Recommendation systems are widely used today to personalize user experiences and improve customer engagement in various settings like e-commerce, social media, and news feeds. Serving user requests with low latency and high accuracy is critical to sustaining user engagement.
This includes performing high-speed lookups and computations while seamlessly refreshing models with the newest updates, which is especially challenging for large-scale recommenders where the model size exceeds GPU memory.
NVIDIA Merlin HugeCTR, an open-source framework designed to optimize large-scale recommenders on NVIDIA GPUs, recently released a Hierarchical Parameter Server (HPS) architecture to specifically address the needs of industry-grade inference systems. Experiments indicate that this approach enables scalable deployment with low latency on popular benchmarking datasets.
Challenges with large-scale recommendation inference
Large embedding tables: The inputs to typical deep recommendation models can be numerical (user age or item price, for example) or categorical features (user ID or item ID, for example). Unlike numerical features, categorical features must be transformed into numerical vectors to be fed into multilayer perceptron (MLP) layers for dense computation. This is facilitated by an embedding table that learns a mapping (embeddings) from the categorical to the numerical feature space.
Embedding tables are therefore part of the model parameters and can be memory-intensive, reaching up to TB-scale for modern recommender systems. This is well beyond the onboard memory capacity of modern GPUs. Most existing solutions fall back to hosting embedding tables in CPU memory, which does not take advantage of high-bandwidth GPU memory and leads to higher end-to-end latencies.
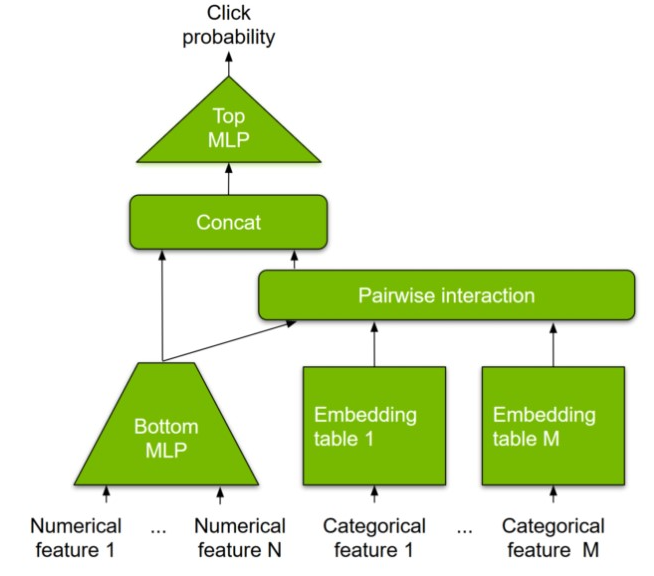
Figure 1 shows the Deep Learning Recommendation Model for Personalization and Recommendation Systems.
Scalability: Driven by user behavior, many customer applications are built to serve peak usages, and need the flexibility to scale out or scale up the AI inference engine based on their expected and actual load.
Framework and platform agnostic: The AI inference engine must be able to serve both deep-learning models (DeepFM, DCN, DLRM, MMOE, DIN, and DIEN, for example) trained by frameworks like TensorFlow or PyTorch, as well as simple machine learning (ML) models. In addition, customers desire hybrid deployment of both multiple different model architectures and multiple instances of a single model. Models must also be deployed across a variety of hardware platforms, from cloud to edge.
Deploying new models and online training updates: Customers want the option to frequently update their models according to market trends and new user data. Model updates should be seamlessly applied to inference deployments.
Fault tolerance and high availability: Customers must maintain the same level of SLA, preferably five nines or higher for mission-critical applications.
The following section provides more details about how NVIDIA Merlin HugeCTR addresses these challenges using HPS to enable large-scale inference for recommendations.
