
高性能计算(HPC)已成为科学发现的基本工具。
无论是发现新的拯救生命的药物,对抗气候变化,还是创建精确的世界模拟,这些解决方案都需要巨大且快速增长的处理能力。它们越来越超出传统计算方法的范围。
这就是为什么业界接受 NVIDIA GPU加速计算的原因。与人工智能相结合,它为科学进步带来了性能上百万倍的飞跃。如今,2700个应用程序可以从 NVIDIA GPU 的加速中受益,而且这个数字在不断增长的300万开发者社区的支持下继续上升。
HPC 应用程序性能改进
要在整个 HPC 应用程序范围内实现数倍的加速,需要在堆栈的各个级别进行不懈的创新。这从芯片和系统开始,一直到应用程序框架本身。
NVIDIA 平台每年都在继续提供显著的性能改进,在体系结构和整个 NVIDIA 软件堆栈方面都取得了不懈的进步。与六年前发布的 P100 相比, H100 Tensor Core GPU 预计性能将提高 26 倍,比摩尔定律快 3 倍多。

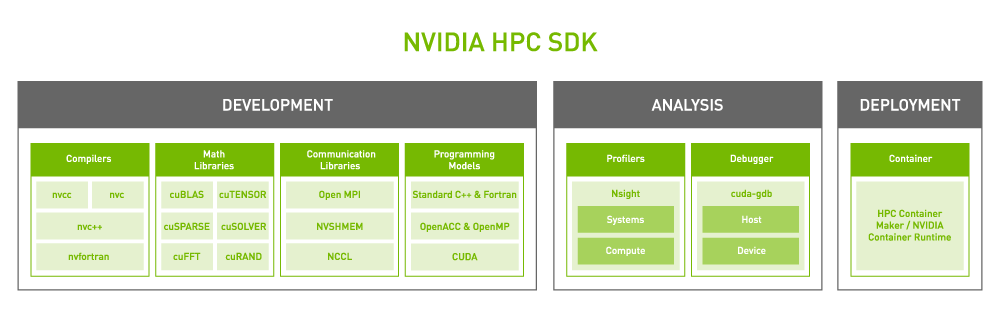
NVIDIA 平台的核心是功能丰富且高性能的软件堆栈。为了促进 GPU 在最广泛的 HPC 应用中的加速,该平台包括 NVIDIA HPC SDK 。 SDK 提供了无与伦比的开发人员灵活性,支持使用标准语言、指令和 CUDA 创建和移植 GPU 加速的应用程序。
NVIDIA HPC SDK 的强大功能在于一整套高度优化的 GPU 加速数学库 ,使您能够充分发挥 NVIDIA GPU 的性能潜力。为了获得最佳的多 GPU 和多节点性能, NVIDIA HPC SDK 还提供了功能强大的通信库:
- NVSHMEM 为跨越多个 GPU 内存的数据创建全局地址空间。
- NVIDIA 集体通信库( NCCL ) 优化了 GPU 之间的通信。
总之,该平台提供了最高的性能和灵活性,以支持不断增长的 GPU 加速 HPC 应用程序。
HPC 性能和能效
为了展示 NVIDIA 全栈创新如何转化为 accelerated HPC 的最高性能,我们比较了 HPE 服务器与四个 NVIDIA GPU 服务器的性能,以及基于其他供应商同等数量加速器模块的类似配置服务器的性能。
我们使用各种数据集测试了一组五个广泛使用的 HPC 应用程序。虽然 NVIDIA 平台可以加速 2700 个跨行业的应用程序,但我们在比较中可以使用的应用程序受到其他供应商加速器可用软件和应用程序版本选择的限制。
对于除分子动力学模拟软件 NAMD 以外的所有工作负载,我们的结果是使用多个数据集的结果几何平均值计算的,以最小化异常值的影响,并代表客户体验。
