
目前最令人兴奋的计算应用程序依赖于在复杂的人工智能模型上进行训练和运行推理,通常是在要求苛刻的实时部署场景中。需要高性能、加速的人工智能平台来满足这些应用程序的需求,并提供最佳的用户体验
新的人工智能模型不断被发明,以实现新的功能,而人工智能驱动的应用程序往往依赖于许多这样的模型协同工作。这意味着人工智能平台必须能够运行最广泛的工作负载,并在所有工作负载上提供优异的性能。MLPerf Inference– 现在, v3.0 的第七版是一套值得信赖的、经过同行评审的标准化推理性能测试,代表了许多这样的人工智能模型。
人工智能应用程序无处不在,从最大的超大规模数据中心到紧凑的边缘设备。 MLPerf 推理同时代表数据中心和边缘环境。它还代表了一系列真实世界的场景,如离线(批处理)处理、延迟受限的服务器、单流和多流场景。这种工作负载广度和深度的平衡确保了 MLPerf 推理对于那些希望选择人工智能基础设施以最佳满足不同部署需求的人来说是一种宝贵的资源。
在 MLPerf 推理 v3.0 回合中,NVIDIA submitted results on several products包括…在内NVIDIA H100 Tensor Core GPUs( SXM 和 PCIe 附加卡的形状因素)基于NVIDIA Hopper architecture,最近宣布NVIDIA L4 Tensor Core GPU由NVIDIA Ada Lovelace GPU architecture,以及NVIDIA Jetson AGX Orin and NVIDIA Jetson Orin NX用于边缘人工智能和机器人应用的人工智能计算机
NVIDIA AI 平台( NVIDIA MLPerf 提交的核心)不断通过软件创新进行增强,这些创新提高了性能和功能,并利用了最新 NVIDIA 产品和架构的功能。TensorRT 8.6.0, NVIDIA 高性能深度学习推理 SDK 的最新版本,包含在 NVIDIA GPU 云上。要访问容器,请访问NVIDIA MLPerf Inference.
在最新提交的 NVIDIA MLPerf 推理中,添加了许多软件增强功能,包括支持和优化,以利用 NVIDIA Ada Lovelace 架构为NVIDIA L4 Tensor Core GPU,支持 NVIDIA Jetson Orin NX 、新内核,以及支持 NVIDIA 网络部门提交的重要工作
NVIDIA 平台在提交的文件中提供了破纪录的性能、能效和多功能性。这些成就需要在 NVIDIA 全栈平台的每一层进行创新,从芯片和系统到网络和推理软件。这篇文章详细介绍了这些结果背后的一些软件优化
NVIDIA Hopper GPU 实现又一次飞跃