Hierarchical Parameter Server overview
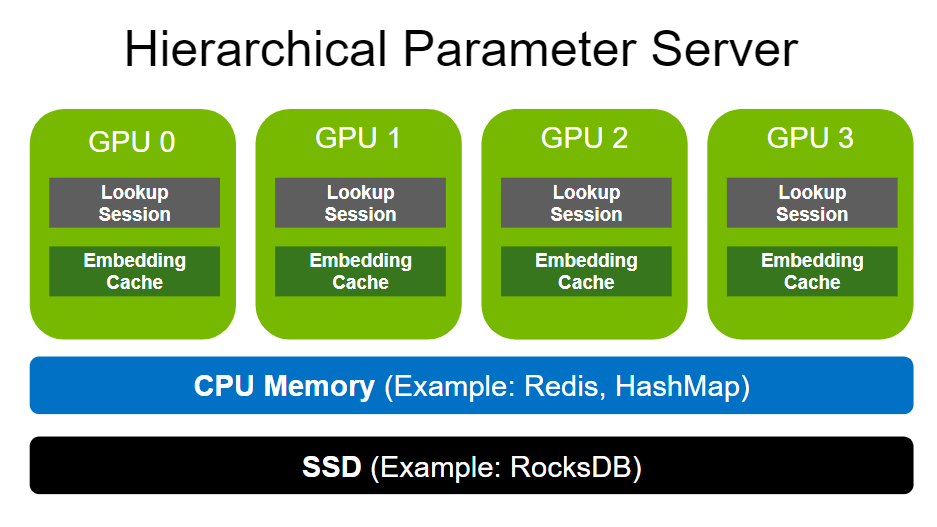
The Hierarchical Parameter Server enables the deployment of large recommendation inference workloads using a multi-level adaptive storage solution. To store large-scale embeddings, it uses GPU memory as the first-level cache, CPU memory as the second-level cache (such as HashMap for local deployment and Redis for distributed), and SSD for extended storage capacity (such as RocksDB).
Both CPU memory and SSD can be flexibly configured based on your needs. The size of dense layers (MLPs) is much smaller in comparison to embeddings. Therefore, dense layers are replicated across the various GPU workers in a data-parallel fashion.
GPU embedding cache
The memory bandwidth of GPUs is an order of magnitude higher than that of most CPUs. For example, NVIDIA A100-80 GB provides more than 2 TB/s HBM2 bandwidth. The GPU embedding cache leverages such high memory bandwidth by moving the memory-intensive embedding lookups into the GPU, closer to where the compute happens.
To design a system that efficiently leverages the advantages offered by modern GPUs, it is important to take note of one key observation: with real-world recommendation datasets, a few feature categories typically occur much more frequently than others. For example, in the Criteo 1 TB Click Logs dataset, a popular benchmarking dataset also used in MLPerf, 305K categories out of a total 188M (representing just 0.16%) are referenced by 95.9% of all samples.
This implies that some embeddings are accessed far more frequently than others. Embedding key accesses roughly follow a power-law distribution. Consequently, caching these most frequently accessed parameters in GPU memory enables recommender systems to take advantage of high GPU memory bandwidth. Individual embedding lookups are independent, which makes GPUs the ideal platform for vector lookup processing, with their ability to run thousands of threads concurrently.
