近年来,大型语言模型( LLM )的数量激增,它们超越了传统的语言任务,扩展到生成式人工智能这包括像 ChatGPT 和 Stable Diffusion 这样的模型。随着这种对生成人工智能的关注不断增长,人们越来越需要一种现代机器学习( ML )基础设施,使日常从业者能够访问可扩展性。
本文介绍了两个开源框架,Alpa.ai和Ray.io,共同努力实现训练 1750 亿参数所需的规模JAX transformer具有流水线并行性的模型。我们详细探讨了这两个集成框架,以及它们的组合架构、对开发人员友好的 API 、可伸缩性和性能。
Alpa 和 Ray 的核心都是为了提高开发人员的速度和有效地扩展模型。 Alpa 框架的流水线并行功能可以轻松地在多个 GPU 上并行化大型模型的计算,并减轻开发人员的认知负担。 Ray 提供了一个分布式计算框架,可以简化跨多台机器的资源扩展和管理。
当 Alpa 和 Ray 一起使用时,它们提供了一个可扩展且高效的解决方案,可以在大型 GPU 集群中训练 LLM 。通过这种集成,基准测试显示了以下好处:
- 对于 1750 亿参数规模的 LLM , Alpa on Ray 可以扩展到 1000 GPU 以上。
- 所有 LLM 并行化和分区都是通过一行装饰器自动执行的。
大型语言模型概述
大型语言模型( LLM )主要基于 transformer 体系结构。 2017 年的开创性论文,Attention Is All You Need,刺激了基于 transformer 的模型的无数变化,在数十亿的训练参数中呈指数级增长。这些变化,例如BERT,RoBERTa,GPT-2 and GPT-3和ChatGPT– 都是在变压器上设计的,变压器包含了多头注意力和编码器/解码器块的核心架构组件。
由于学术界和各行业的深入研究,在短时间内迅速发布了训练参数为数十亿的模型。由最近的Diffusion和DALL-E语言模型, LLM 引入了生成人工智能的概念:向模型提供不同的输入模式文本、视频、音频和图像,以分析、合成和生成新内容,作为简单的序列到序列任务。
生成人工智能是自然语言处理( NLP )的下一个时代。要了解更多信息,请参阅What Is Generative AI?和What’s the Big Deal with Generative AI? Is it the Future or the Present?