在这一轮中, NVIDIA 使用 NVIDIA DGX H100 系统提交了可用类别的结果,该系统现已全面生产。 DGX H100 在 NVIDIA H100 Tensor Core GPU 的驱动下,每台加速器的性能都处于领先地位,与NVIDIA MLPerf Inference v2.1 H100 submission从 6 个月前开始,与 NVIDIA A100 Tensor Core GPU 相比,它已经实现了显著的性能飞跃。本文后面详细介绍的改进推动了这些结果。(请注意,每个加速器的性能不是 MLPerf 的主要指标。)
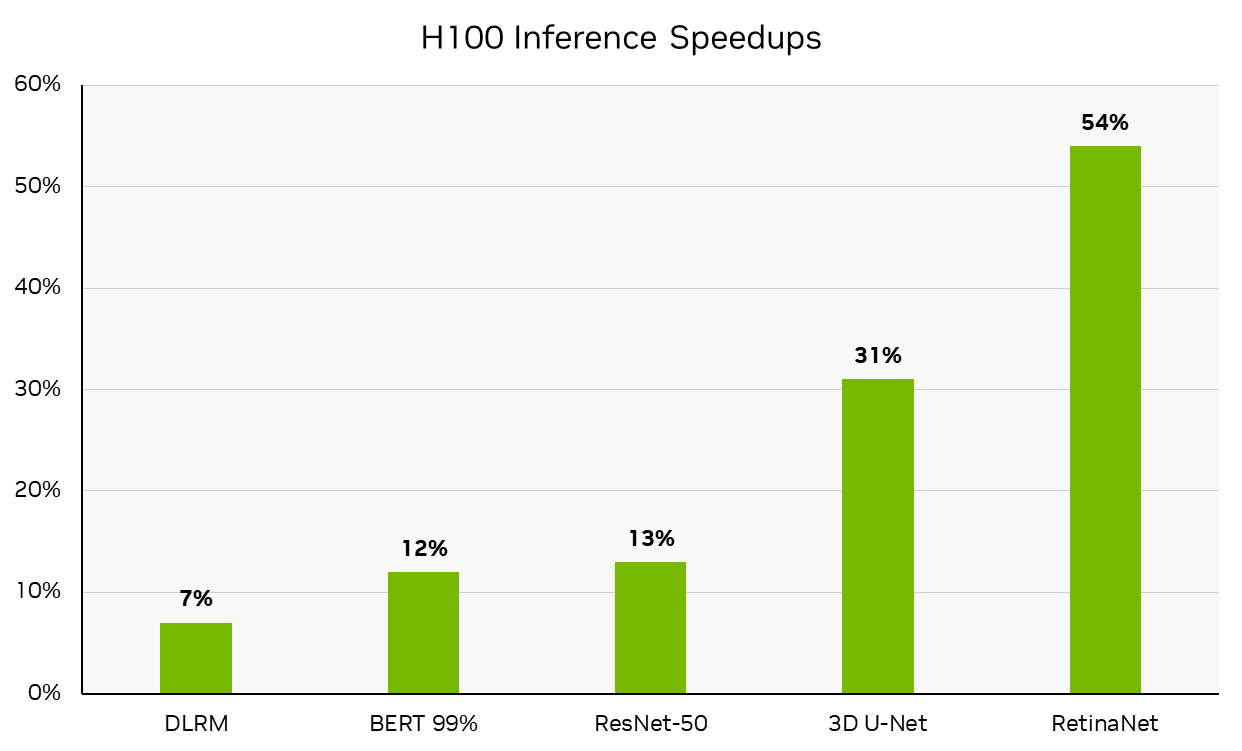
每加速器性能不是 MLPerf 推断的主要指标。 MLPerf 推理 v3.0 :数据中心,已关闭。通过计算 MLPerf 推理 v3.0 结果 ID 3.0-0070 (可用)中报告的推理吞吐量与 MLPerf 推断 v2.1 结果 ID 2.1-0121 (预览)中报告推理吞吐量相比的百分比增长得出的性能增长。 MLPerf 的名称和标志是 MLCommons 协会在美国和其他国家的商标。保留所有权利。严禁未经授权使用。看见网址: www.mlcommons.org了解更多信息
NVIDIA L4 Tensor Core GPU 领先
在 MLPerf 推理 v3.0 中, NVIDIA 首次提交了NVIDIA L4 Tensor Core GPU。 L4 基于新的 NVIDIA Ada Lovelace 架构,是流行的 NVIDIA T4 Tensor Core GPU 的继任者,在相同的单插槽、低剖面 PCIe 外形中为 AI 、视频和图形提供了显著改进。
NVIDIA Ada Lovelace 架构将第四代 Tensor 核心与 FP8 结合在一起,即使在高精度下也能实现出色的推理性能。在 MLPerf 推理 v3.0 中, L4 的性能比 T4 高出 3 倍, BERT 的参考( FP32 )精度为 99.9% ,这是 MLPerf 推断 v3.0 中测试的最高 BERT 精度级别
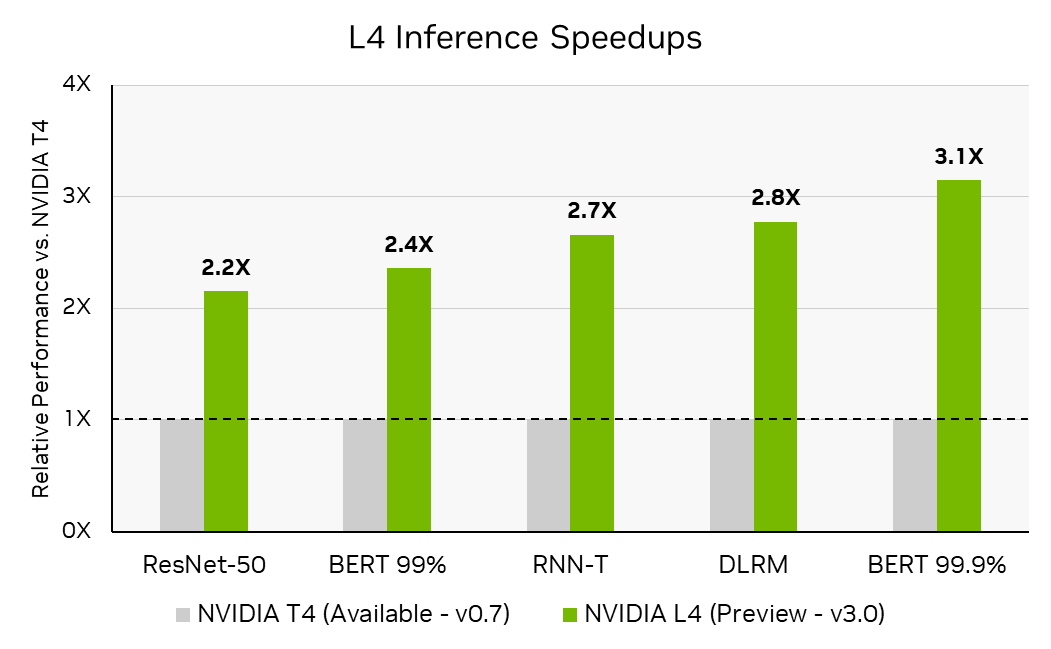
每加速器吞吐量不是 MLPerf 推断的主要指标。 MLPerf 推理 v3.0 :数据中心关闭。通过将 MLPerf 推理 v0.7 结果 ID 0.7-113 中报告的推理吞吐量除以加速器数量来计算每个加速器吞吐量的 T4 张量核心 GPU ,并计算 3.0-0123 (预览)中 L4 张量核心 GPU 的推理性能与 T4 的计算的每个加速器吞吐量之比来计算推理加速。 MLPerf 的名称和标志是 MLCommons 协会在美国和其他国家的商标。保留所有权利。严禁未经授权使用。看见网址: www.mlcommons.org了解更多信息
NVIDIA L4 还集成了一个大型 L2 缓存,为提高性能和能源效率提供了额外的机会。在 NVIDIA MLPerf Inference v3.0 提交中,实现了两个关键的软件优化,以利用更大的二级缓存:缓存驻留和持久缓存管理.