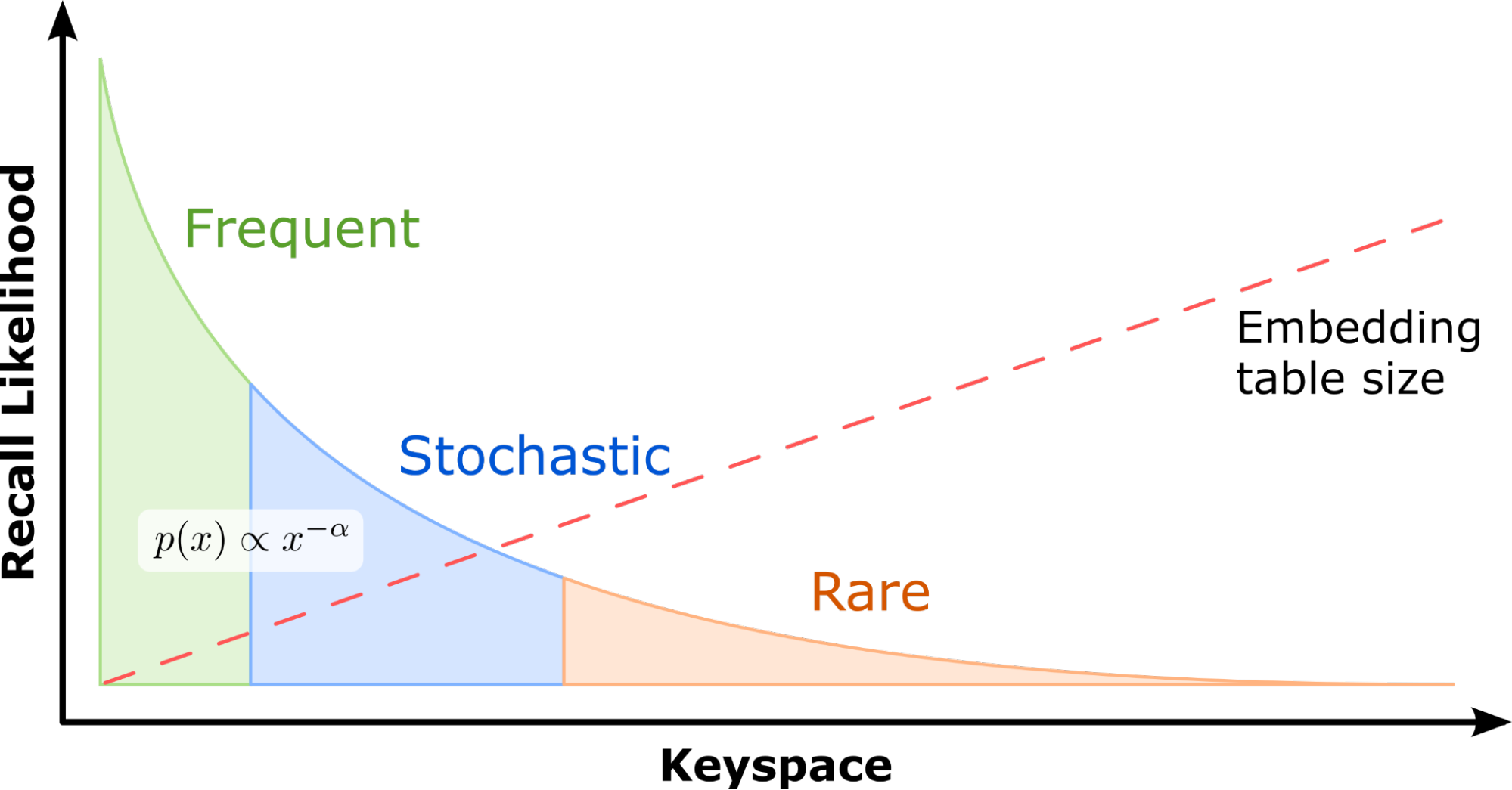
These properties have inspired the design of the HPS GPU embedding cache that retains the hot embeddings in GPU memory, improving lookup performance by reducing additional or repetitive parameter movement across a slower CPU-GPU bus. It is backed by secondary storage that keeps a full copy of all the embedding tables. This is explored more fully later in this post. A unique GPU embedding cache exists for each embedding table associated with each model hosted on a GPU.
Embedding key insertion mechanism
When looked-up embedding keys are missing in the GPU cache during inference, a key insertion is triggered to fetch the related data from lower levels of the hierarchy. The HPS implements both synchronous and asynchronous key insertion mechanisms, and a user-defined hit rate threshold to choose between the two options to balance accuracy and latency.
- Synchronous insertion: If the actual hit rate is lower than the hit rate threshold, inference requests are blocked while waiting for the missing key to be inserted in the GPU cache. This typically occurs when the model is freshly loaded, during warm-up, or after a significant model update has been conducted.
