Data scientists, researchers, and machine learning engineers seek to provide relevant and impactful insights. With the increasing availability of large datasets, industry practitioners building effective recommenders are evaluating deep learning methods versus the traditional content-based, neighborhood, and latent factor methods.
This consideration is often driven by the need for better predictions coupled with the desire to avoid performance issues that slow down the total training time by orders of magnitude.
Even Oldridge will be discussing these considerations and more on August 24, 2020 during his upcoming session at KDD’s International Workshop on Industrial Recommendation Systems on Merlin, an open-source Graphics Processing Unit (GPU) accelerated recommendation framework that scales to datasets and user/item combinations of arbitrary size.
Recommenders: Challenges to Consider
Key challenges with deploying commercial recommenders appear in training and deploying to production. Challenges with training large-scale recommenders include effectively handling: the sheer size of the dataset (terabytes or more), complex preprocessing and feature engineering pipelines, inefficient data loading, extensive repeated experimentation, and huge embedded tables. Challenges in deploying large-scale recommenders in production include whether the server can truly support real-time inference, monitoring, and retraining.
Given these large-scale challenges, big companies with large engineering teams are investing in deep learning recommenders as the benefit of deploying deep learning recommenders is significant enough, given the magnitude of scale, to warrant the effort. Yet, there are small and mid-sized companies that would like better prediction on large thorny datasets and do not have access to significantly large engineering teams.
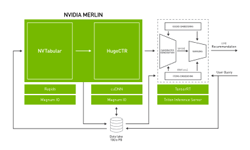
Merlin: A GPU Accelerated Recommender Framework
Merlin provides an end-to-end recommender on GPU framework that enables industries to leverage deep learning recommender methods over traditional commercial methods. Its focus is on ease of use for each component library, simple interoperability between components, and acceleration on the GPU, scaling easily to multi-GPU and multi-Node solutions when required.
Component libraries are also interoperable with other common frameworks and tools in the deep learning ecosystem for maximum flexibility in production settings where existing solutions require integration, allowing users of the framework to pick and choose the components that work best for them.
For more insight on Merlin, check out Even Oldridge’s International Workshop on Industrial Recommendation Systems session on August 24.