
NVIDIA Merlin is an open beta application framework and ecosystem that enables the end-to-end development of recommender systems, from data preprocessing to model training and inference, all accelerated on NVIDIA GPU. We announced Merlin in a previous post and have been continuously making updates to the open beta.
In this post, we detail the new features added to the open beta NVIDIA Merlin HugeCTR. New features include the Deep Learning Recommendation Model (DLRM), a state-of-the-art model that is a part of the MLPerf training and inference benchmarks. DLRM is now part of the HugeCTR model repository, with multi-GPU and multi-node training support. The Merlin open beta inclusion of DLRM in this latest release reaffirms the NVIDIA commitment to accelerating the workflow of researchers, data scientists, and machine learning engineers and democratizing the development of large-scale, deep learning recommender systems.
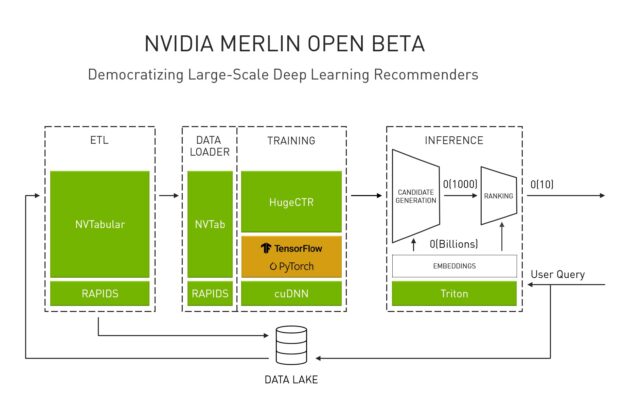
Figure 1. NVIDIA Merlin Recommender System Framework.
Merlin HugeCTR
After the last update, we enriched Merlin HugeCTR with a variety of features to ease optimization and interoperability for researchers, data scientists, and machine learning engineers seeking to accelerate and scale their workflows. We enabled the training of DLRM with its highly optimized training pipeline, which is the same as that used in the NVIDIA MLPerf record-setting submission. HugeCTR now also supports the NVIDIA Ampere architecture, designed for high-performance elastic data centers. This provides a performance enhancement when using the Wide & Deep (W&D) model with HugeCTR across different DGX platforms. We added two new dataset formats and introduced the interoperability with NVTabular, while cultivating other features to enhance usability.
HugeCTR now offers DLRM as part of the HugeCTR model repository, beside other state-of-the-art models, namely DeepFM, Deep & Cross Network (DCN), and W&D Learning. HugeCTR on a NVIDIA DGX A100 system proved to be the fastest commercially available solution for training DLRM. On the Criteo Terabyte Click Logs dataset used in the MLPerf v0.7 training benchmark, this was done in just 3.33 minutes, as shown in Figure 2.
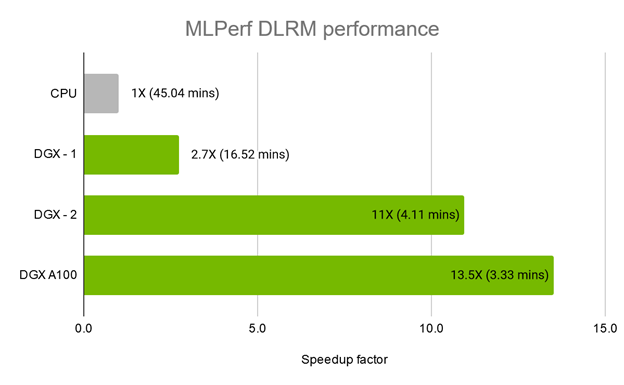
Reproduce the MLPerf DLRM training sample
To reproduce the MLPerf DLRM training performance with HugeCTR, follow the NVIDIA/HugeCTR DLRM sample with the following steps.
Download the Criteo Terabyte Click Logs dataset. Unzip them as day_0, day_1, …, day_23.
Build HugeCTR with the instructions at README.md.
Preprocess the datasets. This operation generates two binary input files: train.bin (671.2 GB) and test.bin (14.3 GB).
# Usage: ./dlrm_raw input_dir output_dir --train {days for training} --test {days for testing}
cp ../../build/bin/dlrm_raw ./
./dlrm_raw ./ ./ \
--train 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22 \
--test 23
Run HugeCTR training using either of the four provided JSON configure files:
./huge_ctr --train ./terabyte_fp16_64k.json
In addition, we offer a tutorial Jupyter notebook, which demonstrates how to train a DLRM model on the movie-lens 20m data set, then use the movie embeddings to answer movie similarity queries. This example is designed to help you get acquainted with the HugeCTR workflow, from data preprocessing to training and inference.
DLRM: New layers
To support DLRM within HugeCTR, we added the following new layers, which can also be useful for other custom models as well:
- Interaction layer: This is a layer designed to explicitly capture second-order interactions between features. HugeCTR supports both FP32 and FP16 data types for this layer, while highly optimized for FP16. In mixed-precision mode, all the operations are fused into a single CUDA kernel for both the forward and backward passes.
- Fused fully connected layer: To further improve memory bandwidth utilization, HugeCTR provides a new layer in mixed-precision mode, where the bias addition and ReLU activation functions are computed inside a single kernel. This is a common layer that is applicable to various models.
- NVSwitch-aware embedding layer: Originally, the forward pass of the embedding layer consisted of three phases: the embedding lookup kernel, all-to-all inter-GPU communication, and data reordering. To exploit the full GPU connectivity of the NVSwitch on servers such as the DGX-2 and DGX A100, we fuse the aforementioned three steps into one CUDA kernel. We applied the same approach to the embedding backward pass. It leads to significant performance improvement by halving both read and write traffic. The optimized embedding layer is available in the name of
LocalizedSlotSparseEmbeddingOneHotin the JSON config file.