L4 上更大的 L2 缓存使 MLPerf 工作负载完全在缓存中。二级缓存以比 GDDR 内存更低的功率提供更高的带宽,因此 GDDR 访问的显著减少有助于提高性能和减少能源使用
与将批处理大小设置为最大容量时的性能相比,当优化批处理大小以使工作负载完全适应二级缓存时,观察到的性能高出 1.4 倍
另一个优化使用L2 cache persistence在中首次引入的功能NVIDIA Ampere architecture这使开发人员能够通过对 TensorRT 的单个调用来标记二级缓存的子集,从而可以对其进行优先保留(即,计划最后驱逐)。当在驻留机制下工作时,此功能对于推理特别有用,因为开发人员可以将内存重新用于整个模型执行的层激活,从而显著减少 GDDR 写入带宽的使用
使用 NVIDIA DGX A100 和 NVIDIA 网络提交网络划分
在 MLPerf 推理 v3.0 中, NVIDIA 首次在网络部门提交,旨在衡量网络对真实数据中心设置中推理性能的影响。网络结构,如以太网或NVIDIA InfiniBand将推理加速器节点连接到查询生成前端节点。目标是衡量 Accelerator 节点的性能,以及 NIC 、交换机和结构等网络组件的影响
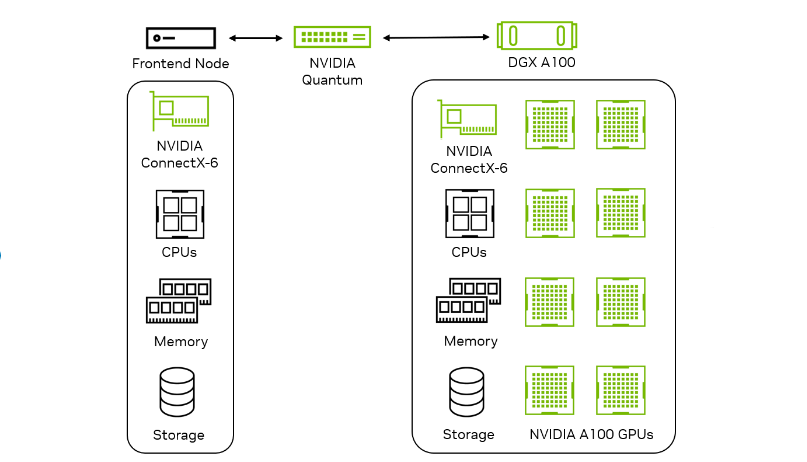
| 基准 | NVIDIA DGX A100 x8 | 网络事业部业绩 与封闭式部门相比 |
| RN50 低精度 | 脱机 | 100% |
| RN50 低精度 | 服务器 | 100% |
| BERT 低精度 | 脱机 | 94% |
| BERT 低精度 | 服务器 | 96% |
| BERT 高精度 | 脱机 | 90% |
| BERT 高精度 | 服务器 | 96% |
网络部门提交的性能相对于相应的封闭部门提交的百分比不是 MLPerf 推理 v3.0 的主要指标。通过将 MLPerf 推理 v3.0 结果 ID 3.0-0136 中 ResNet-50 和 BERT 上报告的吞吐量除以 3.0-0068 中报告的吞吐量计算的百分比。 MLPerf 的名称和标志是 MLCommons 协会在美国和其他国家的商标。保留所有权利。严禁未经授权使用。看见网址: www.mlcommons.org了解更多信息。
