
这篇文章是优化工作站端到端人工智能系列文章的第二篇。有关更多信息,请参见第 1 部分, 工作站端到端 AI : 优化简介 和第 3 部分, 工作站端到端 AI : ONNX 运行时和优化 .
在这篇文章中,我讨论了如何使用 ONNX 将人工智能模型从研究过渡到生产,同时避免常见错误。考虑到 PyTorch 已经成为最流行的机器学习框架,我的所有示例都使用它,但我也提供了 TensorFlow 教程的参考。
与 ONNX 的互操作性
ONNX (开放式神经网络交换)是描述深度学习模型的开放标准,旨在促进框架兼容性。
考虑以下场景:您可以在 PyTorch 中训练神经网络,然后在将其部署到生产环境之前通过 TensorRT 优化编译器运行它。这只是许多可互操作的深度学习工具组合中的一种,包括可视化、性能分析器和优化器。
研究人员和 DevOps 不再需要将就一个未优化建模和部署性能的单一工具链。
为此, ONNX 定义了一组标准运算符以及基于 Protocol Buffers serialization format 的标准文件格式。该模型被描述为具有边的有向图,边指示各种节点输入和输出之间的数据流,以及表示运算符及其参数的节点。
导出模型
我为以下情况定义了一个由两个Convolution-BatchNorm-ReLu块组成的简单模型。
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.model = torch.nn.Sequential(
torch.nn.Conv2d(3, 16, 3, 2),
torch.nn.BatchNorm2d(16),
torch.nn.ReLU(),
torch.nn.Conv2d(16, 64, 3, 2),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU()
)
def forward(self, x):
return self.model(x)您可以使用 PyTorch 内置导出器,通过创建模型实例并调用torch.onnx.export将此模型导出到 ONNX 。还必须为虚拟输入提供适当的输入维度和数据类型,以及给定输入和输出的符号名称。
在代码示例中,我定义输入和输出的index 0是动态的,以便在运行时以不同的批大小运行模型。
import torch
model = Model().eval().to(device="cpu")
dummy_input = torch.rand((1, 3, 128, 128), device="cpu")
torch.onnx.export(
model,
dummy_input,
"model.onnx",
input_names=["input"],
output_names=["output"],
dynamic_axes={"input": {0: "N"}, "output": {0: "N"}},
opset_version=13
)在内部, PyTorch 调用torch.jit.trace,它使用给定的参数执行模型,并将执行期间的所有操作记录为有向图。
跟踪展开循环和 if 语句,生成与跟踪运行相同的静态图。没有捕获依赖于数据的控制流。这种导出类型适用于许多用例,但要记住这些限制。
如果需要动态行为,可以使用 scripting 。因此,在转换为 ONNX 之前,必须将模型导出到ScriptModule对象,如下例所示。
