
这篇文章是优化工作站端到端人工智能系列文章的第三篇。有关更多信息,请参见第 1 部分, 工作站端到端 AI :优化简介 和第 2 部分, 工作站端到端 AI :使用 ONNX 转换 AI 模型 .
当您的模型转换为 ONNX 格式时,有几种方法可以部署它,每种方法都有优缺点。
一种方法是使用 ONNX Runtime 。 ONNX 运行时充当后端,从中间表示( ONNX )读取模型,处理推理会话,并在能够调用硬件特定库的执行提供程序上调度执行。有关详细信息,请参见 Execution Providers 。
在这篇文章中,我将讨论如何在高级别上使用 ONNX 运行时。我还深入探讨了如何优化模型。
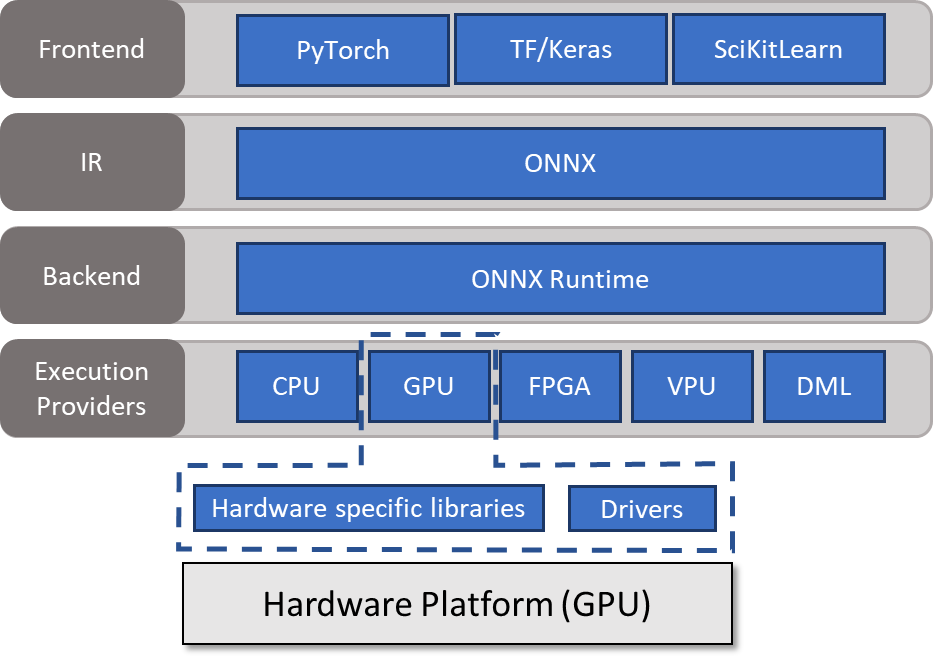
使用 ONNX 运行时运行模型
ONNX Runtime 与大多数编程语言兼容。与另一篇文章一样,本文使用 Python 是为了简洁和易读。这些例子只是为了介绍关键思想。有关所有流行操作系统、编程语言和执行提供程序的库的更多信息,请参阅 ONNX Runtime 。
要使用 ONNX Runtime 推断模型,必须创建InferenceSession类的对象。此对象负责分配缓冲区并执行实际的推理。将加载的模型和要使用的执行提供程序列表传递给构造函数。在本例中,我选择了 CUDA 执行提供程序。
import onnxruntime as rt
# Create a session with CUDA and CPU ep
session = rt.InferenceSession(model,
providers=['CUDAExecutionProvider',
'CPUExecutionProvider']
)您可以定义会话和提供程序选项。 ONNX 运行时的全局行为可以使用日志记录、分析、内存策略和图形参数的会话选项进行修改。有关所有可用标志的更多信息,请参见 SessionOptions 。
以下代码示例将日志记录级别设置为 verbose :
# Session Options
import onnxruntime as rt
options = rt.SessionOptions()
options.log_severity_level = 0
# Create a session with CUDA and CPU ep
session = rt.InferenceSession(model,
providers=['CUDAExecutionProvider',
'CPUExecutionProvider'],
sess_options = options
)使用提供程序选项更改已选择用于推断的执行提供程序的行为。有关详细信息,请参见 ONNX Runtime Execution Providers 。
您还可以通过在新创建的会话上执行get_provider_options来获得可用选项:
provider_options = session.get_provider_options()
print(provider_options)运行模型
构建会话后,必须生成输入数据,然后才能将其绑定到 ONNX 运行时。然后,您可以在会话上调用run,向其传递一个输出名称列表以及一个包含输入名称作为键和 ONNX 运行时绑定作为值的字典。
# Generate data and bind to ONNX Runtime
input_np = np.random.rand((1,3,256,256))
input_ort = rt.OrtValue.ortvalue_from_numpy(input_np)
