage that data scientists spend 75% of their time processing the data. With NVTabular, that relationship is flipped.
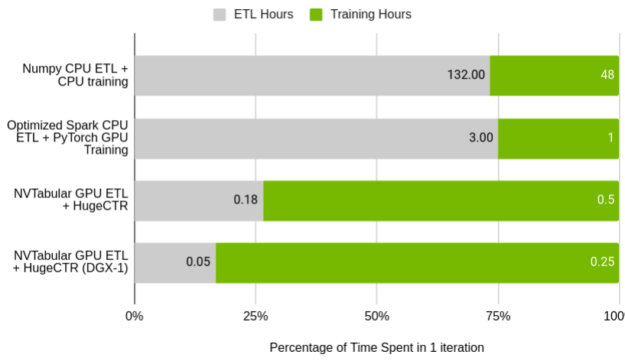
GPU (Tesla V100 32 GB) vs. CPU (AWS r5d.24xl, 96 cores, 768 GB RAM)
The total time taken to process the dataset and train the model on a CPU is over a week using the original script. With significant effort, that can be reduced to four hours using Spark for ETL and training on a GPU. With NVTabular and HugeCTR, which we cover later in this post, you can accelerate iteration time to 40 minutes for a single GPU and 18 minutes on a DGX-1 cluster. In the latter case, the four-billion interaction dataset is processed in only three minutes.
HugeCTR: GPU-accelerated training of large CTR models
HugeCTR is a highly efficient GPU framework designed for recommender model training, which targets both high performance and ease-of-use. It supports both simple deep models and also state-of-the-art hybrid models such as W&D, Deep Cross Network, and DeepFM. We are also working on enabling DLRM with HugeCTR. The model details and hyperparameters can be specified easily in JSON format, allowing for quick selection from a range of common models.
Compared to other generic DL frameworks such as PyTorch and TensorFlow, HugeCTR is designed specifically to accelerate end-to-end training performance of large-scale CTR models. To prevent data loading from becoming a major bottleneck in training, it implements a dedicated data reader which is inherently asynchronous and multi-threaded, so that the data transfer time overlaps with the GPU computation.
The embedding table in HugeCTR is model-parallel and distributed across all the GPUs in a cluster, which consists of multiple nodes and multiple GPUs. The dense component of these models is data-parallel, with one copy on each GPU (Figure 6).
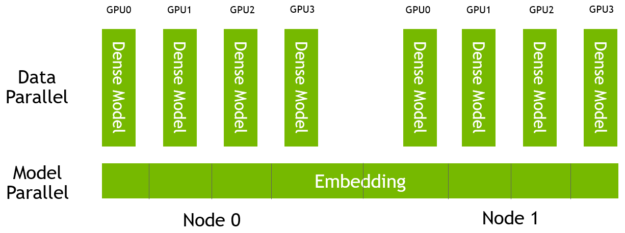
For high-speed and scalable inter– and intra-node communication, HugeCTR uses NCCL. For cases where there are many input features, the HugeCTR embedding table can be segmented into multiple slots. The features that belong to the same slot are converted to the corresponding embedding vectors independently, and then reduced to a single embedding vector. It allows you to efficiently reduce the number of effective features within each slot to a manageable degree.
Figure 7a shows the training performance of a W&D network with HugeCTR on a single V100 GPU on the Criteo Kaggle dataset, compared to TensorFlow on the same GPU and a dual 20-core Intel Xeon CPU E5-2698 v4. HugeCTR achieves a speedup of up to 54X over TensorFlow CPU, and 4X that of TensorFlow GPU. To reproduce the result, the Wide and Deep sample, including the instructions and the JSON model config file, is provided in the HugeCTR repo.
