
고성능 컴퓨팅(HPC)은 과학적 발견의 필수적인 수단이 되었습니다.
신약을 발견하든, 기후 변화에 맞서 싸우든, 정확한 세계 시뮬레이션을 만들든, 이러한 솔루션은 엄청난 양으로 빠르게 성장하는 처리 성능을 요구합니다. 기존의 컴퓨팅 접근 방식으로는 갈수록 어려워지고 있습니다.
이것이 산업계가 NVIDIA GPU 가속 컴퓨팅을 수용한 이유입니다. AI와 결합된 가속 컴퓨팅은 과학 발전을 위한 성능이 수백만 배 향상되었습니다. 오늘날 2,700개의 애플리케이션이 NVIDIA GPU 가속화의 이점을 누릴 수 있으며, 성장 중인 3백만 명의 개발자로 구성된 커뮤니티에서 이를 뒷받침하는 가운데 애플리케이션의 수는 계속 증가하고 있습니다.
HPC 애플리케이션 성능 개선
전체 HPC 애플리케이션 전반에 걸쳐 몇 배의 속도 향상을 제공하려면 스택의 모든 수준에서 끊임없는 혁신이 필요합니다. 칩과 시스템에서 시작해 애플리케이션 프레임워크까지 관통합니다.
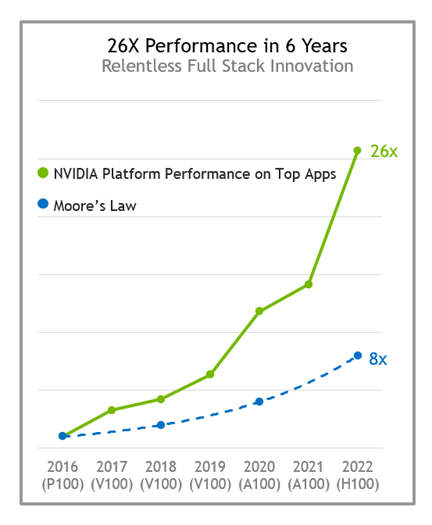
NVIDIA 플랫폼은 아키텍처와 NVIDIA 소프트웨어 스택 전반에서 끊임없이 발전하면서 매년 상당한 성능 향상을 지속적으로 제공하고 있습니다. 불과 6년 전에 출시된 P100과 비교해 보면 H100 Tensor 코어 GPU는 무어의 법칙보다 3배 이상 빠른 약 26배 높은 성능을 제공할 것으로 예상됩니다.
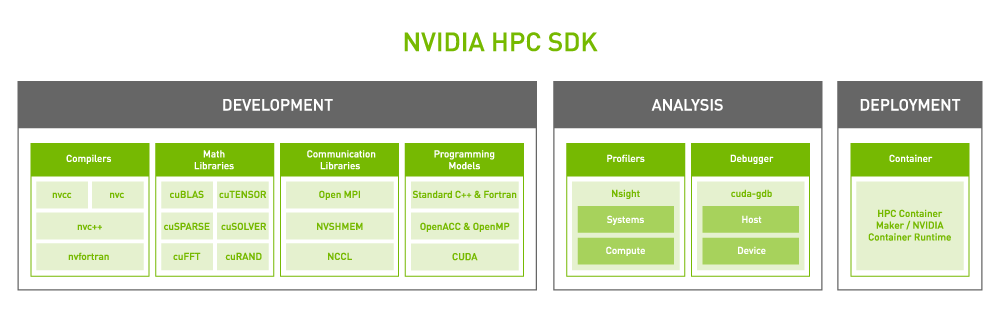
NVIDIA 플랫폼의 코어는 기능이 풍부한 고성능 소프트웨어 스택입니다. 이 플랫폼에는 가장 광범위한 HPC 애플리케이션의 GPU 가속화를 용이하게 하기 위해 NVIDIA HPC SDK가 포함되어 있습니다. SDK는 비교할 수 없는 개발자 유연성을 제공하여 표준 언어, 지시문 및 CUDA를 사용하여 GPU 가속화 애플리케이션을 생성하고 포팅하도록 지원합니다.
NVIDIA HPC SDK의 성능은 고도로 최적화된 GPU 가속 수학 라이브러리의 방대한 제품군에 내장되어 있어 NVIDIA GPU의 잠재력을 최대한 활용할 수 있습니다. 최상의 멀티 GPU 및 다중 노드 성능을 위해 NVIDIA HPC SDK는 강력한 통신 라이브러리도 제공합니다.
- NVSHMEM은 여러 GPU의 메모리에 걸친 데이터를 위한 전역 주소 공간을 만듭니다.
- NVIDIA Collective Communications Library(NCCL)는 GPU 간 통신을 최적화합니다.
이 플랫폼은 규모가 크고 계속 성장하는 GPU 가속 HPC 애플리케이션의 세계를 지원하기 위한 최고의 성능과 유연성을 제공합니다.
HPC 성능 및 에너지 효율성
NVIDIA 풀 스택 혁신이 가속화된 HPC를 위한 최고의 성능을 이끌어내는 방법을 보여주고자 NVIDIA GPU 4개를 갖춘 HPE 서버와 동일한 수의 가속기 모듈을 기반으로 비슷하게 구성된 다른 벤더의 서버 성능을 비교했습니다.
광범위한 데이터세트를 사용하여 널리 사용되는 5가지 HPC 애플리케이션 세트를 테스트했습니다. NVIDIA 플랫폼은 모든 산업에 걸쳐 2,700개의 애플리케이션을 가속화하지만, 이 비교에서 사용할 수 있는 애플리케이션은 다른 벤더의 가속기에서 사용할 수 있는 소프트웨어 및 애플리케이션 버전으로 제한되었습니다.
분자 역학 시뮬레이션을 위한 소프트웨어인 NAMD를 제외한 모든 워크로드의 경우, NVIDIA의 결과는 여러 데이터세트의 결과의 기하 평균을 사용하여 계산됨으로써 이상치의 영향을 최소화하고 고객 경험을 대표합니다.
또한 멀티 GPU 및 단일 GPU 시나리오에서 이러한 애플리케이션을 테스트했습니다.
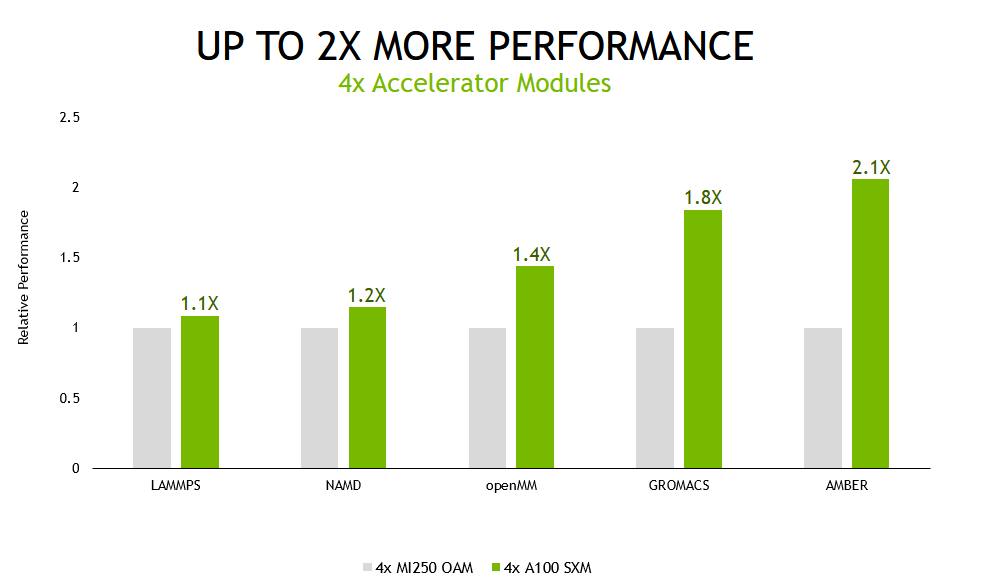
멀티 GPU 시나리오에서 테스트된 시스템의 모든 가속기가 단일 시뮬레이션을 실행하는 데 사용되면서 A100 Tensor 코어 GPU 기반 서버는 다른 제품보다 최대 2.1배 더 높은 성능을 제공했습니다.
컴퓨팅 성능의 지속적인 발전에 힘입어 분자 동역학 분야는 더욱 긴 시간 동안 더욱 거대한 원자 시스템을 시뮬레이션하는 방향으로 나아가고 있습니다.이러한 발전 덕분에 연구원들은 광합성 전자 전송 및 시각 신호 전달과 같은 증가하는 생화학 메커니즘 세트를 시뮬레이션할 수 있도록 지원합니다.이러한 프로세스는 검증의 주요 도구인 시뮬레이션의 범위를 벗어나기 때문에 오랫동안 과학적 논쟁의 대상이 되어 왔습니다. 그 이유는 시뮬레이션을 완료하는 데 아주 오랜 시간이 필요하기 때문입니다.
하지만 NVIDIA는 이러한 모든 사용자가 애플리케이션을 시뮬레이션당 여러 개의 GPU로 실행하는 것은 아니라는 것을 알게 됐습니다.최적의 처리량을 위한 최상의 실행 방법은 시뮬레이션당 하나의 GPU를 할당하는 것입니다.
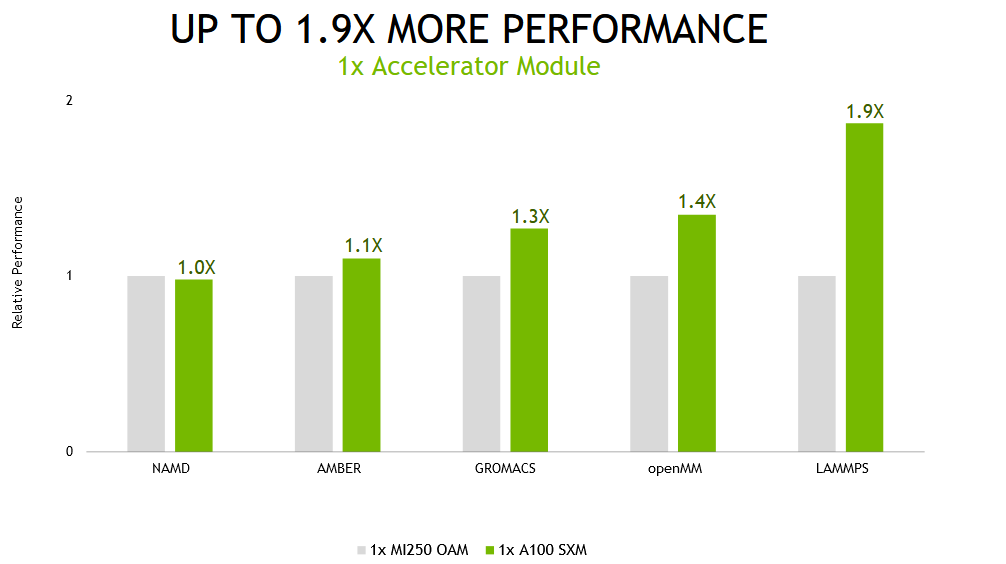
단일 가속기 모듈에서 동일한 애플리케이션을 실행할 때(NVIDIA A100의 풀 GPU와 대체 제품의 두 컴퓨트 다이) NVIDIA A100 기반 시스템은 최대 1.9배 빠른 성능을 제공합니다.
에너지 비용은 데이터센터 및 슈퍼컴퓨팅 센터 전체 소유 비용(TCO)의 상당 부분을 차지하며, 전력 효율이 높은 컴퓨팅 플랫폼의 중요성을 강조합니다.NVIDIA의 테스트 결과 NVIDIA 플랫폼은 다른 제품보다 와트당 최대 2.8배 높은 처리량을 제공하는 것으로 나타났습니다.

MI250 대비 A100의 전력 효율 – 높을수록 NVIDIA에 좋습니다. 여러 데이터세트에 대한 애플리케이션당 기하 평균(서로 다름) 효율성은 NVIDIA SMI 및 ROCm의 동급 기능을 사용하여 GPU에 대해 측정된 성능/전력 소모량(와트)입니다. |
AMD MI250은 AMD Infinity Fabric™ 기술이 적용된 AMD Instinct™ MI250 OAM(128GB HBM2e) 500W GPU를 4개와 (2) AMD EPYC 7763를 탑재한 MI250 시스템에서 측정되었습니다. NVIDIA는 듀얼 EPYC 7713 CPU와 A100(80GB) SXM4 4개를 사용하는 HGX A100 4-GPU 서버에서 실행됩니다.
LAMMPS develop_db00b49(AMD) develop_2a35ec2(NVIDIA) 데이터세트 ReaxFF/c, Tersoff, Leonard-Jones, SNAP | NAMD 3.0alpha9 데이터세트 STMV_NVE | OpenMM 7.7.0 Ensemble은 다음 데이터세트를 위해 실행됩니다. amber20-stmv, amber20-cellulose, apoa1pme, pme|
GROMACS 2021.1(AMD) 2022(NVIDIA) 데이터세트 ADH-Dodec(h-bond), STMV(h-bond) | AMBER 20.xx_rocm_mr_202108(AMD) 및 20.12-AT_21.12(NVIDIA) 데이터세트 Cellulose_NVE, STMV_NVE | MI250 1개에는 GCD가 2개 있음
NVIDIA A100 GPU의 우수한 성능과 전력 효율성은 애플리케이션 성능과 효율성을 극대화하기 위해 수년 동안 끈질기게 수행한 소프트웨어 하드웨어 공동 최적화의 결과입니다. NVIDIA Ampere 아키텍처에 대한 자세한 내용은 NVIDIA A100 Tensor 코어 GPU 백서를 참조하십시오.
또한 A100은 운영 체제의 단일 프로세서로 제공되기 때문에 성능을 최대한 활용하기 위해 단 하나의 MPI 차수만 시작하도록 요구합니다. 그리고 A100은 노드의 모든 GPU 간 600GB/s NVLink 연결 덕분에 탁월한 대규모 성능을 제공합니다.
AI 및 HPC 융합
가속 컴퓨팅이 모델링 및 시뮬레이션 애플리케이션에 몇 배의 가속을 제공하는 것처럼, AI와 HPC 조합은 성능을 한 단계 높여 차세대 과학 발견의 길을 열어 줄 것입니다.
NVIDIA 플랫폼은 첫 MLPerf 학습 제출부터 최신 결과까지 3년 동안 이 업계 표준 동료 평가 벤치마크 제품군에서 20배 더 높은 딥 러닝 학습 성능을 실현했습니다. 이러한 우위는 칩, 소프트웨어, 규모 향상이 결합된 결과입니다.
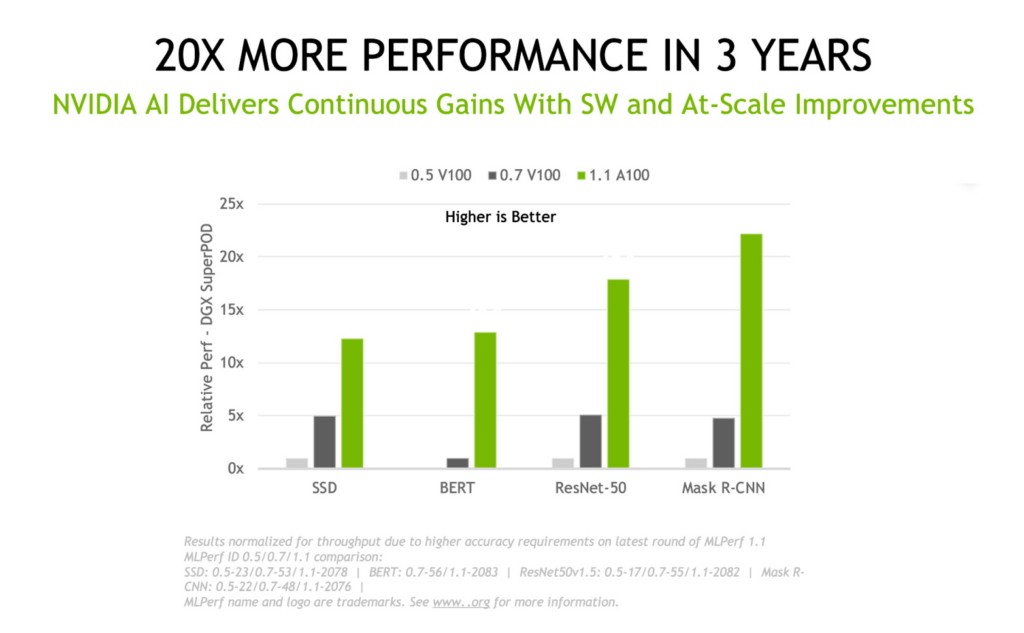
과학자와 연구원은 이미 AI의 성능을 이용하여 성능의 극적인 향상을 실현하고 과학적 발견을 가속화하고 있습니다.
- 중력파 식별에 걸리는 시간을 105 절감.
- 10억 개 이상의 원자가 있는 비말에서 Delta SARS-CoV-2 바이러스 시뮬레이션을 위한 1,000배 속도 향상 제공.
- 청정 융합 에너지의 개발 가속화.
- 배열회수 증기 발생기(HRSG) 식물을 위한 예측적 디지털 트윈 생성.
전 세계 슈퍼컴퓨팅 센터가 계속해서 가속화된 AI 슈퍼컴퓨터를 채택하고 있습니다.
- Argonne Leadership Computing Facility(ALCF)의 Polaris 슈퍼컴퓨터. NERSC의 Perlmutter, CINECA의 Leonardo는 모두 A100 Tensor Core GPU를 사용합니다.
- 출시 예정인 Grace Hopper Superchip을 기반으로 하는 Alps 슈퍼컴퓨터는 2023년에 가동될 예정입니다.
- 2023년에 제공될 예정인 Los Alamos National Laboratory의 Venado 시스템에는 Grace Hopper Superchip과 Grace CPU Superchip 노드가 모두 포함됩니다.
최신 성능 데이터에 대한 자세한 내용은 HPC 애플리케이션 성능을 참조하십시오.