从零开始训练这些十亿参数 LLM 模型或使用新数据对其进行微调,都带来了独特的挑战。训练和评估 LLM 模型需要巨大的分布式计算能力、基于加速的硬件和内存集群、可靠和可扩展的机器学习框架以及容错系统。在以下各节中,我们将讨论这些挑战,并提出解决这些挑战的方法。
LLM 的机器学习系统挑战
现代 LLM 的参数大小为数千亿,超过了单个设备或主机的 GPU 内存。例如, OPT-175B 模型需要 350GB 的 GPU 内存来容纳模型参数,更不用说训练期间梯度和优化器状态所需的 GPU 内存了,这可能会将内存需求推高到 1TB 以上。要了解更多信息,请参阅Democratizing Access to Large-Scale Language Models with OPT-175B.
同时,商品 GPU 只有 16GB / 24GB GPU ‘内存,即使是最先进的 NVIDIA A100 和 H100 GPU 每个设备也只有 40GB / 80GB GPU 内存。
为了有效地运行 LLM 的训练和推理,开发人员需要在其 计算图、参数和优化器状态,使得每个分区都适合单个 GPU 主机的内存限制。基于可用的 GPU 集群, ML 研究人员必须坚持在不同的并行化维度上进行优化的策略,以实现高效的训练
然而,目前,跨不同并行化维度(数据、模型和管道)优化训练是一个困难的手动过程。 LLM 的现有维度划分策略包括以下类别:
- 操作员间并行性:将整个计算图划分为不相交的子图。每个设备计算其分配的子图,并在完成后与其他设备通信。
- 操作员内部并行性:划分矩阵参与到子矩阵的运算符中。每个设备计算其分配的子矩阵,并在进行乘法或加法时与其他设备通信
- 组合:这两种策略都可以应用于同一个计算图。
请注意,一些研究工作将模型并行度分类为“ 3D 并行度”,分别表示数据、张量和管道并行度。在 Alpa 的术语中,数据只是张量并行度的外部维度,映射到操作器内并行度,而流水线并行度是互操作器并行度的结果,通过流水线编排将图划分为不同的阶段。这些功能是等效的,因此我们将保持分区术语的简单性和一致性,在文章的剩余部分使用术语“互操作器”和“操作器内”并行性
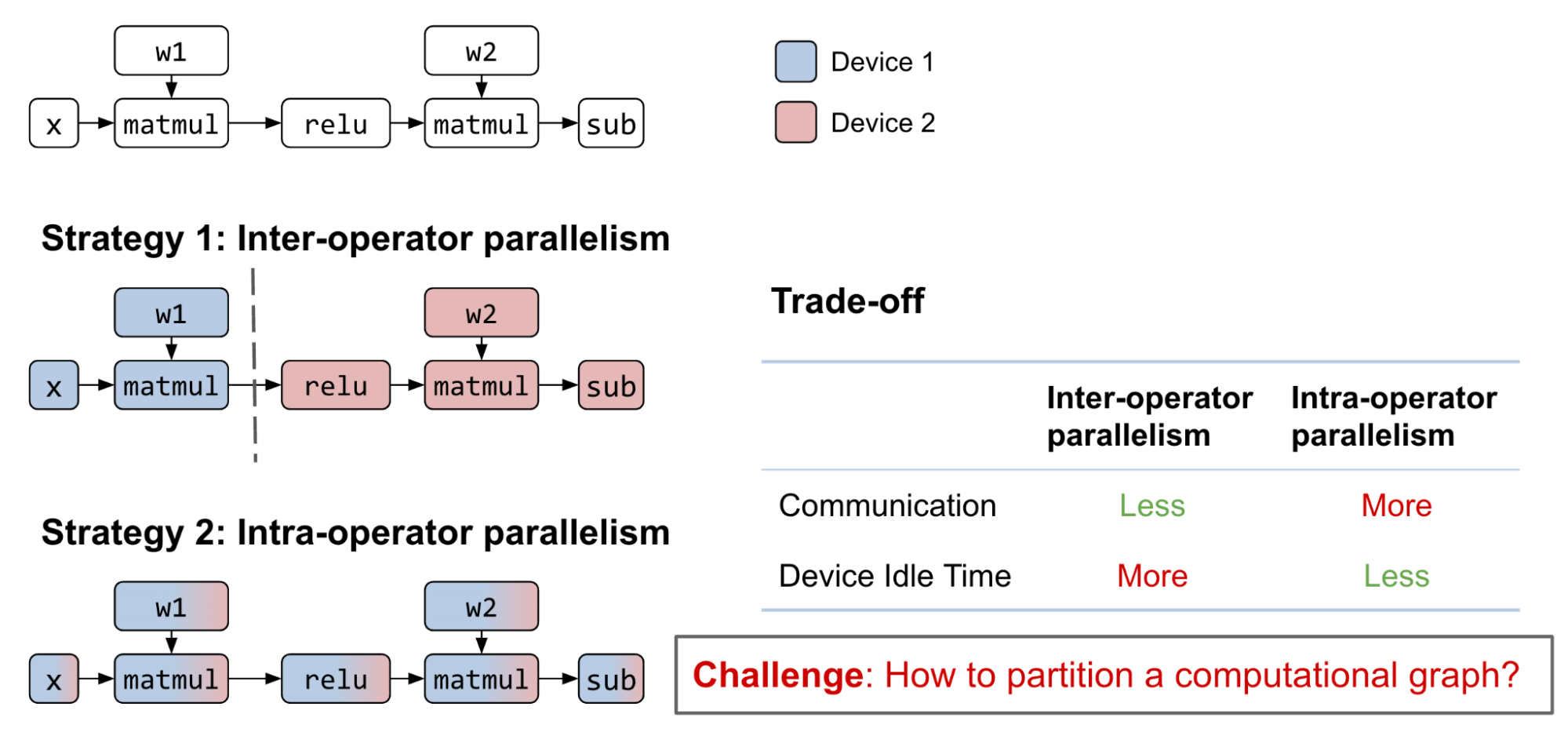
探索互操作和操作内并行的可能策略是一个具有挑战性的组合问题,需要各种权衡。通过合理的互操作并行计算图划分,子图之间的通信成本可以很小,但会引入数据依赖性。尽管流水线可以帮助缓解这个问题,但设备空闲时间仍然是不可避免的