- Asynchronous insertion: If the actual hit rate is higher than the hit rate threshold, a preconfigured default vector is returned immediately to allow the query pipeline to continue execution without delay. The lazy insertion itself occurs in the background. This is used when a desirable accuracy has been achieved and the main focus is maintaining low latency. In practical industry scenarios, inference even with the full model cached may still have missing features because new items and users may emerge in inference that were never in the training dataset.
GPU embedding cache performance
Figure 4 shows the measured inference latency versus hit rate with the Criteo 1 TB Click Logs dataset and the 90 GB Deep Learning Recommendation Model for Personalization and Recommendation Systems (DLRM) model on an NVIDIA T4 (16 GB memory), A30 (24 GB memory), and A100 GPU (80 GB memory), caching 10% of the model size. The hit rate threshold is set to 1.0, so that all key insertions are synchronous. Measurements are taken at the stable stage.
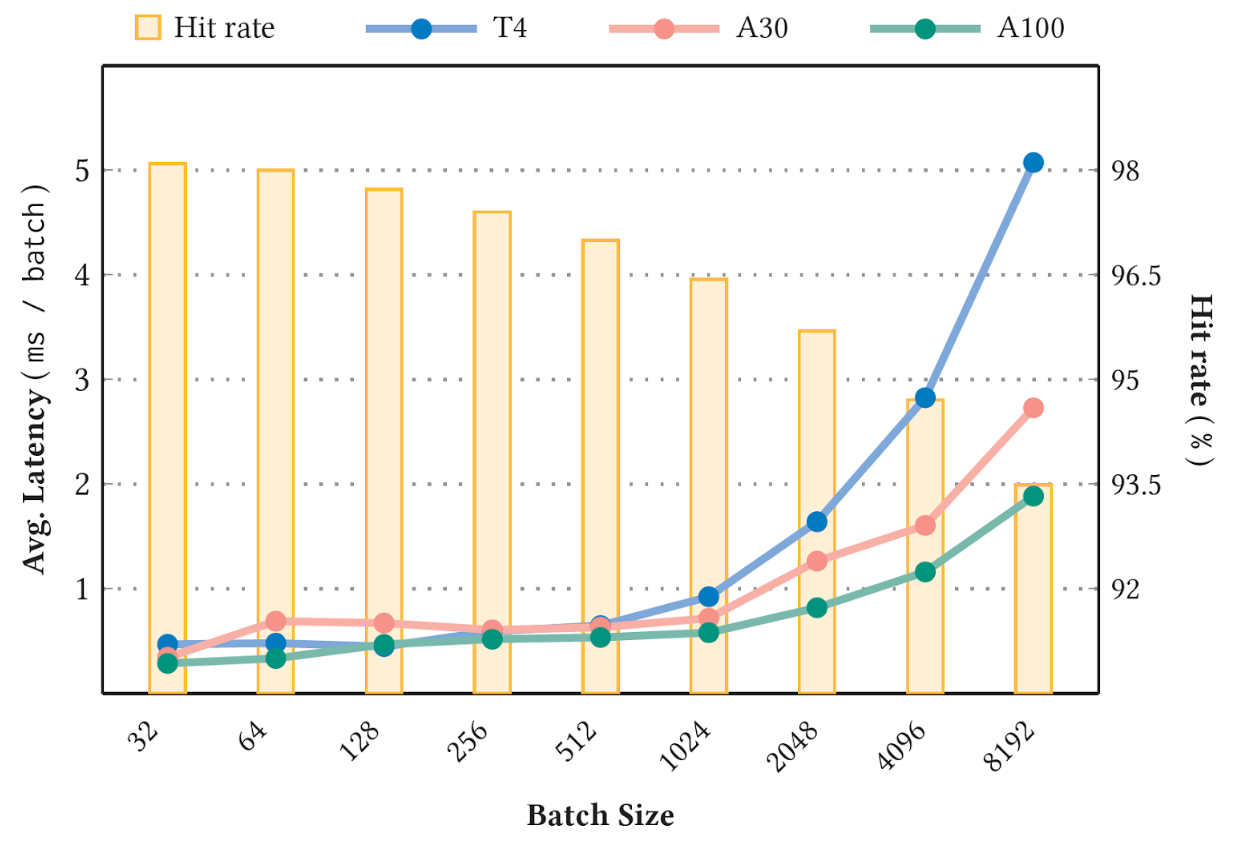
As can be expected, a higher stable cache hit rate (Figure 4 bar chart) corresponds to a lower average latency (Figure 4 line chart). Moreover, a larger batch size also witnesses lower hit rate and higher latency due to the increasing likelihood of keys missing. For more information, see A GPU-Specialized Inference Parameter Server for Large-Scale Deep Recommendation Models.