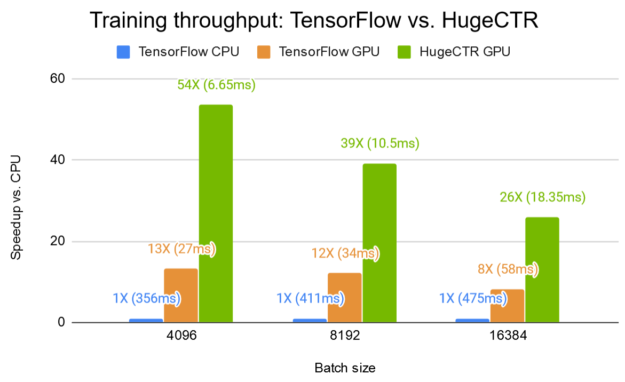
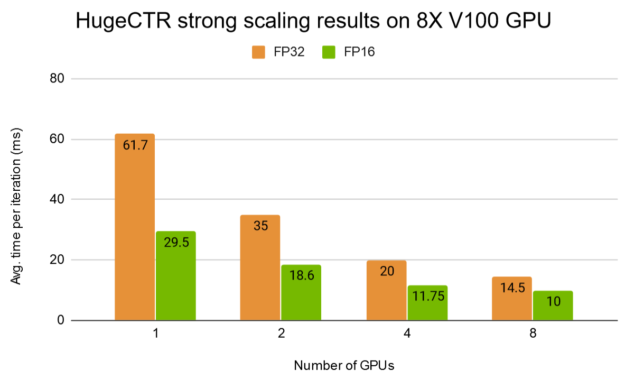
Figure 7b shows the strong scaling results of HugeCTR with a deeper W&D model on a DGX-1 for both the full-precision mode (FP32) and mixed-precision mode (FP16).
NVIDIA recommender system model portfolio
DLRM, Wide and Deep, NCF, and VAE form part of a larger NVIDIA GPU-accelerated DL model portfolio. In this section, we showcase our reference implementation of DLRM.
Like other DL-based approaches, DLRM is designed to make use of both categorical and numerical inputs, which are usually present in recommender system training data. The model architecture is illustrated in Figure 8.
To handle categorical data, embedding layers map each category to a dense representation before being fed into multilayer perceptrons (MLP). Numerical features can be fed directly into an MLP. At the next level, second-order interactions of different features are computed explicitly by taking the dot product between all pairs of embedding vectors and processed dense features. Those pairwise interactions are fed into a top-level MLP to compute the likelihood of interaction between a user and item pair.
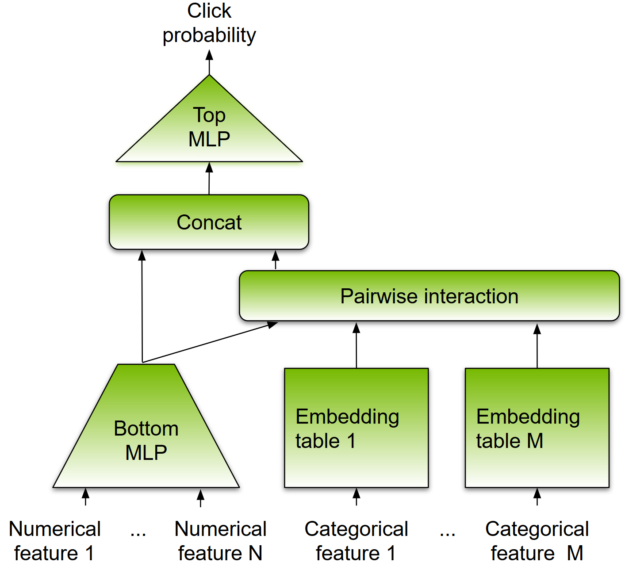
Compared to other DL-based approaches to recommendation, DLRM differs in two ways. First, it computes the feature interaction explicitly while limiting the order of interaction to pairwise interactions. Second, DLRM treats each embedded feature vector (corresponding to categorical features) as a single unit, whereas other methods (such as Deep and Cross) treat each element in the feature vector as a new unit that should yield different cross-terms. These design choices help reduce computational and memory cost while maintaining competitive accuracy.