另一方面,当下一个算子不能保留前一个算子的矩阵分区时,算子内并行可以在多个 GPU 设备之间并行化算子计算,空闲时间更少。这种方法带来了更高的通信成本。
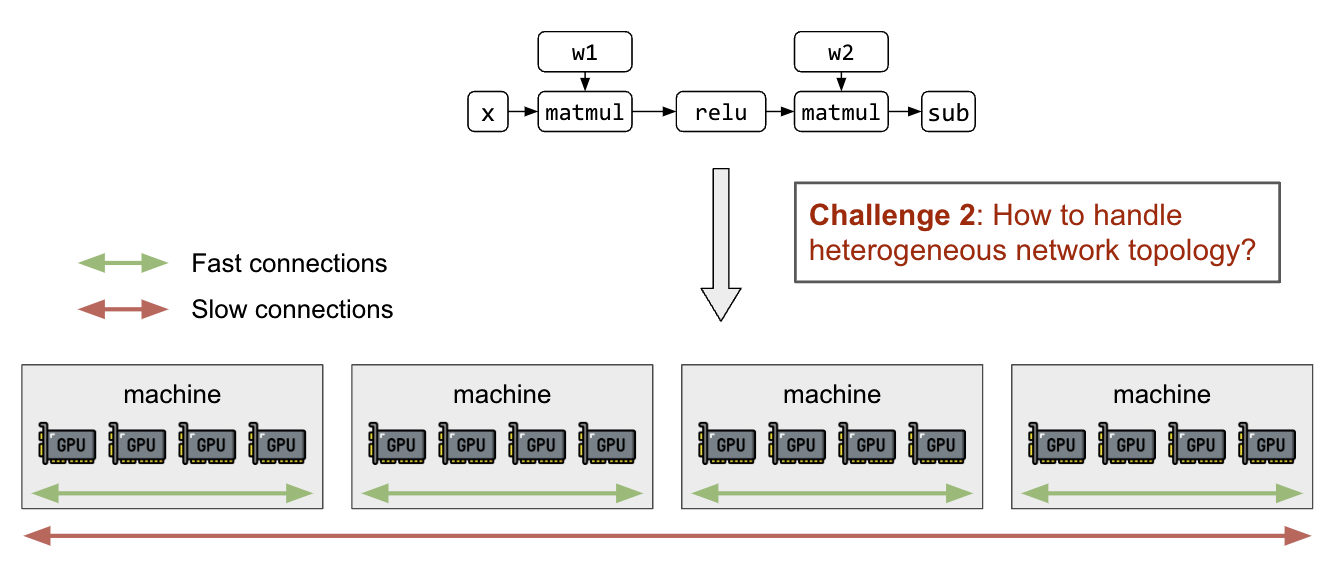
除了分区矩阵和计算图之外,还需要能够在了解异构网络拓扑的情况下将分区映射到 GPU 设备。节点内部的 GPU 连接( NVIDIA NVLink) 比主机间联网快几个数量级吗 (InfiniBand、 EFA 、以太网),并将导致不同分区策略之间的显著性能差异。
之前的 LLM 分区工作
先前在模型并行领域的工作已经实现了不同的并行技术(图 3 )。如上所述,确定和执行最佳模型分区策略是一个手动过程,需要深入的领域专业知识
Alpa 通过一行装饰器自动处理互操作器和操作器内并行性。这为大规模 LLM 的数据、张量和流水线并行性无缝地设计了一种分区策略。 Alpa 还能够推广到广泛的模型体系结构,这大大简化了模型并行性,使 LLM 更容易被每个人访问。
体系结构概述
在使用分层技术堆栈描述这些挑战的解决方案之前,重要的是提供堆栈关键组件的体系结构概述(图 3 )。这些组件包括位于底部的 GPU 加速器,然后是编译和运行时层、 GPU ‘管理和编排、自动模型并行化( Alpa ),最后是位于顶部的模型定义。

Alpa 简介
Alpa是一个统一的编译器,它可以自动发现并执行最佳的互操作程序和操作程序内并行性 深度学习模型。
Alpa 的关键 API 是一个简单的@alpa.parallelizedecorator ,用于自动并行化和优化最佳模型并行策略。给定具有已知大小和形状的 JAX 静态图定义train_step一个样本批次足以捕获自动分区和并行化所需的所有信息。考虑下面的简单代码:
@alpa.parallelize
def train_step(model_state, batch):
def loss_func(params):
out = model_state.forward(params, batch["x"])
return np.mean((out - batch["y"]) ** 2)
grads = grad(loss_func)(state.params)
new_model_state = model_state.apply_gradient(grads)
return new_model_state
# A typical JAX training loop
model_state = create_train_state()
for batch in data_loader:
model_state = train_step(model_state, batch)
Alpa 中的自动并行通行证
Alpa 引入了一种独特的方法来处理两级层次系统的复杂并行策略搜索空间。传统的方法一直在努力寻找一种统一的算法,该算法从互操作器和操作器内选项的巨大空间中导出最佳并行策略。 Alpa 通过在不同级别解耦和重组搜索空间来应对这一挑战。
在第一个层次上, Alpa 搜索最有效的互操作并行计划。然后,在第二个层次上,推导出互操作并行计划每个阶段的最佳操作内并行计划。
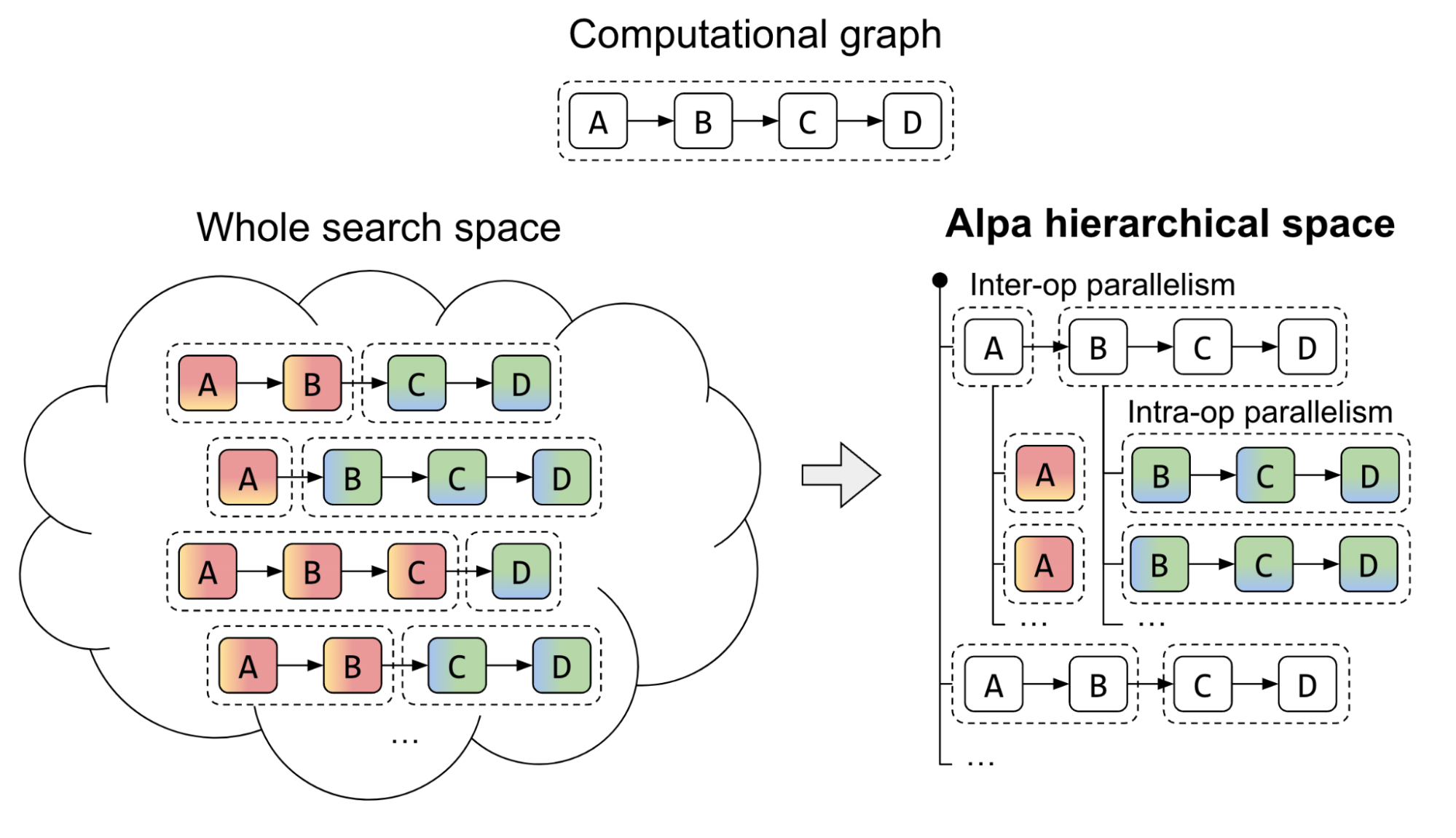
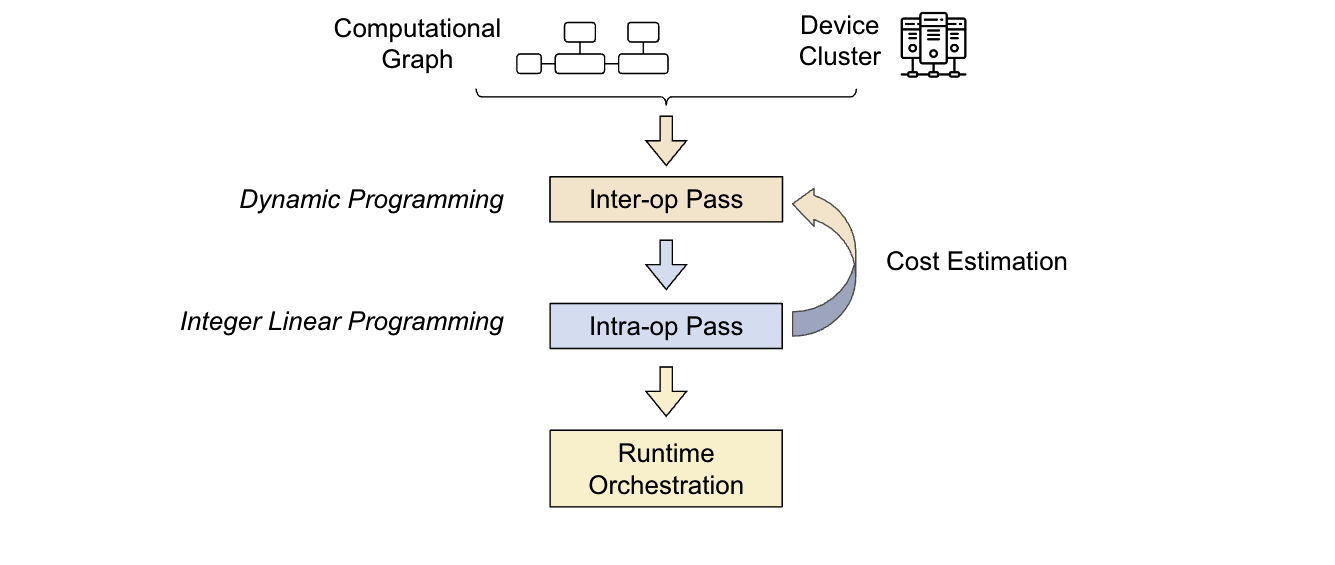
Alpa 编译器是围绕前面介绍的搜索空间分解方法构建的。它的输入包括一个计算图和一个集群规范。为了优化并行策略, Alpa 进行了两次编译:
- 第一次通过: Interoperator 使用动态编程来确定最合适的互操作并行策略。
- 第二次通过:操作员内部使用整数线性规划来确定最佳的操作员内部并行策略
优化过程是分层的。更高级别的互操作过程多次调用更低级别的操作过程,根据操作过程的反馈做出决策。然后,运行时编排过程执行并行计划,并将策略付诸实践。
在下一节中,我们将讨论 Ray ,它是 Alpa 构建的分布式编程框架。这将展示 GPU 集群虚拟化和管道并行运行时编排是如何实现的,以大规模地增强 LLM 。
Ray 简介
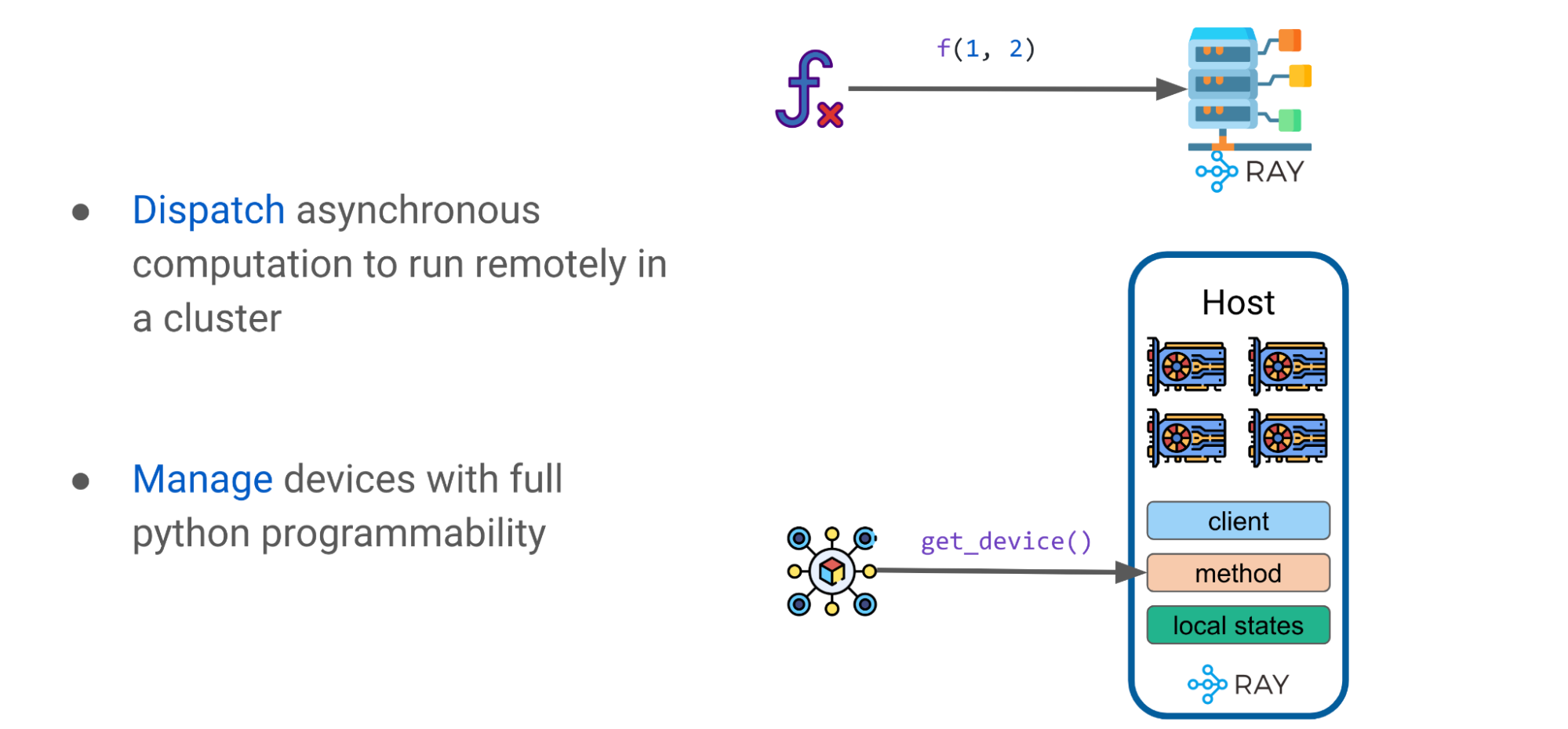
Ray是一个通用的统一框架,用于扩展和简化 ML 计算。出于本讨论的目的,您应该注意两个关键的 Ray 基元:tasks and actors.
射线任务
Ray 任务是无状态的,当使用@ray.remote可以调度 Ray 任务以在机器集群中的任何地方执行。调用,通过f.remote(args),是并行执行的,本质上是异步的。它们返回一个未来的对象引用,其值使用ray.get(object_ref).

射线演员
Ray actor 是一个 Python 类,它是有状态的。它是 Ray 中的一个基本构建块,使类能够在集群中远程执行,并保持其状态。在众多 GPU 设备上利用 Ray 演员可以访问各种引人注目的功能
例如,当处理一个有状态类时,开发人员可以运行一个首选的客户端,比如XLA运行时或 HTTP 。 XLA 是线性代数的编译器,它支持 JAX 和 TensorFlow 。 XLA 运行时客户端可以优化模型图并自动融合各个操作员。
使用射线模式和基元作为高级抽象
有了这些简单的 Ray 基元,例如 Ray 任务和演员,就可以制定一些简单的模式。以下部分将揭示如何使用这些基元来构建高级抽象,如 DeviceMesh 、 GPU Buffer 和 Ray Collective ,以大规模增强 LLM 。
高级模式: DeviceMesh
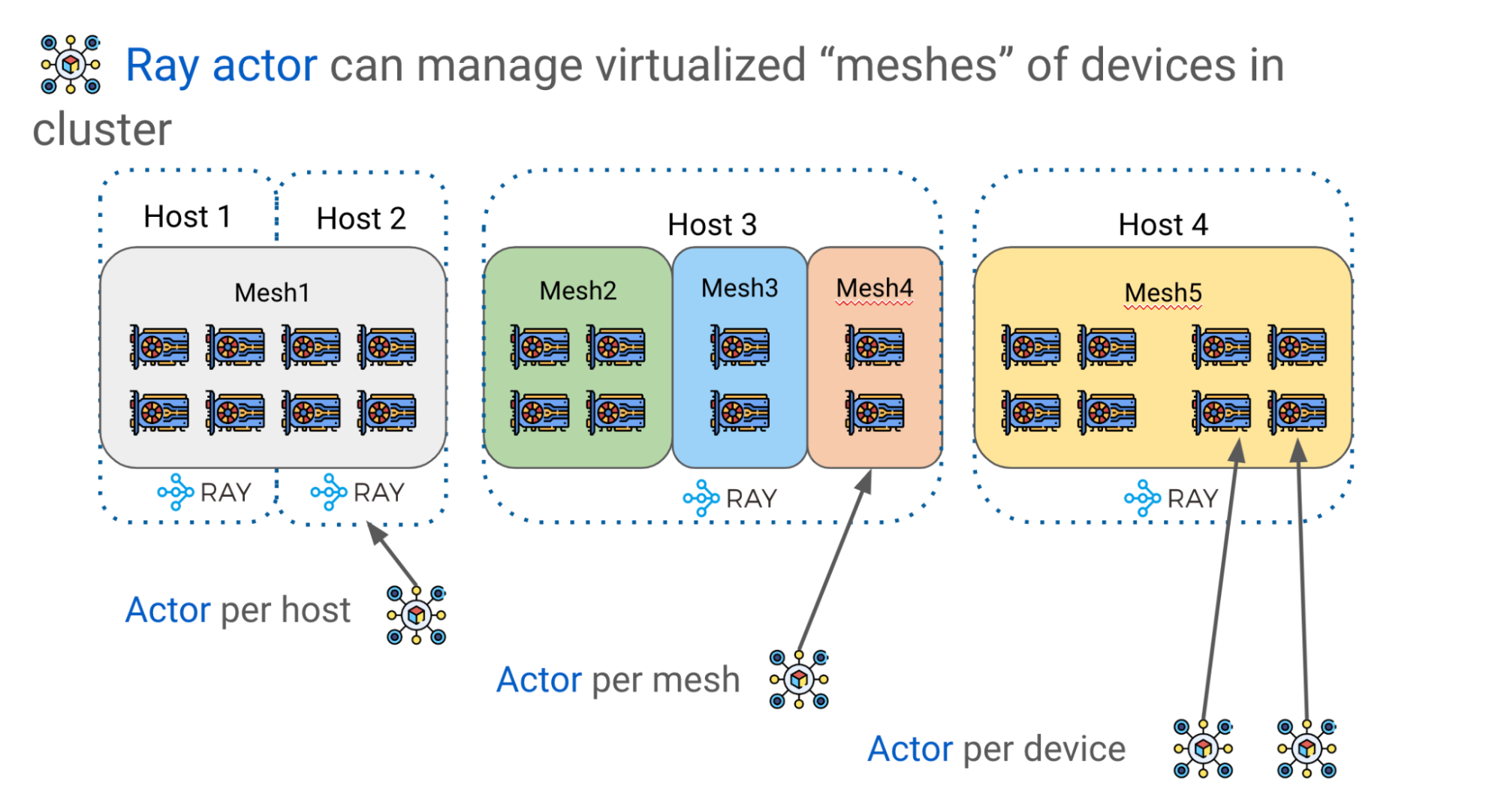
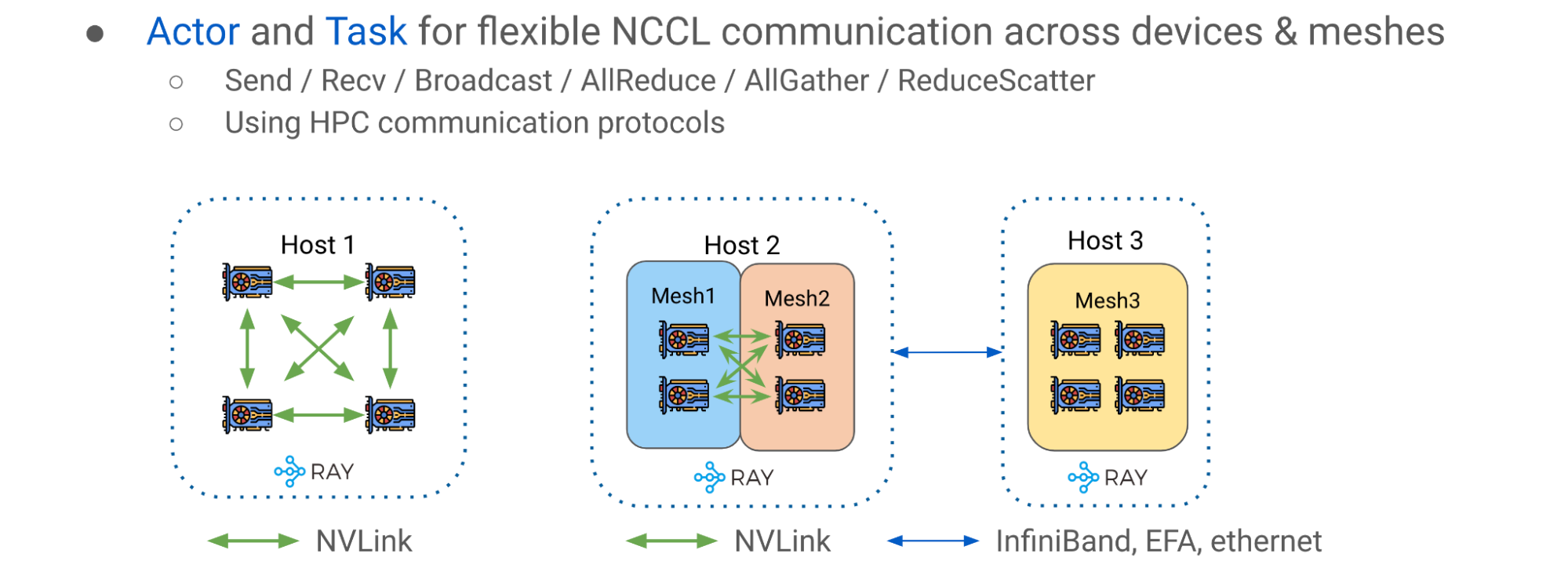
如前所述,有效地缩放 LLM 需要在多个 GPU 设备上进行分区模型权重和计算。 Alpa 使用 Ray actors 创建更高级的设备管理抽象,如 DeviceMesh ,一个由 GPU 设备组成的二维网格(图 8 )。
逻辑网格可以跨越多个物理主机,包括它们的所有 GPU 设备,每个网格获取同一主机上所有 GPU 的切片。多个网格可以位于同一主体上,一个网格甚至可以包含整个主体。 Ray actors 在管理集群中的 GPU 设备方面提供了巨大的灵活性
例如,根据所需的编排控制级别,可以选择每个主机、每个网格或每个设备有一个参与者。
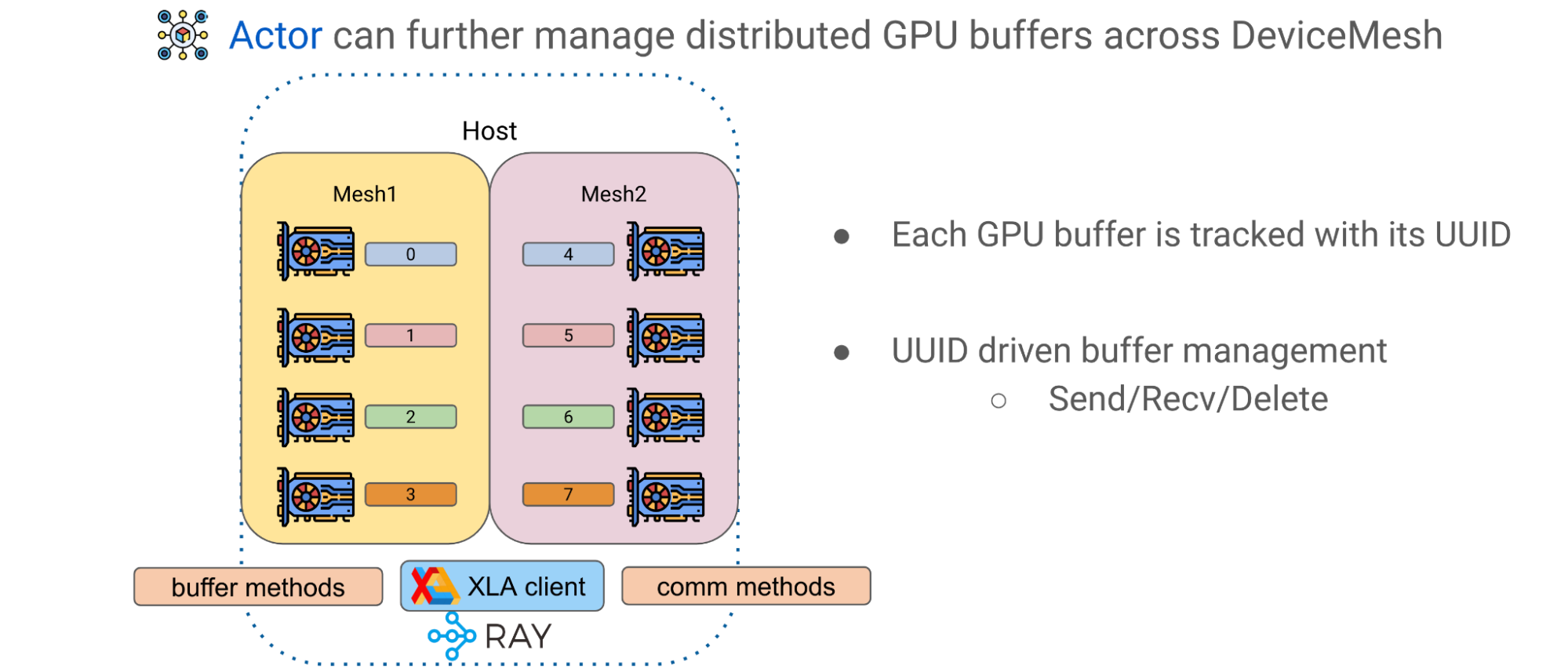
高级模式: GPU 缓冲
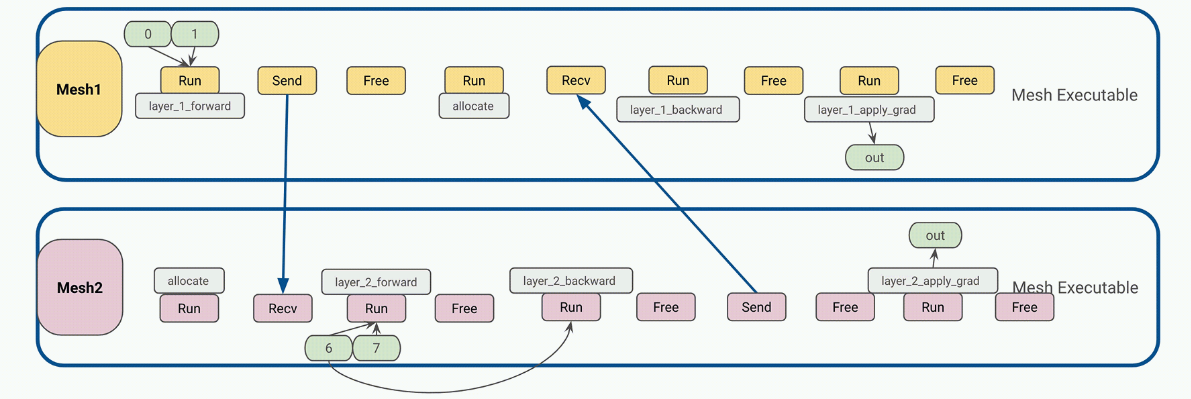
Alpa 中的第二个高级模式是跨 DeviceMeshes 的 GPU 缓冲区管理。 GPU 计算通常产生表示较大矩阵的瓦片的 GPU tensors 。 Alpa 有一个应用级 GPU 缓冲区管理系统,该系统为每个 GPU ‘缓冲区分配 UUID ,并提供基本原语,如发送/接收/删除,以实现跨网格张量移动和生命周期管理
使用 Ray actor 和 DeviceMesh 抽象,可以通过调用主机上的相应方法来管理和传输缓冲区,以促进高级模型训练范式。
高级模式: Ray 集体通信库
第三种高级模式是Ray collective communication library,一组通信原语,能够在不同的 CPU 、 GPU 和 DeviceMeshes 之间进行高效灵活的张量移动。它是实现流水线并行的重要通信层
简单的主机内情况如图 10 (主机 1 )左侧所示,其中 GPU 设备与 NVlink 互连。图 10 的右侧(主机 2 和 3 )显示了多网格、多主机场景,其中通信发生在一个潜在的更异构的设置中,该设置混合了主机内 NVLink 和主机间网络( InfiniBand 、 EFA 或以太网)。
使用 Ray 集体通信库,您可以通过与NVIDIA Collective Communications Library( NCCL )
管道并行运行时编排
在 JAX 和 Alpa 中,计算、通信和指令通常被创建为静态的。静态工件是一个重要的属性,因为在 JAX 中,用户程序可以被编译为中间表示( IR ),然后被馈送到XLA作为一个自包含的可执行文件。用户可以将输入传递到可执行文件中,并期望结果作为输出,其中所有张量的大小和形状都是已知的,就像张量的函数一样。
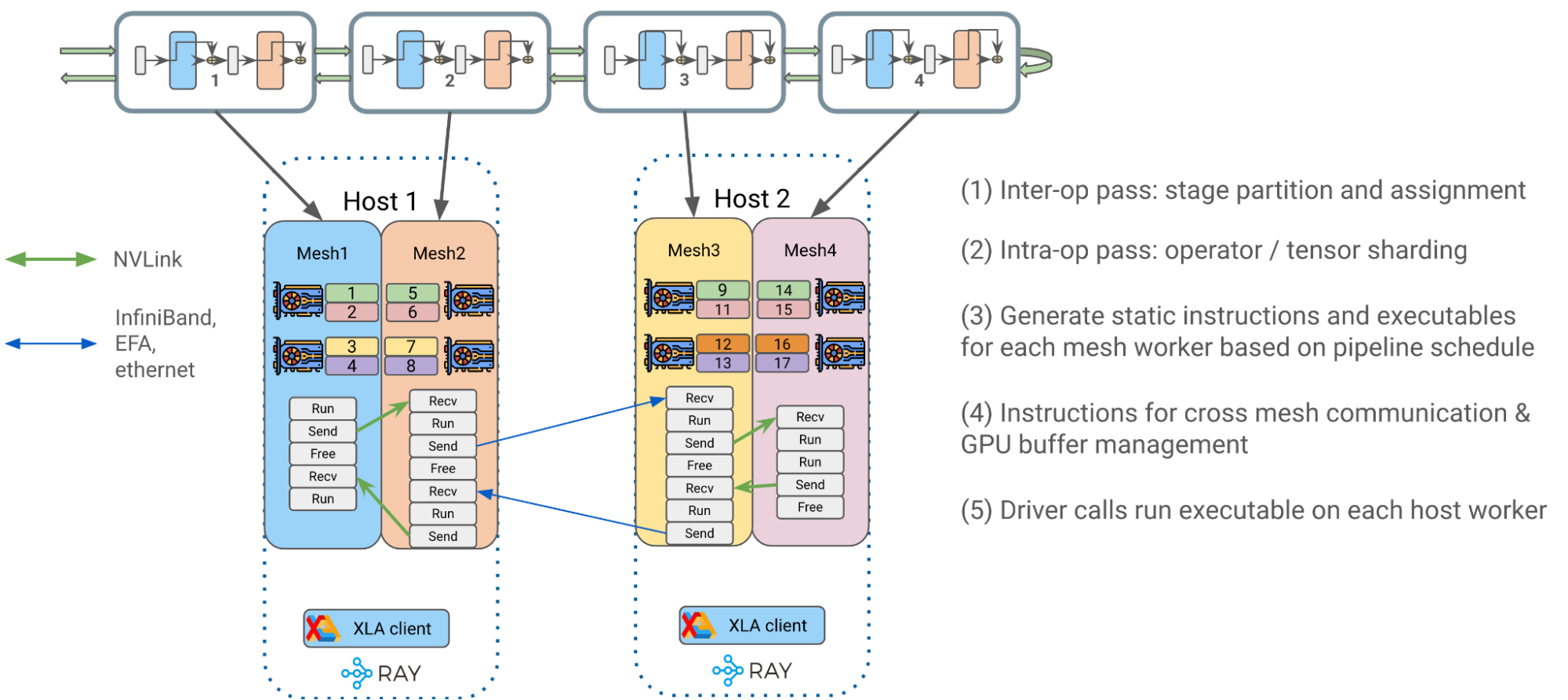
端到端流程大致可分为以下几个阶段:
- 操作员间并行通过:Alpa 将 transformer 块最佳地划分为单独的流水线级,并将它们分配给各自的 DeviceMesh
- 操作员内部并行通行证: Alpa 将居住在同一主机上的 GPU 设备的操作员输入和输出矩阵与GSPMD.
- 为网格工作者生成静态指令:为每个 DeviceMesh 编译一个关于用户配置(如管道计划)的静态可执行文件 (1F1B,GPipe) 、微聚集、梯度积累等等。
- 每条指令都是一个独立的 JAX HLO / XLA 程序,可以是 RUN 、 SEND 、 RECV 或 FREE 类型。每个都可以在 DeviceMesh 上分配、传输或释放 GPU 缓冲区。
- 静态指令大大降低了 Ray 单控制器级别的调度频率和开销,从而获得更好的性能和可扩展性。
- 将编译后的可执行文件放入相应的主机 Ray actor 中,以便稍后调用。
4 .驱动程序在每个主机工作程序上调用并编排已编译的可执行文件,以开始端到端流水线 transformer 训练。
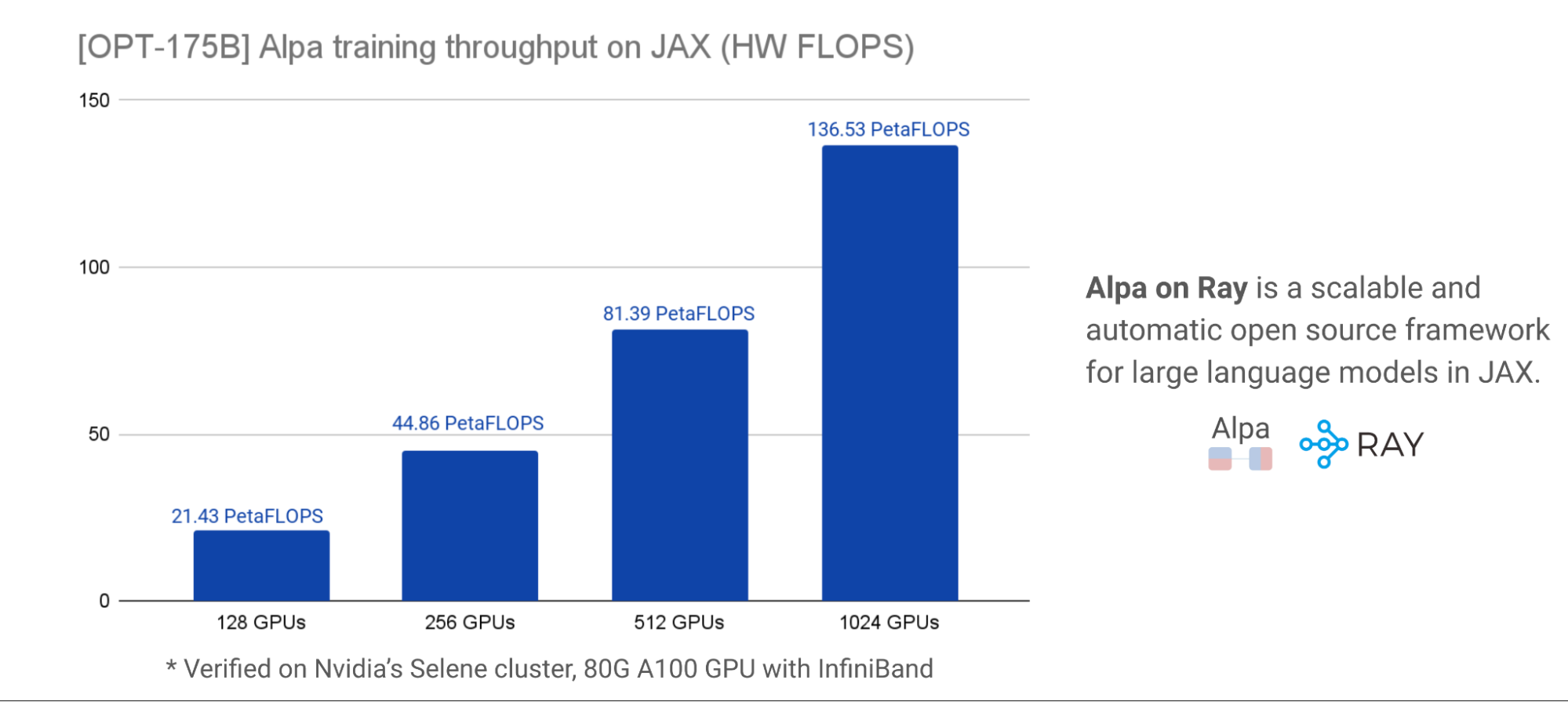
Alpa on Ray 基准测试结果
我们与 NVIDIA 密切合作,对这项工作进行了基准测试,以获得准确的性能和可扩展性结果。对于可扩展性和性能,下面的图表在NVIDIA Selene集群,展示了OPT-175B使用不同的 GPU 簇大小,在每个 GPU ~ 179 个 TFLOP 时, HW FLOP 的峰值利用率约为 57 . 5% 。模型并行化和分区是用一行装饰器自动完成的。
这些基准测试结果有力地表明, Alpa-on-Ray 是在 JAX 中训练 LLM 模型的最具性能和可扩展性的框架之一,即使规模为 1750 亿。此外, Alpa-on-Ray 能够自动找到并执行最佳并行化策略。
图 13 提供了有关模型定义和用于实现结果的其他配置的更多详细信息。
总结
结合 Alpa 和 Ray OSS 框架,开发人员可以在 JAX 上的大型集群中高效地扩展 LLM 培训。使用 Alpa 自动编译您的网络体系结构,并使用 Ray 在机器集群中协调和运行您的任务。
我们的团队估计将添加以下功能,以使用户具有更高的性能和灵活性:
- 在更大范围内支持具有 bf16 +管道并行性的 T5 。我们已经在容量限制范围内启用了四主机规模并进行了基准测试。
- 进一步简化了商品的 LLM 可访问性 GPU
额外资源
想要更多关于 Ray 、 Ray AIR 和 Ray on Alpa 的信息吗?
- 学How Ray Solves Common Production Challenges for Generative AI Infrastructure.
- 退房Ray on GitHub来源和更多信息。
- 探索Ray documentation.
- 每月加入Ray Meetup讨论所有的事情雷。
- 连接Ray community.
- 注册Ray Summit 2023.
想了解更多关于 Alpa 的信息吗?
- 退房Alpa on GitHub以获取 LLM 训练和推理的最新示例。
- 连接Alpa community on Slack.
鸣谢
感谢我们的团队AWS和CoreWeave感谢他们对我们在NVIDIA A100 Tensor Core GPUs以促进我们的互动发展。我们也感谢 NVIDIA 的内部NVIDIA Selene集群访问,以进行大规模的基准测试,并在整个合作过程中与我们合作