HPS includes two additional layers to support models that scale beyond GPU memory capacity: the CPU memory and SSD. These layers are highly configurable to support various backend implementations.
CPU cache
The second-level storage is the CPU cache, accessed through the CPU-GPU bus, and acts as the extended storage for the GPU embedding cache at a lower cost. If an embedding key is missing in the GPU embedding cache, HPS next turns to querying the CPU cache.
- If the key is found (cache hit), it returns the result and notes the access time. These last-accessed timestamps are used for key eviction later.
- If the key is missing, HPS turns to the next layer to fetch the embedding while also scheduling the insertion of the missing embedding vector into the CPU cache.
The CPU cache layer supports various database backends. HugeCTR HPS provides volatile database examples with a hash map-based, local CPU memory database implementation, and a Redis cluster-based backend that uses distributed cluster instances for scalable deployment.
SSD
The lowest level of the cache hierarchy stores an entire copy of each embedding table on either SSDs, hard disks, or a network storage volume at even lower cost. It is particularly effective with datasets that exhibit an extreme long-tail distribution (a large number of categories, many of which are not referenced often), where maintaining a high accuracy is critical for the task at hand. The HugeCTR HPS reference configuration maps embedding tables to column groups in a RocksDB database on a local SSD.
The entire model is persisted in each inference node by design. Such resource isolation strategies enhance system availability. The model parameters and inference service can be recovered even if just one node is alive after a catastrophic event.
Incremental training update
Recommendation models have two modes of training: offline and online. Online training deploys fresh model updates into real-time production and is critical for recommendation effectiveness. HPS employs a seamless update mechanism through Apache Kafka-based message buffers to connect training and inference nodes (Figure 5).
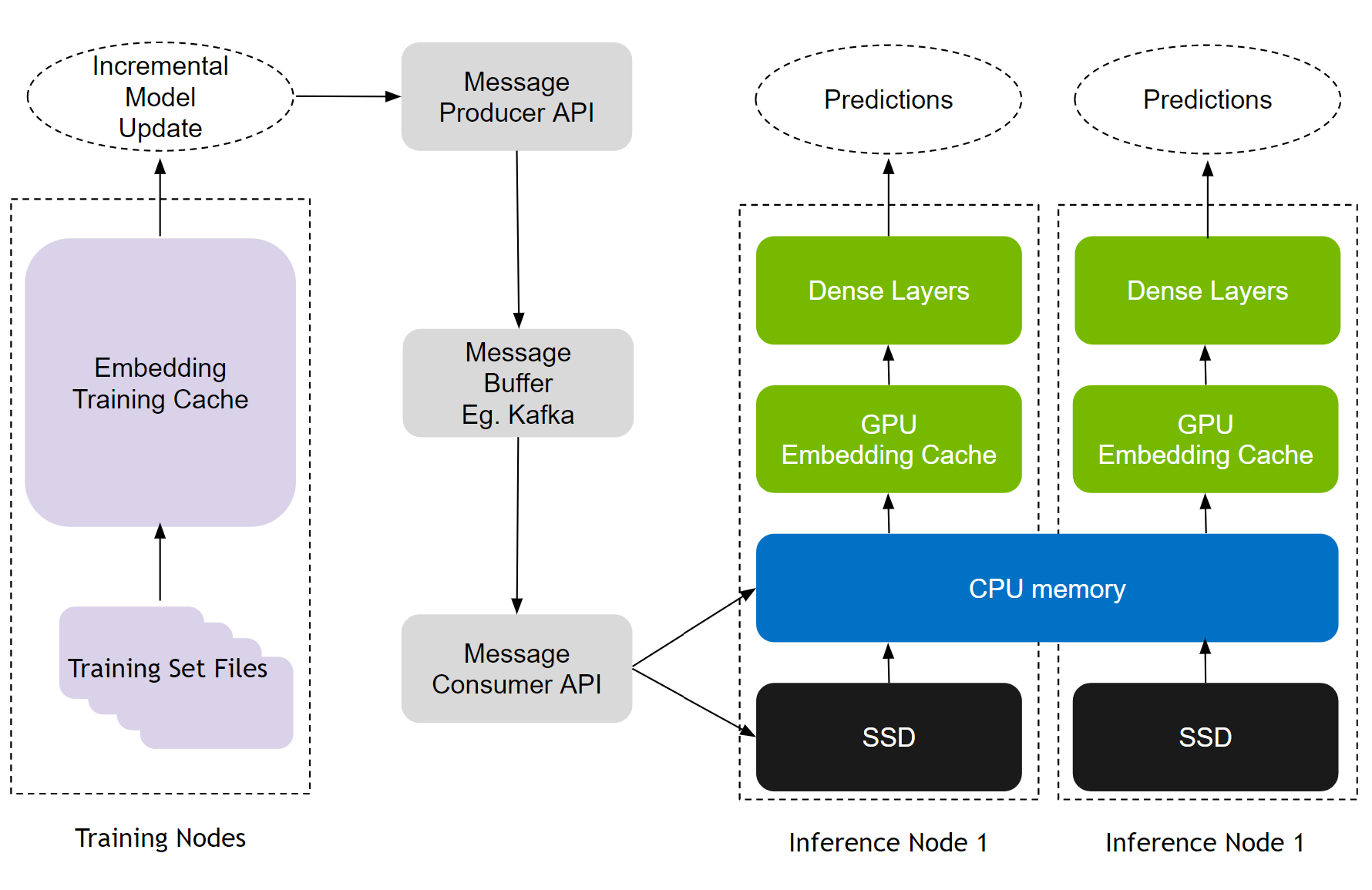
The update mechanism aids MLOps workflows, enabling both online and frequent as well as offline and retraining updates with no downtime. It also imparts fault tolerance by design, as training updates continue to queue up in the Kafka message buffer even if inference servers are down. All these capabilities are available to developers through convenient and easy-to-use Python APIs.
HPS performance benchmark
To demonstrate the benefits of HugeCTR HPS, we evaluated its end-to-end inference performance on the DLRM model and Criteo 1 TB Click Logs dataset, and compared it with scenarios where just the dense layer computations run on a GPU and a CPU-only solution.
