这篇文章是优化工作站端到端人工智能系列文章的第一篇。有关更多信息,请参见第 2 部分, 工作站端到端 AI : 使用 ONNX 转换 AI 模型 和第 3 部分, 工作站端到端 AI : ONNX 运行时和优化 .
GPU 的伟大之处在于它提供了巨大的并行性;它允许您同时执行许多任务。在最精细的层面上,这归结为有数千个微小的处理内核同时运行同一条指令。但这并不是这种并行性停止的地方。还有其他方法可以利用经常被忽视的并行性,特别是在人工智能方面。
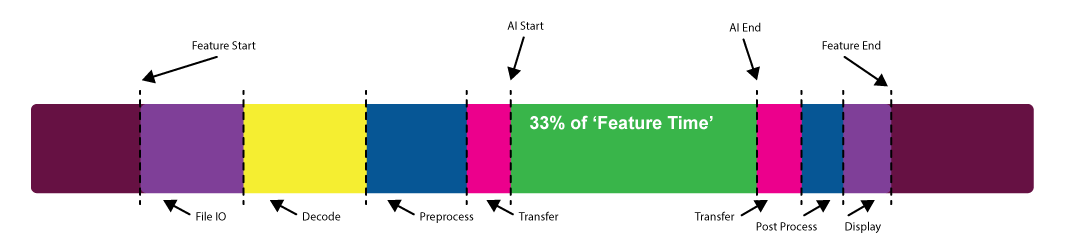
当你考虑人工智能功能的性能时,你到底是什么意思?您是否只是在考虑模型本身运行所需的时间,还是在考虑加载数据、预处理数据、传输数据以及写回磁盘或显示所需时间?
这个问题可能最好由体验该功能的用户来回答。通常会发现,实际的模型执行时间只是整个体验的一小部分。
这篇文章是本系列文章的第一篇,它将引导您了解几个特定于 API 的用例,包括:
- ONNX 运行时和 Microsoft WinML
- NVIDIA TensorRT
- NVIDIA cuDNN
- Microsoft DirectML
工作站上的人工智能是一种相对较新的现象。传统上是服务器和云的东西,但这正在发生变化,尤其是在内容创建领域。因此,现在有许多现有的代码库被新的人工智能功能所补充。
在实现 AI 功能时首先要问的问题之一是,如何运行推理?约束条件是什么?您需要支持哪些平台?
根据您确定的约束条件,您可以选择基于 DirectML 和 WinML 的方法或基于 CUDA 和 TensorRT 的方法。无论您选择何种方法,您还应考虑如何将您的功能集成到现有工作流或管道中。
考虑在内容创建空间中生成 AI 的一个相对常见的工作流:去噪功能。要运行此去噪器,必须执行以下步骤:
- 将模型加载到 GPU 存储器中。
- 使输入数据可用于模型。
- 通过模型传递输入数据。
- 对输出数据执行某些操作。
这个列表中有很多歧义,所以我想讨论每一步。
将模型加载到 GPU 存储器中
你什么时候、怎么做?
模型有各种形状和大小,从几千字节到几千字节。如果您的模型作为长时间运行的管道的一部分执行,则可能无法持久地将大型模型保存在内存中。
理想情况下,您将使模型加载尽可能远离性能路径,但有时这很难做到。您可能必须在管道运行时加载和卸载模型。
最好的情况是一次加载一个模型,并尽可能多次使用它。在无法做到这一点的情况下,大多数框架都可以相对快速地卸载序列化模型并将其流式传输回 GPU 。
使输入数据可用于模型

这一步是让事情变得有趣的地方。通常,这是一个有很多低挂的水果来提高你的表现的地方。
最终,模型期望以特定格式使用输入数据。这几乎总是意味着特定的缩放和偏移、格式转换(例如, UINT8 到 FP16 ),以及可能的一些布局转换。在 NVIDIA 硬件上, Tensor Core 更喜欢 NHWC 布局。
通常,还必须进行其他预处理。可能存在从频率空间到频率空间的转换或从某种压缩格式解码。
这是 GPU 可以有效完成的所有工作,因此允许 GPU 来完成这项工作非常重要。允许 CPU 完成这项任务或将工作卸载到第三方库都是很有诱惑力的。后者是一种非常明智的做法。在任何一种情况下,您都必须确保尽量减少与 GPU 之间的传输,并加快操作本身。如果您正在使用第三方 GPU 解决方案进行预处理和后处理,您能否确保数据尽可能长时间保留在 GPU 上?