import torch
model = Model().eval().to(device="cpu")
dummy_input = torch.rand((1, 3, 128, 128), device="cpu")
scripted_model = torch.jit.script(model)
torch.onnx.export(
scripted_model,
dummy_input,
"model.onnx",
input_names=["input"],
output_names=["output"],
dynamic_axes={"input": {0: "N"}, "output": {0: "N"}},
opset_version=13
)将模型转换为ScriptModule对象并不总是简单的,通常需要一些代码更改。有关详细信息,请参见 Avoiding Pitfalls 和 TorchScript 。
由于前向调用中没有数据依赖关系,因此可以将模型转换为可编写脚本的模型,而无需对代码进行任何更改。
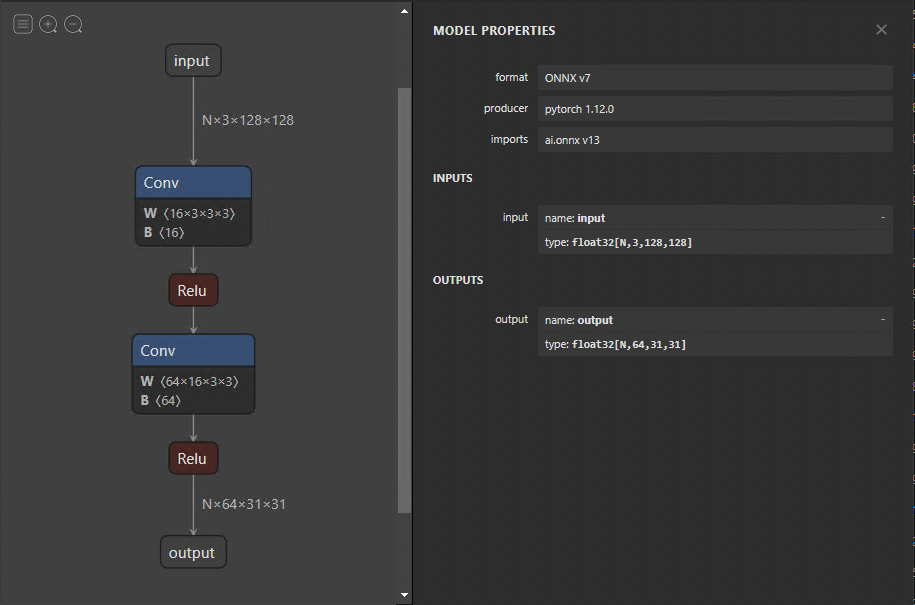
导出模型后,可以使用 Netron 将其可视化。默认视图提供模型图和属性面板(图 2 )。如果选择输入或输出,属性面板将显示常规信息,例如名称、OpSet和尺寸。
类似地,在图中选择节点会显示节点的属性。这是一种很好的方法,可以检查模型是否正确导出,以及以后调试和分析问题。
自定义运算符
目前, ONNX 定义了大约 150 个操作。它们的复杂性从算术加法到完整的长短期内存( LSTM )实现。尽管此列表随着每个新版本的增加而增加,但您可能会遇到不包括研究模型中的操作员的情况。
在这种情况下,您可以定义torch.autograd.Function,其中包括forward函数中的自定义功能和symbolic中的符号定义。在这种情况下,forward函数通过返回其输入来实现 no 操作。
class FooOp(torch.autograd.Function):
@staticmethod
def forward(ctx, input1: torch.Tensor) -> torch.Tensor:
return input1
@staticmethod
def symbolic(g, input1):
return g.op("devtech::FooOp", input1)
class FooModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.model = torch.nn.Sequential(
torch.nn.Conv2d(3, 16, 3, 2),
torch.nn.BatchNorm2d(16),
torch.nn.ReLU()
)
def forward(self, x):
x = self.model(x)
return FooOp.apply(x)
model = FooModel().eval().to(device="cpu")
dummy_input = torch.rand((1, 3, 128, 128), device="cpu")
torch.onnx.export(
model,
dummy_input,
"model_foo.onnx",