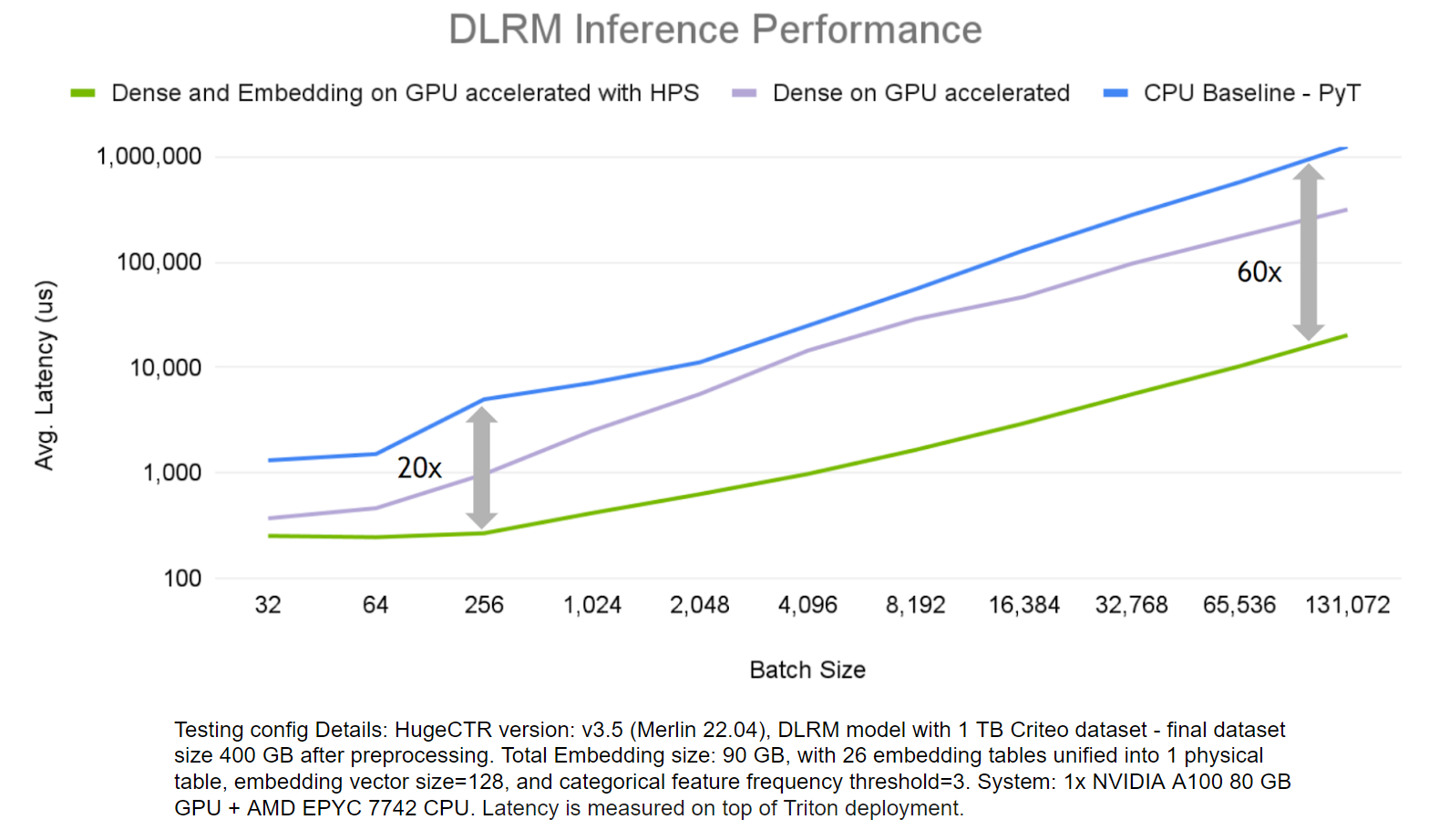
The HPS solution accelerates both embedding and dense layers far outperforms the CPU-only solution, up to 60x on larger batch sizes.
How HPS differs from a CPU PS plus GPU worker solution
You may be familiar with CPU parameter server (PS) plus GPU worker solutions. Table 1 shows how the HPS differs from most PS plus worker solutions.
| HPS | CPU PS + GPU Worker | |
| Pipeline focus | Inference | Training and Inference |
| Embedding lookup GPU accelerated | Yes | No |
| GPU use | Most frequently accessed embedding tables Dense parameters from MLP | Dense parameters from MLP |
| Inter GPU Communication | None | None |
| CPU use | Less frequently accessed embeddings | All embedding tables are sharded across CPUs |
Summary
This post presents the Merlin HugeCTR HPS with GPU embedding cache as a tool to accelerate inference with large-scale embeddings on NVIDIA GPUs. HPS is available through convenient and easy-to-use configurations and includes examples to get you started.
For more details, see the following resources:
