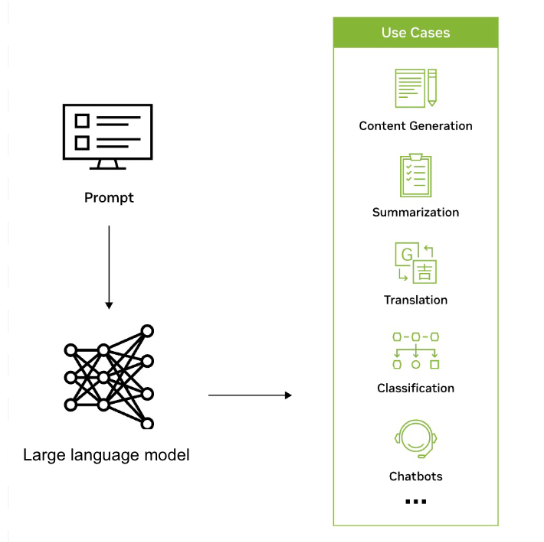
大規模言語モデル (LLM: Large :Language Models) は、数千億のパラメーターを持つインターネット規模のデータセットで学習されるディープラーニングのアルゴリズムです。LLM は、読み、書き、コーディング、描画、そして人間の創造性を補強することで、様々な業界の生産性を向上させ、世界で最も困難な問題を解決することができます。
LLM は、小売業から医療まで幅広い業界で、幅広い業務に使用されています。LLM は、科学者が命を救う画期的なワクチンを開発するのに役立つ、新しい化合物を生成するための、タンパク質配列の言語を学習します。LLM は、ソフトウェア プログラマが自然言語の記述に基づいてコードを生成し、バグを修正するのを助けます。そして、人間が最も得意とすること、すなわち創造、質問、理解など、生産性向上の為の副操縦士的な役割を提供します。
企業向けのアプリケーションやワークフローで LLM を効果的に活用するには、モデルの選択、カスタマイズ、最適化、デプロイといった重要なトピックを理解する必要があります。この記事では、企業向け LLM に関する以下のトピックについて説明します。
- 組織はどのように LLM を利用しているか
- LLM をそのまま使うか、カスタマイズするか、構築するか?
- 基盤モデルから始める
- カスタム言語モデルを構築する
- LLM を外部データに接続する
- LLM を安全に軌道に乗せる
- 本番利用における LLM 推論の最適化
- LLM を使い始める
カスタム モデルを構築しようとしているデータ サイエンティストの方も、組織における LLM の可能性を探っているチーフ データ オフィサーの方も、是非貴重なインサイトとガイダンスについてお読みください。
組織はどのように LLM を利用しているか
LLM は、膨大なデータセットから得られた知識に基づいて、テキストやその他の形式のコンテンツを効率的に認識、要約、翻訳、予測、生成するために、業界を問わずさまざまなアプリケーションで使用されています。例えば、企業は LLM を活用してチャットボットのようなインターフェイスを開発し、顧客からの問い合わせをサポートしたり、パーソナライズされたレコメンデーションを提供したり、社内のナレッジ管理を支援したりしています。
LLM はまた、業界や企業全体における AI の範囲を広げ、研究、創造性、生産性の新しい波を実現する可能性を秘めています。LLM は、ヘルスケアや化学などの分野で、困難な問題に対する複雑な解決策を生み出す手助けをすることができます。LLM はまた、刷新された検索エンジン、個別指導チャットボット、作文ツール、マーケティング資料などの作成にも利用されています。
ServiceNow と NVIDIA のコラボレーションは、生産性を向上させ、ビジネス インパクトを最大化するために、新しいレベルの自動化を推進するのに役立ちます。検討されている生成 AI のユース ケースには、ユーザーの質問に答え、サポート依頼を解決するためのインテリジェントなバーチャル アシスタントやエージェントの開発、問題の自動解決、ナレッジベース記事の生成、チャットの要約に生成 AI を使用することなどが含まれます。
スウェーデンのあるコンソーシアムが、NVIDIA NeMo Megatron を使って最先端の言語モデルを開発し、北欧地域のあらゆるユーザーが利用できるようにしようとしています。このチームは、北欧の言語であるスウェーデン語、デンマーク語、ノルウェー語、そして可能性としてアイスランド語のあらゆる種類の言語タスクを処理可能な 1750 億もの膨大なパラメーターを持つ LLM を訓練することを目指しています。
このプロジェクトは戦略的な資産であり、約 200 か国で数千もの言語を話す世界におけるデジタル主権の要であると考えられています。詳細は、「The King’s Swedish: AI がスカンジナビアで本を書き換える」をご覧ください。
韓国の大手携帯電話事業者である KT は、NVIDIA DGX SuperPOD プラットフォームと NVIDIA NeMo フレームワークを使用して、10 億パラメーターの LLM を開発しました。NeMo は、エンドツーエンドのクラウドネイティブなエンタープライズ フレームワークであり、独自の LLM を構築、学習、実行するための組み込み済みコンポーネントを提供します。
KT の LLM は、同社の AI 搭載スピーカー「GiGA Genie」の理解度を向上させるために使用されています。GiGA Genie は、音声コマンドに基づいてテレビを制御したり、リアルタイムの交通情報を提供したり、その他のホーム アシスト タスクを遂行したりすることができます。詳細については、「KT が NVIDIA AI を使ってスマート スピーカーとカスタマー コールセンターを訓練」をご覧ください。
関連情報
- 大規模言語モデルの用途とは?