在 v3.0 网络部门, NVIDIA 提交了关于 ResNet-50 和 BERT 数据中心工作负载的报告。通过利用高带宽和低延迟,它们在 ResNet-50 上实现了 100% 的单节点性能GPUDirect RDMA上的技术NVIDIA ConnectX-6 InfiniBand smart adapters由于主机上的批处理开销,. BERT 对性能的影响最小。
几种 NVIDIA 技术结合在一起,实现了这些高性能结果:
- 来自 TensorRT 的优化推理引擎
- InfiniBand 远程直接内存访问( RDMA )网络传输,用于低延迟、高通量张量通信,基于IBV verbs在里面Mellanox OFED软件堆栈
- 用于配置交换、运行状态同步和心跳监测的以太网 TCP 套接字
- 利用 CPU / GPU / NIC 资源实现 NUMA 感知实现,以获得最佳性能
NVIDIA Jetson Orin NX 显著提升性能
NVIDIA Jetson Orin NX 16 GB该模块是最先进的人工智能计算机,适用于更小、更低功率的自主机器。在其首次提交的 MLPerf 推理中,与前代 NVIDIA Jetson Xavier NX 相比,它的性能提高了 3.2 倍。 NVIDIA 与Connect Tech关于 Jetson Orin NX MLPerf 推理 v3.0 提交,该提交托管在Boson NGX007 carrier boardConnect Tech Boson 支持 Jetson Orin NX 系列和 Jetson Orin Nano 系列,具有可用于开发和生产的紧凑型载板;将 Orin 的强大功能与商用现货的便利性相结合。
使用 Connect Tech 的 Boson NGX007 L4T 图像和由 cuDNN 、 TensorRT 和 CUDA 组成的 Jetson AGX Orin 软件堆栈,在 Jetson Orin NX 上开箱即用。 Jetson AGX Orin 和 Jetson Orin NX 共享相同的提交代码,展示了 NVIDIA 软件堆栈在新的 Jetson 产品、第三方承载板和主机系统上运行的多功能性
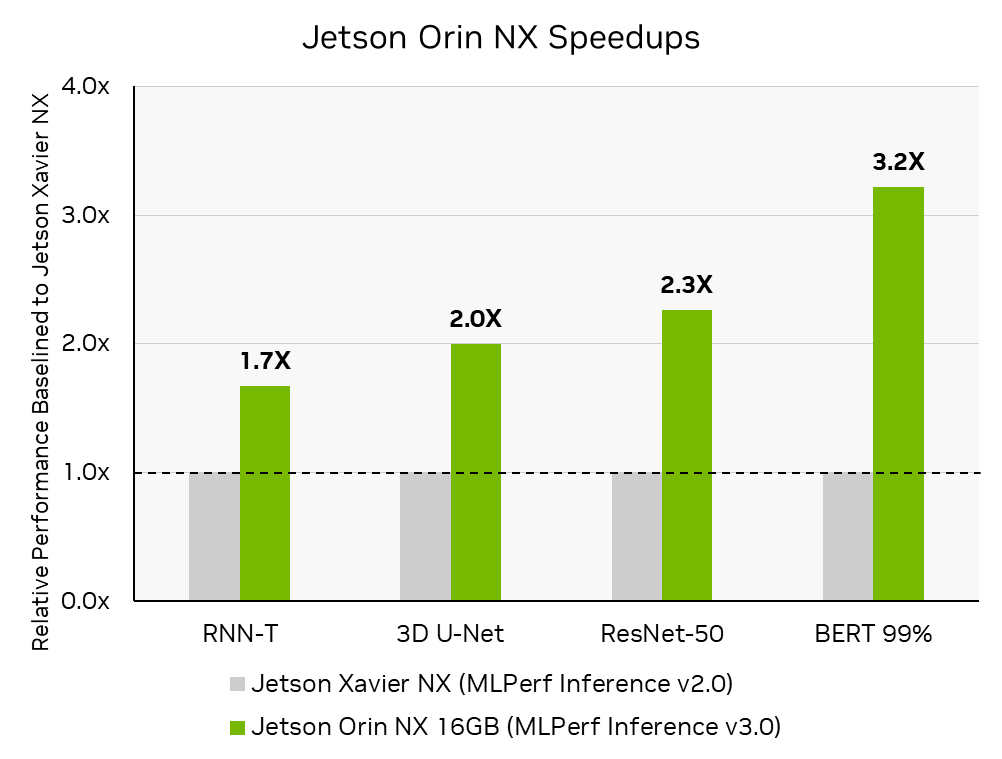
MLPerf 推理 v3.0 :边缘,关闭。通过计算 MLPerf 推理 v3.0:Edge , Closed MLPerf ID 3.0-0079 中报告的推理吞吐量的增加,与 MLPerf 推断 v2.0:Edge , Closeed MLPerf ID2.0-113 中报告的相比,获得性能提高。 MLPerf 的名称和标志是 MLCommons 协会在美国和其他国家的商标。保留所有权利。严禁未经授权使用。看见网址: www.mlcommons.org了解更多信息。
RetinaNet 优化
在 MLPerf 推理 v3.0 中, NVIDIA 通过全栈内核改进和优化的非最大值抑制( NMS ),将所有提交产品的 RetinaNet 吞吐量提高了 20-60% 。
RetinaNet NMS 预处理阶段具有显著的计算吞吐量和内存带宽,这是由于将 10 个卷积层输出重塑、转置和级联为两个张量。序列化和筛选还导致计算资源利用不足。
为了解决这些问题, NVIDIA 开发了一个优化的内核,该内核可以并行转换卷积层的输出。此外,标签得分过滤与转置融合,从而隐藏了内存负载开销,并加快了后续的分段排序。通过这些优化, NMS 现在比 2.1 中的速度快了 50% 。
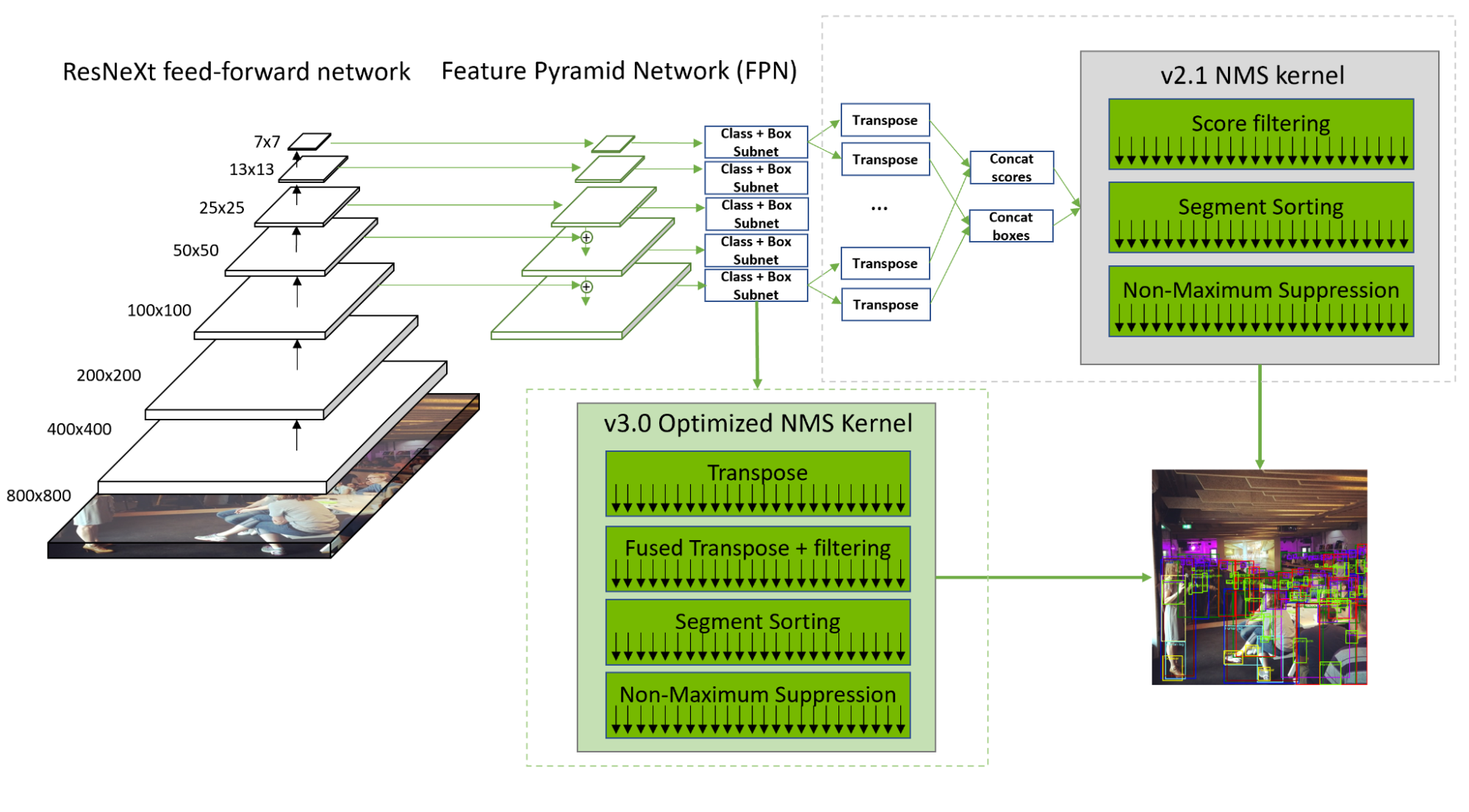
NVIDIA 还增加了对在Deep Learning Accelerator( DLA )内核。现在在 DLA 3.12.1 和 TensorRT 8.5.2 中提供,该支持使 RetinaNet 的非 NMS 部分能够完全在 DLA 上运行,而不是在 GPU 和 DLA 之间转换工作负载。整个非 NMS 部分可以编译为单个可加载的 DLA ,并卸载到运行时,使 RetinaNet 能够在 GPU 和 DLA 上同时运行。
DLA 3.12.1 优化通过提高 SRAM 的利用率,以及一种新的搜索算法来确定 SRAM 中激活数据和权重数据之间的最佳分割比,从而最大限度地减少了延迟和 DRAM 带宽。参观NVIDIA/Deep-Learning-Accelerator-SW有关详细信息,请访问 GitHub 。
这减少了 20% 的延迟和 50% 的 DRAM 消耗。这些 DLA 优化也有利于其他 CNN 工作负载。此外, DLA 软件还优化了 ResNeXt 分组卷积模式,使 DRAM 流量增加 1.8 倍,减少 1.8 倍。
Orin DLA 功能的这种有效利用对于将 RetinaNet 的性能和能效提高 50% 以上(在同一硬件上不到一年的时间)至关重要,从而实现 NVIDIA 不断提高 Jetson AGX Orin 软件性能的承诺。看见Delivering Server-Class Performance at the Edge with NVIDIA Jetson Orin了解更多信息。
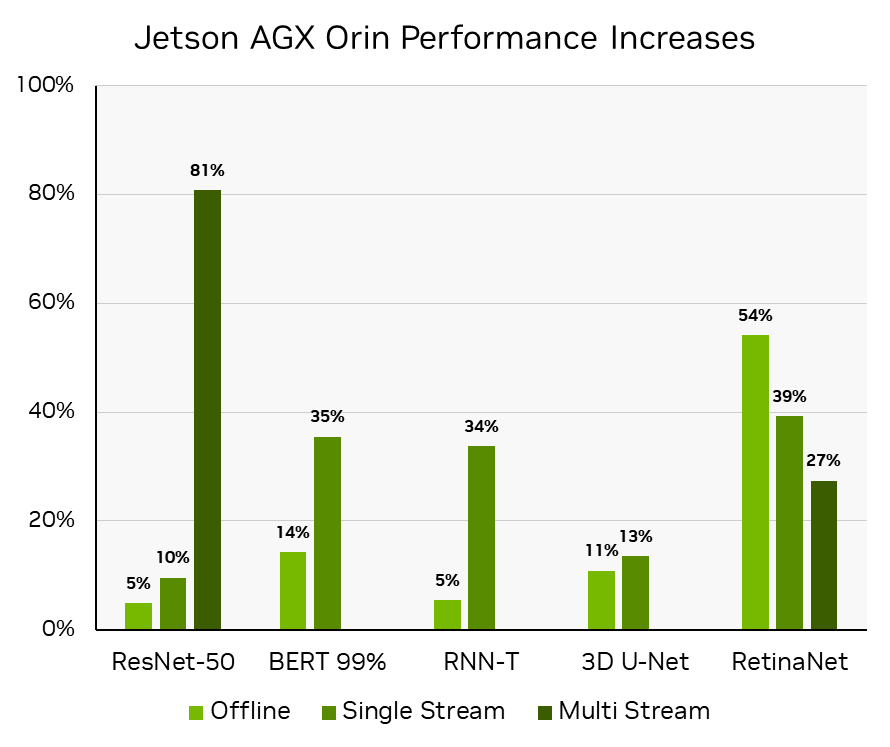
通过计算 MLPerf 推理 v3.0:Edge , Closed 中报告的推理吞吐量的百分比来获得性能提高。 MLPerf ID 3.0-0080 与 MLPerf 推理 v2.0:Edge 中报告的那些相比, ResNet-50 、 BERT 和 RNN-T 工作负载的 MLPerf IDs 为 2.0-140 关闭,与 MLPerf 推理 v2.1:Edge 中报告, RetinaNet 为 2.1-0095 关闭,因为 RetinaNet 是在 v2.1 中首次添加的。 MLPerf 的名称和标志是 MLCommons 协会在美国和其他国家的商标。保留所有权利。严禁未经授权使用。看见网址: www.mlcommons.org了解更多信息。