# Run model
results = session.run(["output"], {"input": input_ort})默认情况下, ONNX Runtime 始终将输入和输出放置在 CPU 上。因此,在主机和设备之间不断复制缓冲区,您应该尽可能避免这种情况。使用和重用设备生成的缓冲区是可行的。
模型优化
为了从推理中获得最佳性能,我建议您使用硬件专用加速器: Tensor Cores 。
在 NVIDIA RTX 硬件上,从 NVIDIA Volta 架构(计算能力 7.0 +)向前, GPU 包括 Tensor 核心,以加速深度学习所涉及的一些重载操作。
本质上, Tensor 核心支持一种称为扭曲矩阵乘法累加( WMMA )的操作,为基于 FP16 的( HMMA )和基于整数的乘法累加( IMMA )提供优化路径。
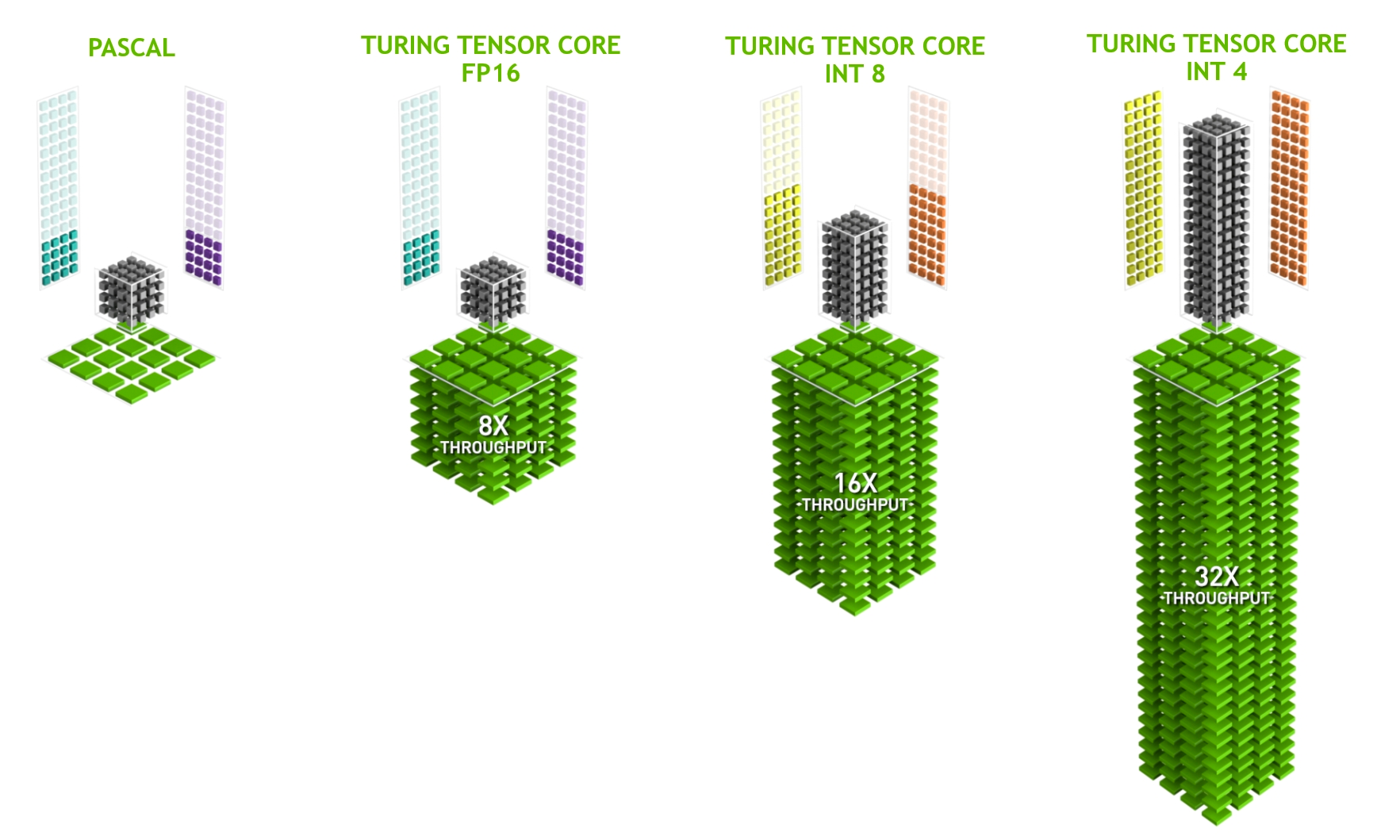
精度转换
使用 Tensor Core 的第一步是将模型导出到 FP16 或 INT8 的较低精度。在大多数情况下, INT8 提供最佳性能,但它有两个缺点:
- 您必须重新校准或量化权重。
- 精度可能更差。
第二点取决于您的应用程序。然而,当使用 INT8 输入和输出数据(如照片)时,其后果往往可以忽略不计。
另一方面, FP16 不需要重新校准重量。在大多数情况下,其精度与 FP32 相似。要将给定的 ONNX 模型转换为 FP16 ,请使用 onnx_converter_common 工具箱。
import onnx
from onnxconverter_common.float16 import convert_float_to_float16
model_fp32 = onnx.load("model.onnx")
model_fp16 = convert_float_to_float16(copy.deepcopy(model_fp32))
onnx.save(model_fp16, "model_fp16.onnx")如果原始模型中的权重超过 FP16 的动态范围,则会出现溢出。使用自动混合精度(amp)导出器可以克服任何不希望的行为。这会将模型的 Ops 逐一转换为 FP16 ,在每次更改后检查其准确性,以确保增量在预定义的公差范围内。否则, Op 保存在 FP32 中。
这种类型的转换还需要两件事:
- 一个 输入馈送字典 ,包含作为键的输入名称和作为值的数据。重要的是,提供的数据在正确的数据范围内,尽管最好使用实际的推断数据。
- A validation function 以比较结果是否在可接受的误差范围内。在本例中,我实现了一个简单的函数,如果两个数组在公差范围内按元素相等,则返回 true 。
import onnx
import numpy as np
from onnxconverter_common.auto_mixed_precision import auto_convert_mixed_precision
# Could also use rtol/atol attributes directly instead of this
def validate(res1, res2):
for r1, r2 in zip(res1, res2):
if not np.allclose(r1, r2, rtol=0.01, atol=0.001):
return False
return True
model_fp32 = onnx.load("model.onnx")
