在生成式 AI 的动态领域,扩散模型脱颖而出,成为使用文本提示生成高质量图像的功能强大的架构 .Stable Diffusion 等模型彻底改变了创意应用。
但是,由于需要执行迭代降噪步骤,扩散模型的推理过程非常计算密集。这对致力于实现最佳端到端推理速度的公司和开发者带来了严峻挑战。
首先,NVIDIA TensorRT 9.2.0 引入了一款出色的量化工具包,支持FP8 或 INT8 预训练量化 (PTQ),显著提升了在 NVIDIA 硬件上部署扩散模型的速度,同时保持图像质量。TensorRT 的 8 位量化功能已成为众多生成式 AI 公司的首选解决方案,特别是对于领先的创意视频编辑应用程序提供商。
在本文中,我们讨论了 TensorRT 与 Stable Diffusion XL 的性能。我们介绍了支持 TensorRT 成为低延迟 Stable Diffusion 推理首选的技术差异。最后,我们展示了如何使用 TensorRT 通过几行代码加速模型。
基准测试
NVIDIA TensorRT INT8 和 FP8 量化方法适用于扩散模型,在 NVIDIA RTX 6000 Ada GPU 上的速度比原生 PyTorch 快 1.72 倍和 1.95 倍torch.compile在 FP16 中运行 .FP8 的额外加速主要归因于多头注意力 (MHA) 层的量化。使用 TensorRT 8 位量化,您可以增强生成式 AI 应用程序的响应速度并降低推理成本。
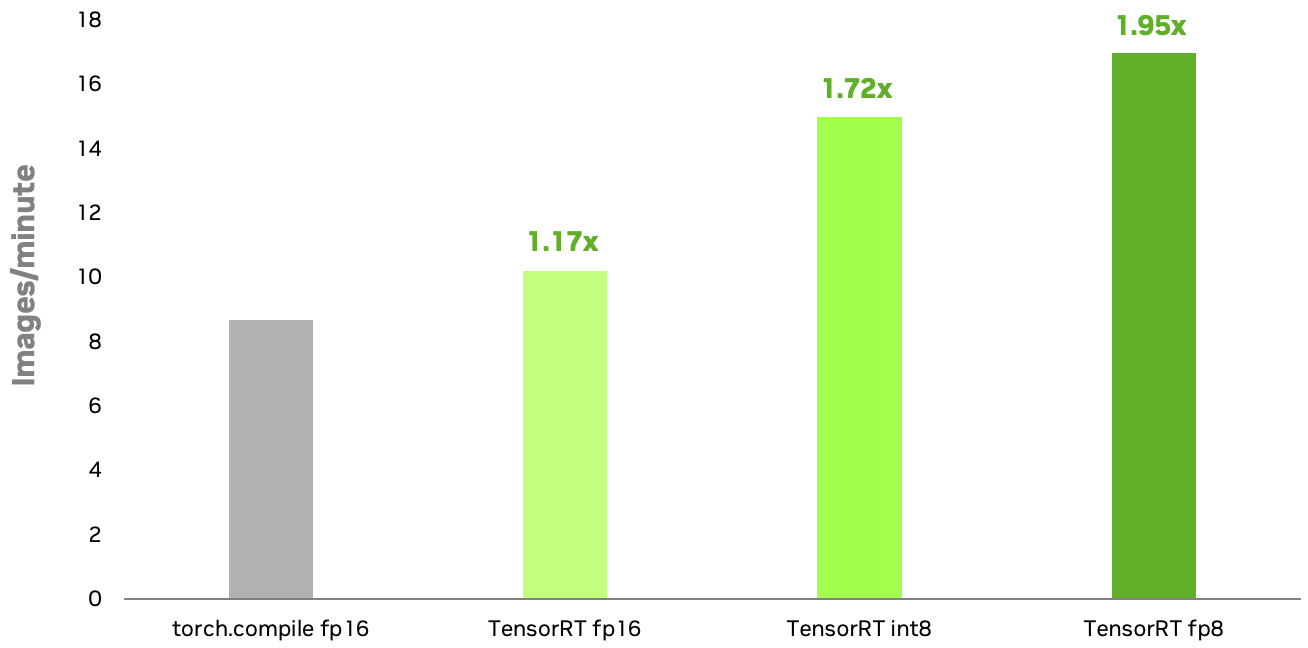
配置:Stable Diffusion XL 1.0 基础模型;图像分辨率=1024×1024;批量大小=1;Euler 调度程序适用于 50 个步骤; NVIDIA RTX 6000 Ada GPU.TensorRT INT8 量化现已推出,预计很快推出 FP8.基准测试可能会在发布时发生变化。
除了加快推理速度外,TensorRT 8 位量化还擅长保留图像质量。通过专有量化技术,它可以生成与原始 FP16 图像非常相似的图像。我们将在本文中后续部分介绍这些技术。

TensorRT 解决方案:克服推理速度挑战
虽然 PTQ 被认为是降低内存占用和加快 AI 任务推理速度的首选压缩方法,但它在扩散模型上不起作用。扩散模型具有独特的多时间步骤降噪过程,并且在每个时间步骤的噪声估计网络的输出分布可能会发生显著变化。这使得直观的 PTQ 校正方法无法使用。
在现有的技术中,SmoothQuant 是一种流行的 PTQ 方法,它为 LLM 实现了 8 位权重和 8 位激活(W8A8)量化。它的主要创新之处在于通过将量化挑战从激活转移到权重,并通过数学等效变换来解决激活异常问题。
尽管它很有效,但用户经常遇到在 SmoothQuant 中手动定义参数的困难。实践研究还发现,SmoothQuant 很难适应各种图像特征,从而限制了其在真实场景中的灵活性和性能。此外,其他现有的扩散模型量化技术仅适用于单个扩散模型的一个版本,而用户正在寻找一种通用方法,以加快各种模型版本的速度。