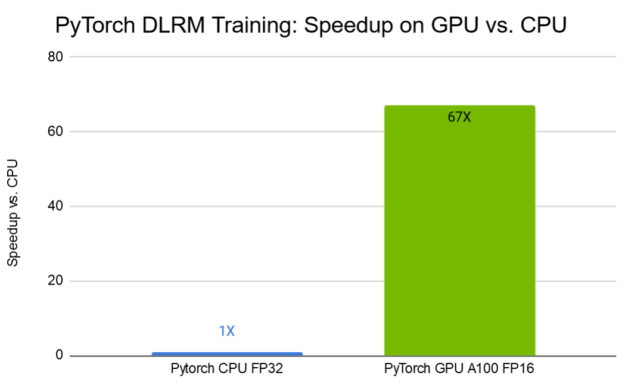
Figure 9 shows DLRM training results on the Criteo Terabyte dataset. On the NVIDIA A100 GPU equipped with the third-generation Tensor Cores technologies, using mixed-precision training, the training time is reduced by a factor of 67x compared to training on CPU.
TensorRT and Triton Server for inference
NVIDIA TensorRT is an SDK for high performance DL inference. It includes a DL inference optimizer and runtime that delivers low latency and high throughput for inference applications. TensorRT can accept trained neural networks from all DL frameworks using a common interface, the open neural network exchange format (ONNX).
TensorRT can automatically optimize the network architecture using operations such as vertical and horizontal layer fusion and using reduced precisions (FP16, INT8) that leverage the high mixed-precision arithmetic throughput of the Tensor Cores on NVIDIA GPUs. TensorRT also automatically selects the best kernel based on the task at hand and the target GPU architecture. For further model-specific optimization, TensorRT is highly programmable and extensible, allowing you to insert your own plugin layers.
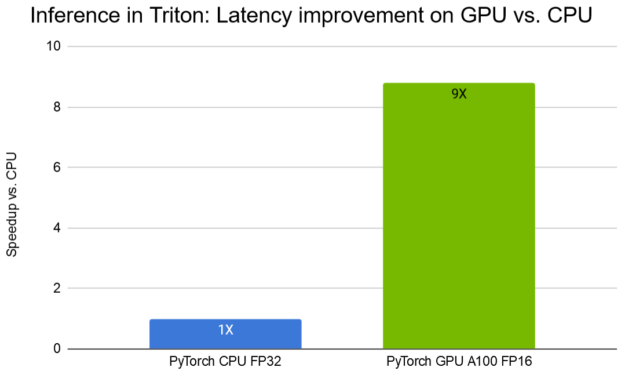
NVIDIA Triton Inference Server provides a cloud-inferencing solution optimized for NVIDIA GPUs. The server provides an inference service via an HTTP or gRPC endpoint, allowing remote clients to request inferencing for any model being managed by the server. Triton Server can serve DL recommender models using several backends, including TensorFlow, PyTorch (TorchScript), ONNX runtime, and TensorRT runtime. With DLRM, we show how to deploy a pretrained PyTorch model with Triton, achieving a 9X reduction in latency on an A100 GPU compared to CPU, as shown in Figure 10.
In the recent post on Accelerating Wide & Deep Recommender Inference on GPUs, the authors detailed optimizations to make a W&D model trained with the TensorFlow estimator API suitable for large-scale production deployment. By implementing a fused embedding lookup kernel to leverage the GPU high-memory bandwidth, running in the Triton Server custom backend, the GPU W&D TensorRT inference pipeline provides up to 18X reduction in latency and 17.6X improvement in throughput compared to an equivalent CPU inference pipeline. All this is deployed using Triton Server to provide production-quality metrics and to ensure production robustness.
Conclusion
The components of NVIDIA Merlin have been made available as open source projects:
This is just the beginning of an exciting journey. We cordially invite you to try out and benefit from our newly developed tools for your recommender system applications. Your issues and feature requests will help guide future development.