For more information about how to use these new layers for your model, see the DLRM model config file.
Performance enhancement with Ampere
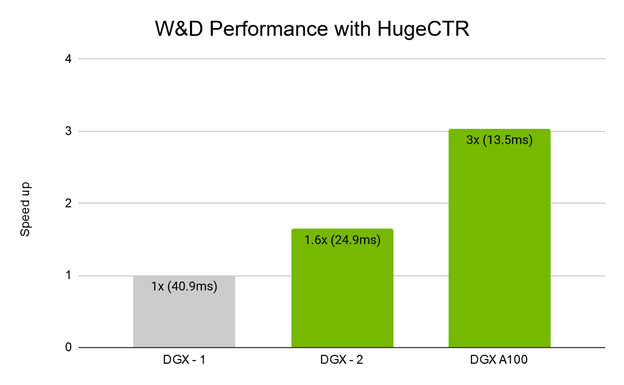
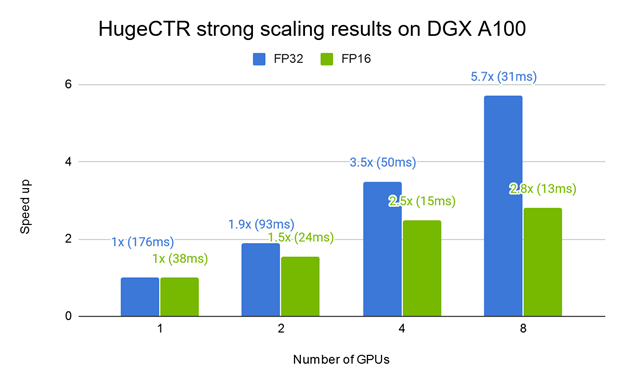
Figure 3 shows the training performance of a W&D model with HugeCTR across different DGX platforms. With 16xV100 GPUs and NVSwitch, the DGX-2 shows a decent speedup over the DGX-1 with 8xV100 GPUs. The DGX A100, with eight recently announced NVIDIA A100 GPUs, achieves 3X speedup over the DGX-1 and 1.8X over the DGX-2. Figure 4 shows the strong scaling results of training W&D on the DGX-A100.
Two new data formats
Merlin HugeCTR supports two new dataset formats in its data loading stage. One is the “raw” format, which simplifies one-hot data reading. We provide a DLRM sample that uses this format together with a GPU-accelerated, preprocessing tool for the Criteo 1TB datasets.
The other format is Parquet. This allows HugeCTR to consume data preprocessed by NVTabular. Parquet is a column-oriented data format of the Apache Hadoop ecosystem, which is free and open source. To show how to use this format with HugeCTR, we added the new config files to the DeepFM, DCN, and W&D examples. We also offer a new data preprocessing script using NVTabular for these examples.
Full FP16 pipeline
HugeCTR extends the FP16 type support from only fully connected layers to other layers, including interaction, embedding, and loss computation. It allows HugeCTR to fully use the Tensor Cores in the Volta, Turing, and Ampere architectures, while effectively saving memory bandwidth and memory capacity. To turn on the mixed-precision mode, specify the mixed_precision option in the JSON config file.
Additional features to accelerate workflows
For your convenience, we added a variety of new features to HugeCTR:
- GEMM algorithm search: HugeCTR runs an exhaustive algorithm search for each fully connected layer to find the best algorithm for a given input shape and system. You can turn it off using JSON.
- Learning rate scheduling: In addition to setting a base learning rate, you can set the warmup period and use the learning rate decay. The DLRM sample shows how to specify them for an optimizer.
- AUC as a new evaluation metric: HugeCTR used to support
AverageLossas its only evaluation metric. We have now added a GPU- accelerated version ofAUCas one of the supported metrics. You can also set its threshold to stop the training when yourAUCvalue reaches the value. - Weight initialization: Each trainable layer allows you to change its weight initialization method. For instance, for a fully connected layer, you may want to initialize its weights with
XavierUniformand biases withZeros. We currently support four initialization methods:Uniform,XavierNormal,XavierUniform, andZeros. - Use of RAPIDS cuML primitives: HugeCTR has been embracing the use of cuML primitives, which are highly optimized for machine learning algorithms, so that we can exploit their high performance.
- Docker support: We recommend using HugeCTR with our Docker container, following the instructions on the Quick Start guide.
For more information, see the release notes.
Try Merlin Training
The latest release of Merlin Training provides data scientists, machine learning engineers, and researchers with additional support for developing large-scale, deep learning recommender systems. This key feature update includes enhanced support for the DLRM, a model that enables you to work more efficiently with production-scale data. DLRM support also includes multi-GPU training for HugeCTR implementation that results in further workflow acceleration. HugeCTR on NVIDIA A100 offers a huge speedup over CPU training: 3.33 minutes for HugeCTR on a NVIDIA DGX A100 system, compared to 45 minutes on a 16 next-gen Xeon CPU cluster. To realize the 10X improvements in throughput, try Merlin Training today.
All NVIDIA Merlin components are available as open-source projects. However, a more convenient way to make use of these components is by using Merlin NGC containers. Containers allow you to package your software application, libraries, dependencies, run time compilers in a self-contained environment. This way, the application environment is both portable, consistent, reproducible and agnostic to the underlying host system software configuration. Merlin components are available as a set of containers on NGC, including HugeCTR.
To learn more about Merlin ETL, see Announcing the NVIDIA NVTabular Open Beta with Multi-GPU Support and New Data Loaders.