DEVELOPER
首页
博客
论坛
文档
下载
社区研讨会
培训
搜索
Join
Inference
2023年 4月 5日
通过 AI 的全栈优化在 MLPerf 推理 v3.0 中创下新纪录
目前最令人兴奋的计算应用程序依赖于在复杂的人工智能模型上进行训练和运行推理,通常是在要求苛刻的实时部署场景中。需要高性能、
5 MIN READ
通过 AI 的全栈优化在 MLPerf 推理 v3.0 中创下新纪录
2023年 4月 4日
使用 Dataiku 和 NVIDIA Data Science 进行主题建模和图像分类
这个Dataiku platform日常人工智能简化了深度学习。用例影响深远,从图像分类到对象检测和自然语言处理( NLP )。
4 MIN READ
使用 Dataiku 和 NVIDIA Data Science 进行主题建模和图像分类
2023年 3月 29日
利用三维合成数据进行自举目标检测模型训练
训练人工智能模型需要大量的数据。获取大量训练数据可能很困难、耗时且成本高昂。此外,所收集的数据可能无法涵盖各种角落的情况,
4 MIN READ
利用三维合成数据进行自举目标检测模型训练
2023年 3月 23日
使用新的 NVIDIA Triton 和 NVIDIA TensorRT 功能为您的 AI 推理提供动力
NVIDIA AI 推理软件包括NVIDIA Triton 推理服务器,开源推理服务软件,以及NVIDIA TensorRT,
1 MIN READ
使用新的 NVIDIA Triton 和 NVIDIA TensorRT 功能为您的 AI 推理提供动力
2023年 3月 21日
NVIDIA L4 GPU 实现 AI 视频和 AI 推理性能的超级充电
NVIDIA T4 于 4 年前作为通用 GPU 引入主流服务器。 T4 GPU 已被广泛采用,
3 MIN READ
NVIDIA L4 GPU 实现 AI 视频和 AI 推理性能的超级充电
2023年 3月 15日
适用于基于 NVIDIA 的 PC 的端到端人工智能: NVIDIA TensorRT 部署
这篇文章是关于 优化端到人工智能 的系列文章中的第五篇。 NVIDIA TensorRT 是一种在 NVIDIA…
2 MIN READ
适用于基于 NVIDIA 的 PC 的端到端人工智能: NVIDIA TensorRT 部署
2023年 3月 13日
使用集成模型在 NVIDIA Triton 推理服务器上为 ML 模型管道提供服务
在许多生产级机器学习( ML )应用程序中,推理并不局限于在单个 ML 模型上运行前向传递。相反,通常需要执行 ML 模型的管道。例如,
4 MIN READ
使用集成模型在 NVIDIA Triton 推理服务器上为 ML 模型管道提供服务
2023年 2月 8日
基于 NVIDIA 的 PC 的端到端 AI : ONNX Runtime 中的 CUDA 和 TensorRT 执行提供程序
这篇文章是 optimizing end-to-end AI 系列文章的第四篇。 有关更多信息,请参阅以下帖子:
2 MIN READ
基于 NVIDIA 的 PC 的端到端 AI : ONNX Runtime 中的 CUDA 和 TensorRT 执行提供程序
2023年 2月 2日
针对 NVIDIA GPU 的低延迟交易和快速回测的深度神经网络基准
降低对新市场事件的响应时间是算法交易的一个驱动力。对延迟敏感的交易公司通过在其系统中部署诸如现场可编程门阵列( FPGA )和专用集成电路(…
2 MIN READ
针对 NVIDIA GPU 的低延迟交易和快速回测的深度神经网络基准
2023年 1月 25日
关于扩展 AI 训练和推理存储的提示
GPU 在扩展 AI 方面有许多好处,从更快的模型训练到 GPU 加速的欺诈检测。在规划 AI 模型和部署应用程序时,必须考虑可扩展性挑战,
2 MIN READ
关于扩展 AI 训练和推理存储的提示
2022年 12月 19日
使用 NVIDIA Triton 推理服务器从公共库 ModelZoo 部署不同的 AI 模型类别
如今,针对 TensorFlow 、 ONNX 、 PyTorch 、 Keras 、 MXNet 等不同框架,出现了大量最先进( SOTA…
4 MIN READ
使用 NVIDIA Triton 推理服务器从公共库 ModelZoo 部署不同的 AI 模型类别
2022年 12月 16日
使用 NVIDIA TensorRT 在 Apache Beam 中简化和加速机器学习预测
为大规模运行机器学习模型而加载和预处理数据通常需要将数据处理框架和推理机无缝拼接在一起。 在这篇文章中,
4 MIN READ
使用 NVIDIA TensorRT 在 Apache Beam 中简化和加速机器学习预测
2022年 12月 15日
工作站端到端 AI :优化简介
这篇文章是优化工作站端到端人工智能系列文章的第一篇。有关更多信息,请参见第 2 部分, 工作站端到端 AI : 使用 ONNX 转换 AI…
2 MIN READ
工作站端到端 AI :优化简介
2022年 12月 15日
工作站端到端 AI :使用 ONNX 转换 AI 模型
这篇文章是优化工作站端到端人工智能系列文章的第二篇。有关更多信息,请参见第 1 部分, 工作站端到端 AI : 优化简介 和第 3 部分,
3 MIN READ
工作站端到端 AI :使用 ONNX 转换 AI 模型
2022年 12月 15日
工作站端到端 AI : ONNX 运行时和优化
这篇文章是优化工作站端到端人工智能系列文章的第三篇。有关更多信息,请参见第 1 部分, 工作站端到端 AI :优化简介 和第 2 部分,
2 MIN READ
工作站端到端 AI : ONNX 运行时和优化
2022年 11月 30日
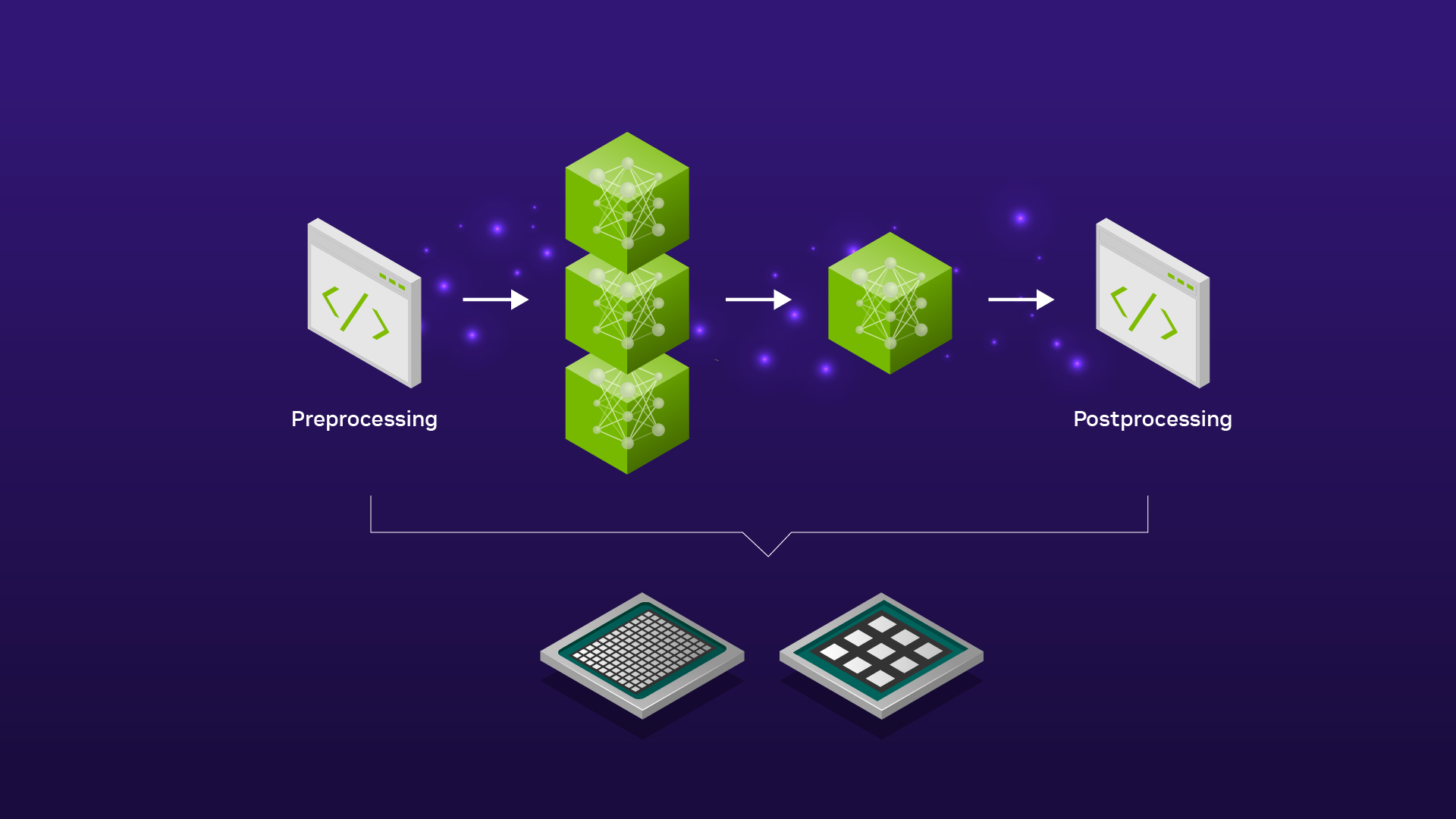
自动驾驶的最优 AI 推理流水线设计
自动驾驶汽车必须能够快速准确地检测物体,以确保其驾驶员和道路上其他驾驶员的安全。由于自动驾驶( AD )和视觉检查用例中对实时处理的需求,
3 MIN READ
自动驾驶的最优 AI 推理流水线设计
加载更多