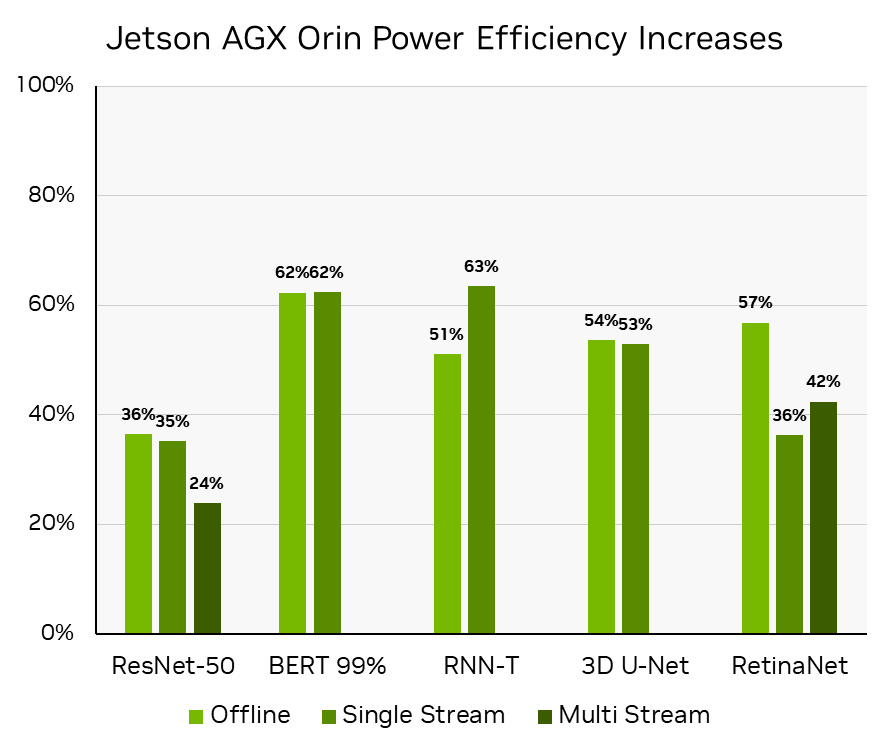
MLPerf 推理 v3.0 :边缘,闭合,电源。功率效率是通过计算 MLPerf 推理 v3.0 MLPerf ID 3.0-0081 中离线场景的吞吐量/瓦和单流和多流场景的焦耳/流的增加来推导的,相比之下, ResNet-50 、 BERT 和 RNN-T 工作负载的 MLPerf 推断 v2.0 MLPerf ID2.1-141 和 RetinaNet 的 MLPerf 推理 v2.1 MLPerf ID:2.1-0096 ,因为 RetinaNet 是在 MLPerf 推理 v2.1 中首次添加的。
3D U-Net 分批次滑动窗口
3D U-Net 对 KiTS19 输入数据使用滑动窗口推理。每个输入图像被划分为具有 50% 重叠的 ROI 子体积,并用于子体积分割。对结果进行聚合和归一化,以获得输入图像的分割。看见Getting the Best Performance on MLPerf Inference 2.0了解更多信息。
对于 MLPerf 推理 v3.0 ,引入了滑动窗口批处理来进行子卷的批处理。由于批处理仅在给定图像的子卷上进行,而不是在不同图像之间进行,因此这也有利于单流场景。(参见MLPerf Inference: NVIDIA Innovations Bring Leading Performance了解更多详细信息。)这提高了 GPU 的利用率,尤其是使用 NVIDIA A100和H100[Z1K1’时,性能提高了30%。
挑战在于确保在重叠元素的最终输出张量聚合中引入的竞争条件期间的函数正确性。为了解决这个问题,CUDA Cooperative Groups在聚合和规范化内核中使用。尽管这增加了同步开销,但由于将相邻子卷批处理在一起会带来好处,因此可以获得更好的性能。子卷有 50% 的数据重叠,这提高了缓存并减少了内存流量。
ResNet-50 优化