我们还在多 GPU 和单 GPU 场景中测试了这些应用程序。
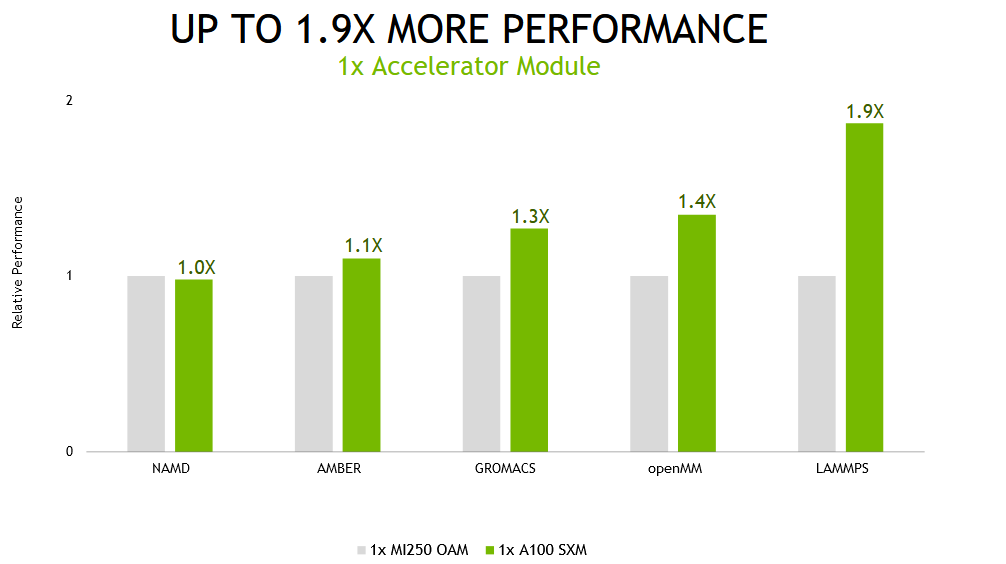
在多 GPU 场景中,测试系统中的所有加速器都用于运行单个模拟,基于 A100 Tensor Core GPU 的服务器提供的性能比备选方案高出 2.1 倍。

在计算性能不断进步的推动下,分子动力学领域正朝着在更长的模拟时间内模拟更大的原子系统的方向发展。这些进展使研究人员能够模拟越来越多的生化机制,如光合电子传递和视觉信号转导。这些和其他过程长期以来一直是科学辩论的主题,因为它们已经超出了模拟的范围,模拟是验证的主要工具。这是由于完成模拟所需的时间过长。
然而,我们认识到,并非所有这些应用程序的用户在每次模拟时都使用多个 GPU 来运行它们。为了获得最佳吞吐量,最佳执行方法通常是为每个模拟分配一个 GPU 。
当在 NVIDIA A100上的单个加速器模块上运行这些相同的应用程序时,基于 NVIDIA A100的系统的性能提高了1.9倍。
能源成本占数据中心和超级计算中心总体拥有成本( TCO )的很大一部分,这突出了节能计算平台的重要性。我们的测试表明, NVIDIA 平台提供的每瓦吞吐量比其他产品高出 2.8 倍。

显示 A100 与 MI250 的效率比– NVIDIA 的效率越高越好。对每个应用程序的多个数据集(不同)进行 Geomean 。效率是指 GPU 使用 NVIDIA SMI 和 ROCm 中的等效功能测量的性能/功耗(瓦特)|
AMD MI250 在千兆字节 M262-HD5-00 上测量,具有( 2 )个 AMD EPYC 7763 和 4 个 AMD Instinct ™ MI250 OAM ( 128 GB HBM2e ) 500W GPU 带 AMD Infinity 结构™ 技术 NVIDIA 在 ProLiant XL645d Gen10 Plus 上运行,使用双 EPYC 7713 CPU 和 4x A100 ( 80 GB ) SXM4
LAMMPS develop \ u db00b49 ( AMD ) develop \ u 2a35ec2 ( NVIDIA )数据集 ReaxFF / c 、 Tersoff 、 Leonard Jones 、 SNAP | NAMD 3.0alpha9 数据集 STMV \ u NVE | OpenMM 7.7.0 数据集的集成运行: amber20 STMV 、 amber20 Cellular 、 apoa1pme 、 pme |
GROMACS 2021.1 ( AMD ) 2022 ( NVIDIA )数据集 ADH-Dodec (氢键), STMV (氢键)|琥珀色 20 。 xx \ U rocm \ U mr \ U 202108 ( AMD )和 20.12-AT \ U 21.12 ( NVIDIA )数据集 Cellular \ u NVE 、 STMV \ u NVE | 1x MI250 有 2x GCD
NVIDIA A100 GPU 卓越的性能和电源效率是多年不懈的软硬件协同优化的结果,以最大限度地提高应用程序性能和效率。有关 NVIDIA 安培体系结构的更多信息,请参阅 NVIDIA A100 GPU 核心张量 白皮书。
A100 还以单处理器的形式出现在操作系统中,只需要启动一个 MPI 列即可充分利用其性能。而且,由于节点中所有 GPU 之间的 600 GB / s NVLink 连接 , A100 在规模上提供了优异的性能。
AI 和 HPC 融合
正如加速计算为建模和仿真应用带来了数倍的加速一样, AI 和 HPC 的结合将带来性能的下一步功能提升,开启下一波科学发现。
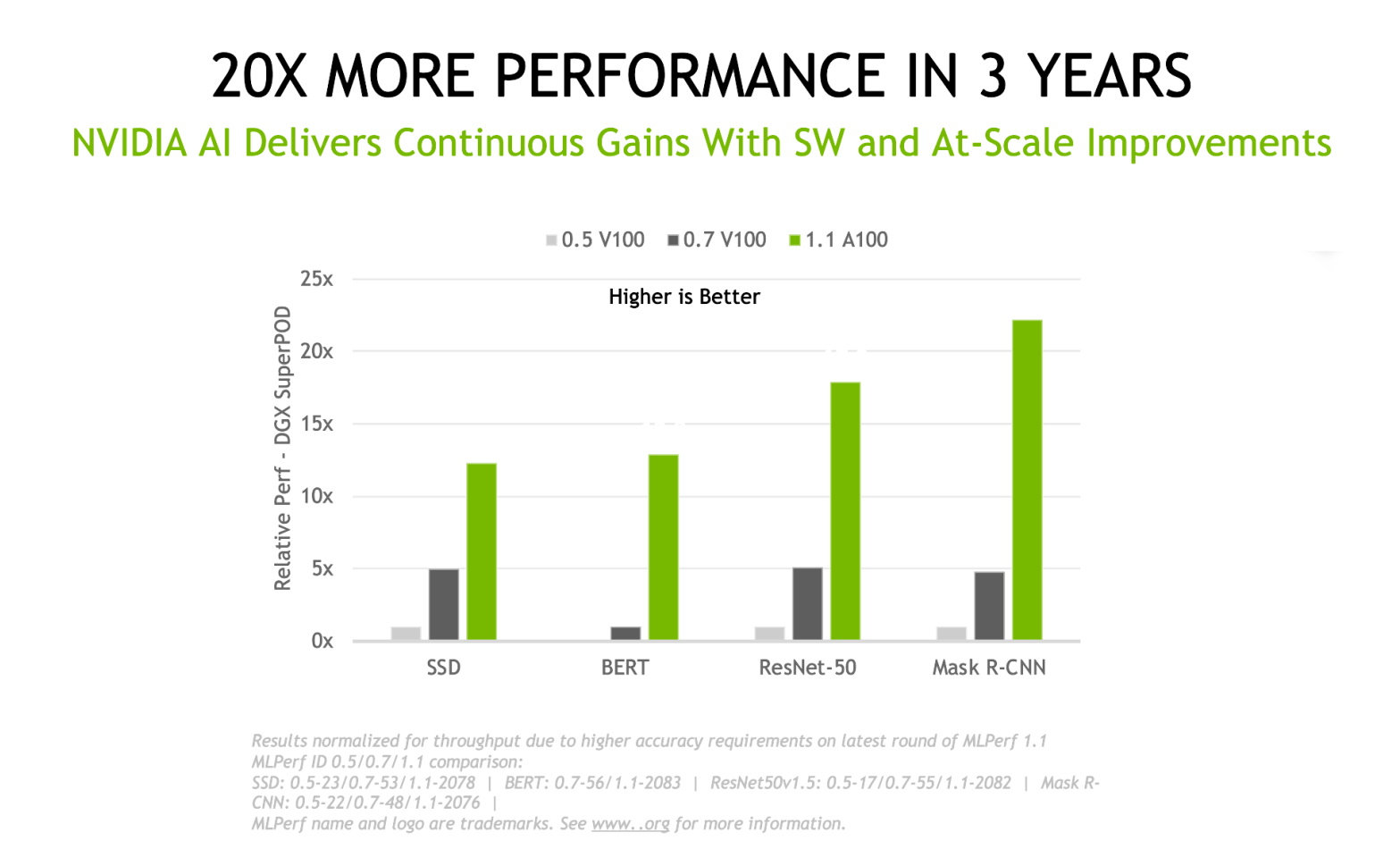
在我们提交的第一份 MLPerf 培训报告和最近的结果之间的三年里, NVIDIA 平台已经在这一行业标准、同行评审的基准套件上交付了 20 倍更深入的学习培训绩效 。这些收益来自芯片、软件和大规模改进的结合。
科学家和研究人员已经在利用人工智能的力量显著提高性能,涡轮增压科学发现:
- 启用 105缩短 识别引力波 所需的时间。
- 为 在含有 10 亿多个原子的呼吸液滴中模拟δ SARS-CoV-2 病毒 提供 1000 倍的加速。
- 加快发展清洁聚变能源 .
- 创建预测性数字孪生 用于余热锅炉(HRSG)装置。
世界各地的超级计算中心正在继续采用加速 AI 超级计算机。
- Argonne Leadership Computing Facility ( ALCF )的 Polaris supercomputer 、 NERSC 的 Perlmutter 和 CINECA 的 Leonardo 均由 A100 Tensor Core GPU 供电。
- 基于我们即将推出的 Grace Hopper 超级芯片 的 Alps 超级计算机将于 2023 年上线。
- 计划于 2023 年交付的即将推出的 Venado system at Los Alamos National Laboratory 将包括 Grace Hopper 超级芯片以及 Grace GPU 超级芯片节点。
有关最新性能数据的更多信息,请参阅 HPC 应用程序性能 。