在许多情况下,可能存在预处理和格式转换的解决方案,这些解决方案可以由模型本身使用本机运算符执行。在大多数情况下,通过将这些运算符添加到模型的开头和结尾,可以执行到 FP16 的转换、缩放和偏移。
无论您如何进行预处理,在某些时候,您当然必须将输入数据传输到 GPU ,以便模型可以使用它。这引发了另一个重要的考虑。
当您的输入数据很大时,如果可以的话,您必须在平铺中执行推断。这意味着要加载一个或多个平铺的批次,并在加载下一个批次之前运行推断。
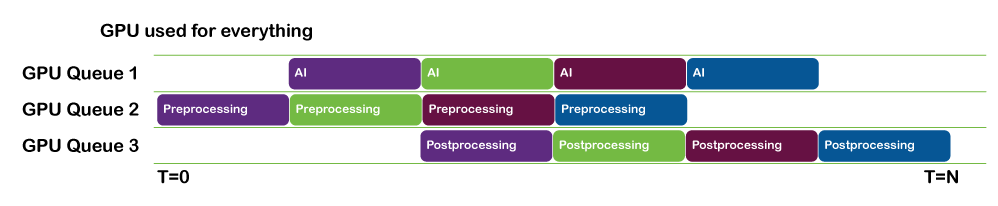
加载数据和运行推断可以并行完成。您可以对这项工作进行流水线处理,以便在批处理 N 完成推断时,批处理 N + 1 已完成加载并准备运行。
- 如果您使用的是 NVIDIA CUDA 或 NVIDIA TensorRT ,请使用 CUDA 流来实现这一点。
- 如果您使用的是基于 DML 的推理解决方案,请并行使用 DirectX 队列以保持事情的进展。
像这样的平铺操作是高度并行的,是在 GPU 本身上执行的良好候选。如果难以处理 GPU 内存中的整个图像,您可以将图像分割为多个部分,这些部分可以平铺,而下一个部分将流式传输到 GPU 。
通过模型传递输入数据
要在运行推断本身时获得模型的最佳性能,请确保以下所有语句均为真:
- 输入数据在最快的设备本地存储器中提供
- 您正在利用 NVIDIA 硬件提供的功能,例如 Tensor Core 。
- GPU 是完全饱和的,我的意思是 GPU 被赋予了足够的工作以使其保持忙碌。
使用正确的内存
大多数 GPU 可以访问几个物理堆。一般来说,可编程堆通常是以下之一:
- Host-visible
- 驻留在系统内存中,并通过 PCI 系统上的 PCI 总线读取
- 您可以写入此内存,但可能不是 GPU 访问的最快速度
- Device-local
- 驻留在设备( GPU )内存中
- 内存很快,但不能直接写入
获得最快内存访问的一般工作流程是将数据写入主机可见内存。然后,发出 GPU 命令,将数据从主机复制到设备本地存储器
如果您使用的是基于 CUDA 的平台,如 TensorRT 或 cuDNN ,那么这相对容易管理,因为驱动程序会为您执行此操作。然而,在主机上可以做的一件事就是在主机上使用固定内存。也就是说,在分配主机内存时,请使用hostAlloc而不是malloc。这使得 GPU DMA 能够直接调度存储器传输,而不必涉及到到 DMA 存储器池中的单独 CPU 传输,从而导致较低的延迟。
如果您使用的是基于 DirectML 的方法,则必须自己管理向快速内存的传输。这是值得的,因为它可以让您完全控制数据传输的确切时间,以及与其他工作并行执行传输的机会。
使 GPU 饱和
在进行任何 GPU 相关工作时,一个通常被忽略的瓶颈是没有给 GPU 足够的工作。当这种情况发生时,您可能会发现没有足够的工作来保持 GPU 上的所有流式多处理器( SM )忙碌。
在这种情况下,增加空间维度或批量大小等策略可以显著帮助。您可能会发现,批量大小为 8 的运行速度与批量大小为 1 的运行速度相同。
正如模型的大小和复杂性可能不同一样, GPU 也是如此。一种 GPU 的最佳批量大小对另一种可能不是最佳的。使用 NVIDIA NSight 系统进行评测可以帮助您识别给定系统上利用率低的情况,并帮助您相应地设计推理策略。
保持 GPU 忙碌的其他策略是使用多个 CUDA 流或 DirectX 命令队列并行执行其他计算甚至 AI 工作。
每种情况都是独一无二的,但 CUDA 和 DirectML 以及 DirectX 都为您提供了使 GPU 在给定问题上尽可能忙碌的方法。
对输出数据执行某些操作
当推断完成并且有了输出时,可以应用与输入数据类似的原则。也就是说,您可以以与输入数据类似的方式对数据进行后处理,方法是向图形中添加节点或使用自定义计算步骤。
如果必须将数据读回主机内存,也可以与下一个推理批并行执行。如果您的数据必须直接显示,则应通过使用相关平台的适当互操作功能(例如, CUDA 到 OpenGL ),避免任何不必要的往返 CPU 。
结论
请记住,每个用例都是不同的,对于一个特定用例来说很好的方法可能不适用于另一个用例。
要阅读本系列的下一篇文章,请参阅 End-to-End AI for Workstation: Transitioning AI Models with ONNX 和 End-to-End AI for Workstation: ONNX Runtime and Optimization .
注册 了解有关使用 NVIDIA 技术加速您的创意应用程序的更多信息 。