为了应对这些挑战, NVIDIA TensorRT 开发了一个精细的细粒度调整管线,以便为 SmoothQuant 确定每个模型层的最佳参数设置。您可以根据特定的特征图块开发自己的调整管线。此功能使 TensorRT 量化能够实现比现有方法更出色的图像质量,从而保留原始图像的丰富细节。
激活分布可能会在不同时间步长之间发生显著变化,而图像的形状和整体风格主要在降噪过程的初始阶段决定。因此,使用传统的最大校正会在初始步骤中产生大量量化错误。参见 Q-Diffusion 白皮书了解更多详情。
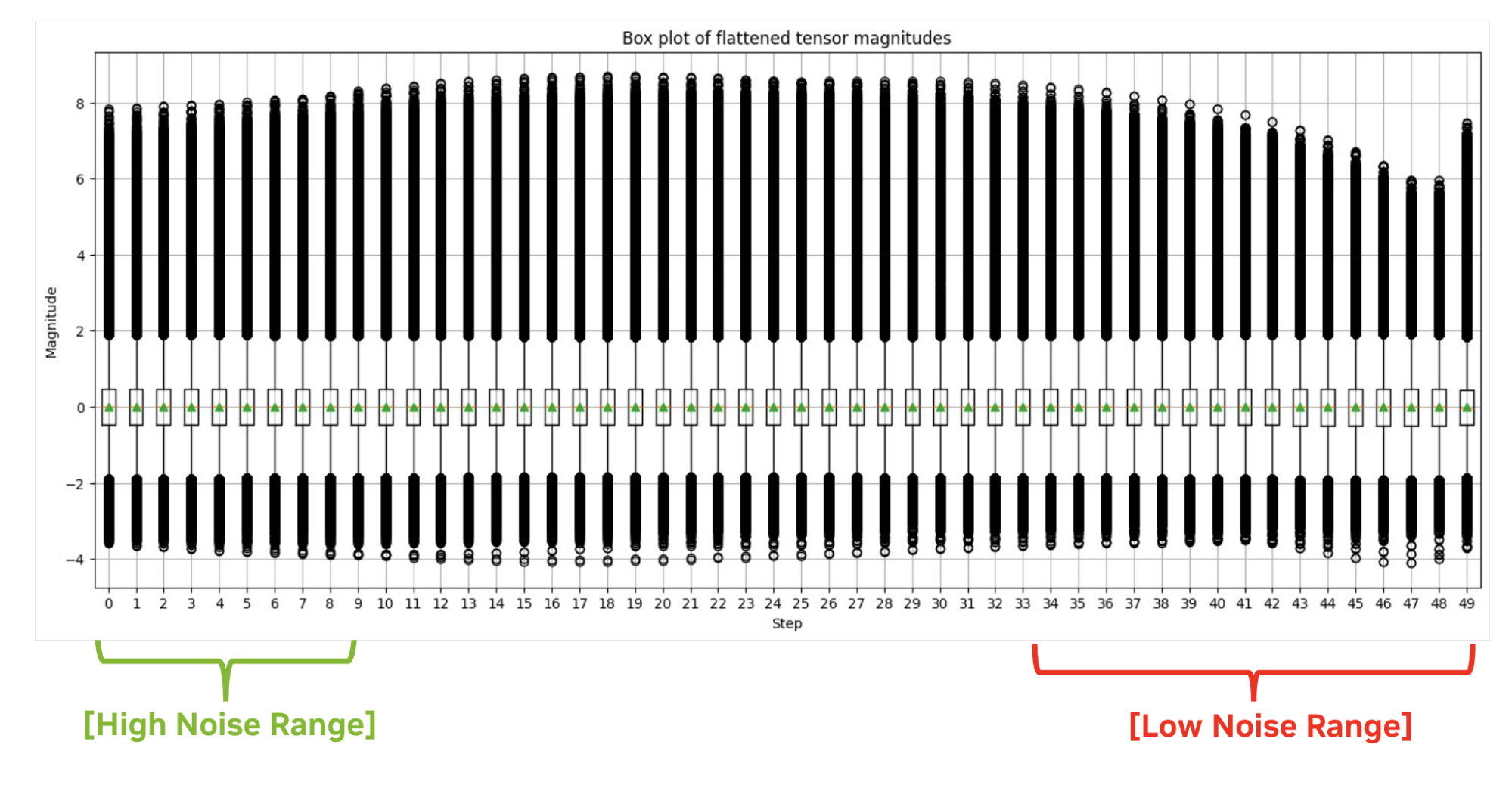
相反,我们选择性地使用选定步长范围中的最小量化扩展因子,因为我们发现激活值中的异常点对最终图像质量的影响并不大。这种定制方法我们称之为百分位数量重点关注步骤范围的重要百分比。它使 TensorRT 能够生成几乎与原始 FP16 精度相同的图像。

使用 TensorRT 8 位量化来加速扩散模型
这个 /NVIDIA/TensorRT GitHub repo 现在托管一个端到端、SDXL、8 位推理管道,提供一个现成的解决方案,在 NVIDIA GPU 上实现优化的推理速度。
运行一个命令,使用 Percentile Quant 生成图像,并使用 demoDiffusion 测量延迟。在本节中,我们使用 INT8 作为示例,但 FP8 的工作流程大致相同。
python demo_txt2img_xl.py "enchanted winter forest with soft diffuse light on a snow-filled day" --version xl-1.0 --onnx-dir onnx-sdxl --engine-dir engine-sdxl --int8 --quantization-level 3
以下是此命令的主要步骤概述:
- 校正
- 导出 ONNX
- 构建 TensorRT 引擎
校正
校正是量化过程中计算目标精度范围的步骤。目前,TensorRT 中的量化功能包含 nvidia-ammo,这是 TensorRT 8 位量化示例中包含的依赖项。
# Load the SDXL-1.0 base model from HuggingFace
import torch
from diffusers import DiffusionPipeline
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
)
base.to("cuda")
# Load calibration prompts:
from utils import load_calib_prompts
cali_prompts = load_calib_prompts(batch_size=2,prompts="./calib_prompts.txt")
# Create the int8 quantization recipe
from utils import get_percentilequant_config
quant_config = get_percentilequant_config(base.unet, quant_level=3.0, percentile=1.0, alpha=0.8)