feed_dict = {"input": 2*np.random.rand(1, 3, 128, 128).astype(np.float32)-1.0}
model_amp = auto_convert_mixed_precision(model_fp32, feed_dict, validate)
onnx.save(model_amp, "model_amp.onnx")在从 FP32 到 FP16 的转换过程中,除了动态范围之外,仍然存在可能的问题。可能会在模型中插入不必要或不需要的强制转换操作。您必须手动检查。
体系结构注意事项
数据和权重必须采用正确的布局。 Tensor Core 使用 NHWC 格式的数据。正如我前面提到的, ONNX 只支持 NCHW 格式。然而,这不是问题,因为后端在 Tensor Core 合格操作之前插入转换内核。
让后端处理布局可能会导致性能损失。由于并非所有操作都支持 NHWC 格式,因此在整个模型中可能存在多个 NCHW-NHWC 转换和相反的转换。它们的运行时间很短,但在重复执行时,弊大于利。尝试通过分析模型来避免模型中的显式布局转换。
所有操作都应使用尺寸倍数为 8 (最佳为 32 )的过滤器,以满足 Tensor Core 的要求。这涉及到实际的模型体系结构,在设计模型时应记住这一点。
当您使用 NVIDIA TensorRT 时,过滤器会自动填充,以适合 Tensor Core 消费。尽管如此,调整模型架构可能会更好。无论如何,额外的维度都是计算出来的,可能会提供改进特征提取的潜力
作为第三项要求, GEM 运营必须大步向前。这意味着步幅不能超过过滤器大小。
全体的
ONNX 运行时包括几个图形优化以提高性能。图形优化本质上是图形级别的改变,从简单的图形简化和节点消除到更复杂的节点融合和布局转换。
在 ONNX 运行时中,它们分为以下级别:
- Basic: 这些优化涵盖了所有保留语义的修改,如常量折叠、冗余节点消除和有限数量的节点融合。
- Extended: 扩展优化仅在运行 CPU 或 CUDA 执行提供程序时适用。它们包括更复杂的融合。
- Layout optimizations: 这些布局转换仅适用于在 CPU 上运行。
有关可用融合和适用优化的更多信息,请参见 Graph Optimizations in ONNX Runtime 。
当在 TensorRT 执行提供程序上运行时,这些优化并不相关,因为[ZDK4 使用内置优化器,该优化器使用多种融合和内核调谐器。
联机或脱机
所有优化都可以在线或离线执行。当以联机模式启动推理会话时, ONNX 运行时会在模型推理开始之前运行所有已启用的图形优化。
每次会话启动时应用所有优化可能会增加模型启动时间,特别是对于复杂模型。在这种情况下,离线模式可能是有益的。图形优化完成后, ONNX 运行时将最终模型以脱机模式保存到磁盘。使用现有的优化模型并删除所有优化可以减少每次连续启动的启动时间。
总结
本文介绍了使用 ONNX 运行时运行模型、模型优化和体系结构考虑。如果您对这些主题有任何进一步的问题,请联系 NVIDIA Developer Forums 或加入 NVIDIA Developer Discord 。
要阅读本系列的第一篇文章,请参见 End-to-End AI for Workstation: An Introduction to Optimization .
注册 learn more about accelerating your creative application with NVIDIA technologies 。