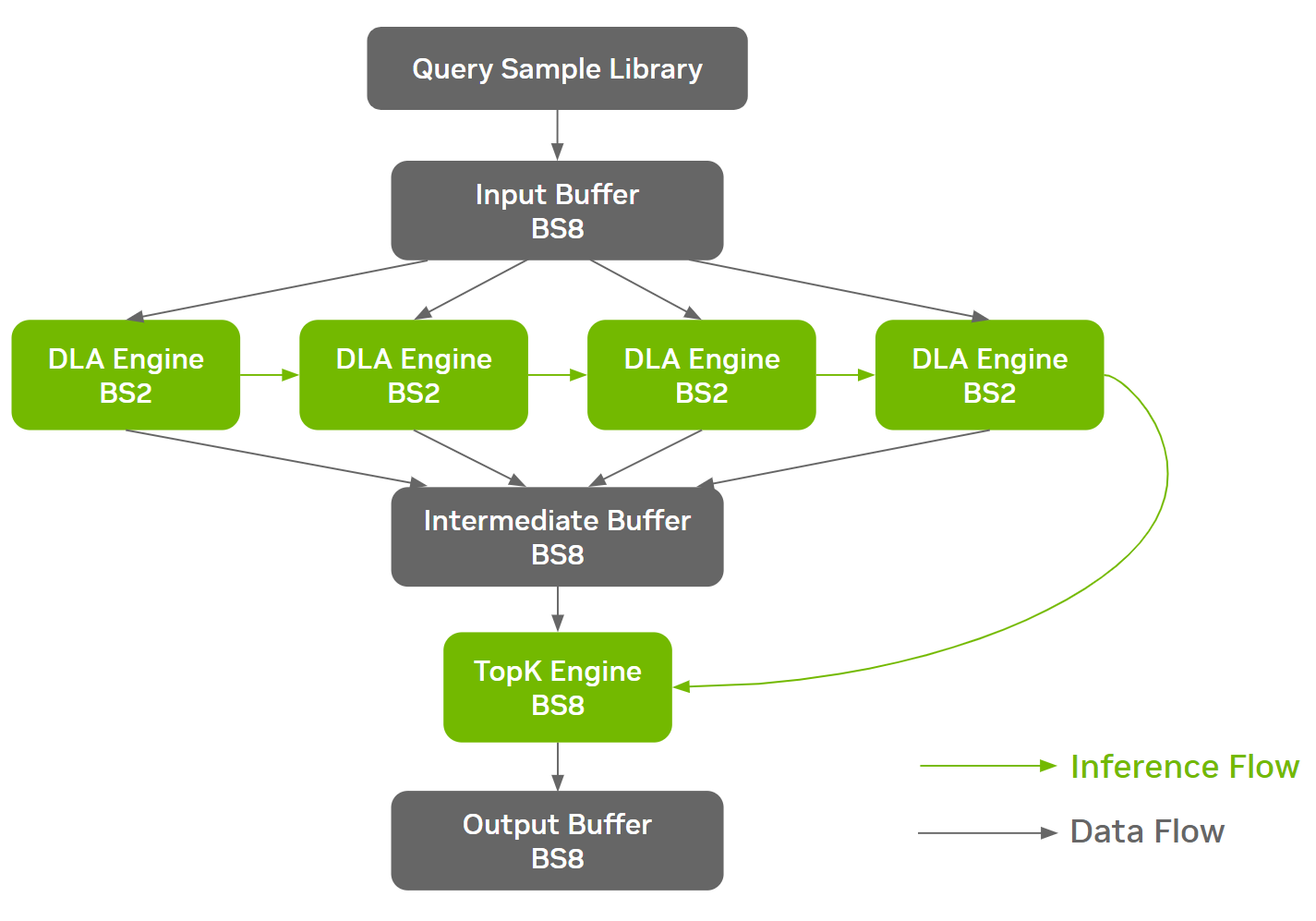
ResNet-50 等工作负载在网络架构的不同阶段具有不同的内存特性,为面向 DRAM 的优化创造了机会。在 NVIDIA MLPerf 推理 v3.0 ResNet-50 提交中采用的一种这样的优化是批处理拆分
这使得不同的批量大小能够在网络的不同阶段运行,从而在效率和 DRAM 带宽利用率之间找到最佳折衷。 NVIDIA 提交采用在内存密集的部分之前将较大的批次拆分为较小的批次,依次对其进行推理,然后将其收集回较大的批次
在构建阶段期间,ONNX GraphSurgeon自动识别定义的切割点,并将单个 ONNX 模型拆分为多个克隆的子图。 TensorRT 为每个唯一的 ONNX 分区生成一个独立的引擎。该线束负责协调引擎的执行和通信缓冲器的管理,从而不引入额外的设备到设备( D2D )拷贝。
通过批处理拆分方法, Orin 系统上的 ResNet-50 Offline 实现了约 3% 的端到端性能改进。下图以线束中的数据流和推理流为例进行了说明。
NVIDIA AI 推理从云端到边缘的领先地位
NVIDIA 平台通过广泛的全栈工程不断提高人工智能推理性能。通过软件,NVIDIA H100 Tensor Core GPU在一轮中,推理性能提高了 54% 。深度软硬件协同优化使NVIDIA L4 Tensor Core GPU与 NVIDIA T4 GPU 相比,可提供高达 3 倍的性能
对于自动驾驶机器和机器人, NVIDIA Jetson AGX Orin 的性能和每瓦性能提高了 50% 以上。 NVIDIA Jetson Orin NX 的性能是前代产品的 3.2 倍
NVIDIA 平台还继续展示领先的多功能性,在所有 MLPerf 推理工作负载中提供卓越的性能。随着人工智能不断改变计算,在一组多样化且不断增长的工作负载和一组不断增长的部署选项中提供出色性能的需求只会增加。 NVIDIA 平台正在迅速发展,以满足人工智能应用程序的当前需求,同时准备加速未来的需求