# Apply the quantization recipe and run calibration
import ammo.torch.quantization as atq
quantized_model = atq.quantize(base.unet, quant_config, forward_loop)
# Save the quantized model
import ammo.torch.opt as ato
ato.save(quantized_model, 'base.unet.int8.pt')
导出 ONNX
获取量化模型检查点后,您可以导出 ONNX 模型。
# Prepare the onnx export
from utils import filter_func, quantize_lvl
base.unet = ato.restore(base.unet, 'base.unet.int8.pt')
quantize_lvl(base.unet, quant_level=3.0)
atq.disable_quantizer(base.unet, filter_func) # `filter_func` is used to exclude layers you don't quantize
# Export the ONNX model
from onnx_utils import ammo_export_sd
base.unet.to(torch.float32).to("cpu")
ammo_export_sd(base, 'onnx_dir', 'stabilityai/stable-diffusion-xl-base-1.0')
构建 TensorRT 引擎
利用 INT8 UNet ONNX 模型,您可以 创建 TensorRT 引擎。
trtexec --onnx=./onnx_dir/unet.onnx --shapes=sample:2x4x128x128,timestep:1,encoder_hidden_states:2x77x2048,text_embeds:2x1280,time_ids:2x6 --fp16 --int8 --builderOptimizationLevel=4 --saveEngine=unetxl.trt.plan
总结
在生成式 AI 时代,拥有优先考虑易用性的推理解决方案至关重要。借助 NVIDIA TensorRT,您可以通过其专有的 8 位量化技术实现高达 2 倍的推理速度提升,同时确保图像质量不受影响,从而提供出色的用户体验。
TensorRT 致力于平衡速度和质量,凸显其在加速 AI 应用方面的领先地位,让您轻松提供尖端解决方案。
注册参加 关于量化的 GTC 会议,以了解更多关于优化生成式 AI 模型推理速度和模型压缩的信息。如果您正在使用基于 LLM 的应用程序,我们鼓励您探索 如何利用 TensorRT-LLM 及其先进的量化技术加速推理过程。
有关更多信息,请参阅以下资源:
- NVIDIA GTC 2024 上的热门会议:LLM 推理
- NVIDIA TensorRT-LLM 加速 Google Gemma 的推理
- TensorRT SDK
- /NVIDIA/TensorRT-LLM GitHub 资源库