input_names=["input"],
output_names=["output"],
dynamic_axes={"input": {0: "N"}, "output": {0: "N"}},
opset_version=13,
)此示例演示如何定义用于将模型导出到 ONNX 的符号节点。尽管forward函数中提供了符号节点的功能,但必须将其实现并提供给用于推断 ONNX 模型的运行时。这是特定于执行提供程序的,稍后将在本文中讨论。
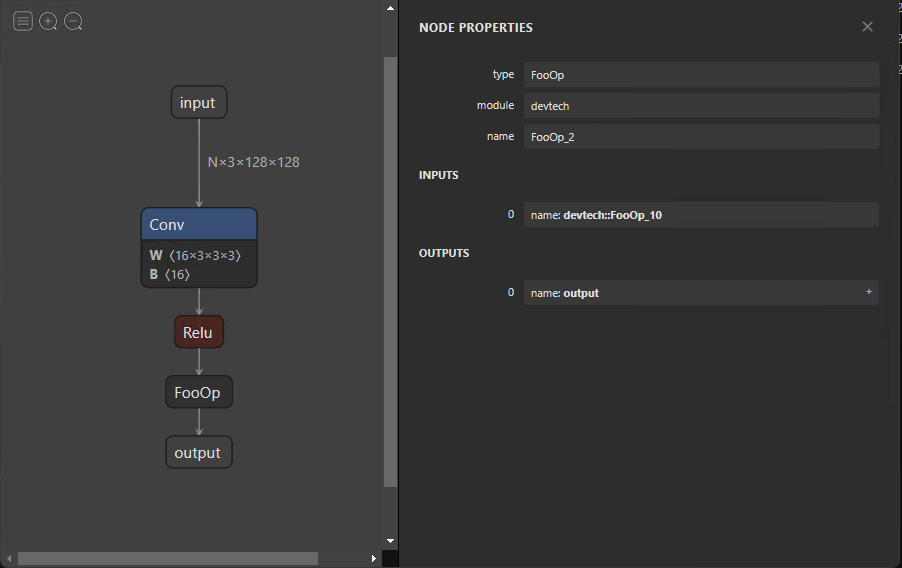
修改 ONNX 模型
您可能希望对 ONNX 模型进行更改,而无需再次导出。更改范围从更改名称到删除整个节点。直接修改模型是困难的,因为所有信息都被编码为协议缓冲区。幸运的是,您可以使用 GraphSurgeon 简单地更改模型。
下面的代码示例显示了如何从导出的模型中删除假FooOp节点。还有许多其他方法可以使用GraphSurgeon来修改和调试模型,我在这里无法介绍。有关详细信息,请参阅 GitHub repo 。
import onnx_graphsurgeon as gs
import onnx
graph = gs.import_onnx(onnx.load("model_foo.onnx"))
fake_node = [node for node in graph.nodes if node.op == "FooOp"][0]
# Get the input node of the fake node
# For example, node.i() is equivalent to node.inputs[0].inputs[0]
inp_node = fake_node.i()
# Reconnect the input node to the output tensors of the fake node, so that the first identity
# node in the example graph now skips over the fake node.
inp_node.outputs = fake_node.outputs
fake_node.outputs.clear()
# Remove the fake node from the graph completely
graph.cleanup()
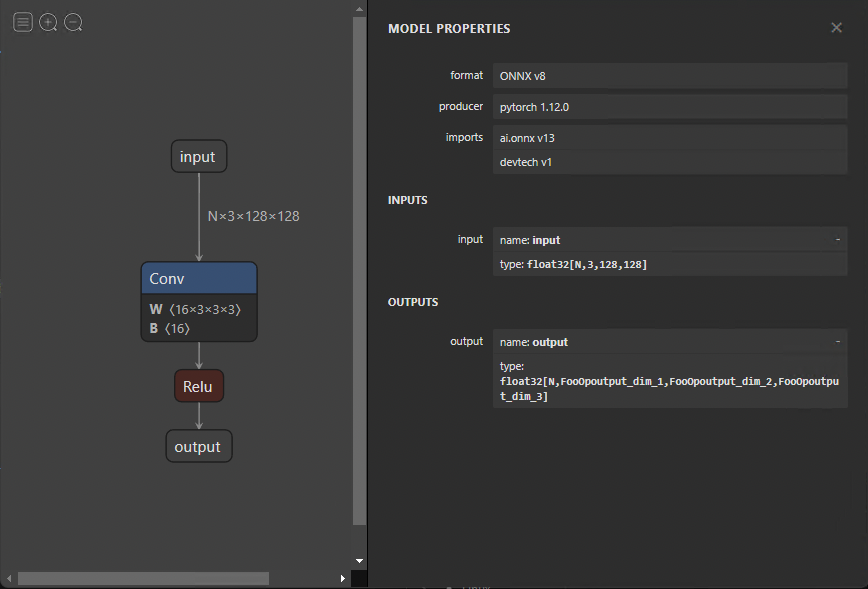
onnx.save(gs.export_onnx(graph), "removed.onnx")要删除节点,必须首先使用GraphSurgeon API 加载模型。接下来,遍历该图,查找要替换的节点,并将其与FooOp节点类型匹配。将其输入节点的输出张量替换为其自身的输出,然后移除其自身与输出的连接,从而移除该节点。
图 4 显示了结果图。
总结
本文介绍了使用 ONNX 运行时运行模型、模型优化和体系结构考虑。如果您对这些主题有任何进一步的问题,请联系 开发者论坛 或加入 NVIDIA Developer Discord 。
要阅读本系列的下一篇文章,请参阅 End-to-End AI for Workstation: ONNX Runtime and Optimization.
注册 了解有关使用 NVIDIA 技术加速您的创意应用程序的更多信息 。