- ニューヨーク大学と NVIDIA、患者の再入院を予測する大規模言語モデルを共同開発
- NVIDIA AI ソフトウェアの NeMo を生成 AI に活用するスタートアップ、Writer が何百もの企業のコンテンツ作成を支援する LLM を構築
LLM をそのまま使うか、カスタマイズするか、構築するか?
組織は、既存の LLM を使用するか、学習済み LLM をカスタマイズするか、ゼロから独自の LLM を構築するのか、いずれかを選択することができます。既存の LLM を使用すれば、迅速で費用対効果の高いソリューションが提供されます。一方、学習済みの LLM をカスタマイズすれば、組織は特定のタスク用にモデルをチューニングし、独自の知識を組み込むことができます。ゼロから LLM を構築する場合は、最も柔軟性は高いですが、かなりの専門知識とリソースが必要となるでしょう。
NeMo は、いくつかのカスタマイズ手法の選択肢を提供し、マルチ GPU およびマルチノード構成で、言語および画像アプリケーションのモデルの大規模な推論に最適化されています。詳細は、「NVIDIA NeMo でエンタープライズ対応 LLM のパワーを解き放つ」をご覧ください。
NeMo は、企業向けの生成 AI モデル開発を簡単に、高い費用対効果で、高速にします。NVIDIA H100 Tensor コア GPU を搭載した A3 インスタンスの一部として Google Cloud を含むすべての主要なクラウドで利用可能で、LLM を大規模に構築、カスタマイズ、デプロイすることができます。詳細は、「GPU により高速化された Google Cloud 上の NVIDIA NeMo で生成 AI 開発を合理化」をご覧ください。
Llama 2 のような生成 AI モデルを、使いやすいインターフェイスでブラウザーから直接素早く試されたい方は、NVIDIA AI Playground をご利用ください。
関連リンク
基盤モデルから始める
基盤モデルとは、自己教師あり学習によって、膨大な量のラベルなしデータで学習された大規模な AI モデルです。例としては、Llama 2、GPT-3、Stable Diffusion などがあります。
このモデルは、画像分類、自然言語処理、質問応答など、さまざまなタスクを驚くべき精度で処理することができます。
これらの基盤モデルは、より専門的で洗練されたカスタム モデルを構築するための出発点となります。組織は、ドメイン固有のラベル付きデータを使用して基盤モデルをカスタマイズし、特定のユース ケースに対してより正確で文脈を考慮したモデルを作成することができます。
基盤モデルは、入力に続く可能性のあるすべての項目の確率分布を生成し、その分布から次の出力をランダムに選択することによって、1 つのプロンプトから膨大な数のユニークな応答を生成します。Randomization は、モデルが文脈を利用することによって増幅されます。モデルが確率分布を生成するたびに、最後に生成された項目を考慮します。つまり、各予測はその後に続くすべての予測に影響を与えることになります。
NeMo は、Llama 2、Falcon LLM、MPT などのコミュニティのモデルだけでなく、NVIDIA で訓練された基盤モデルもサポートしています。NVIDIA AI Playground では、最適化された様々なコミュニティ モデルや NVIDIA が構築した基盤モデルを、ブラウザーから直接無料で体験することができ、専有の企業データを使用して基盤モデルをカスタマイズすることができます。そうすれば、あなたのビジネスと専門分野のエキスパートであるモデルが出来上がります。
関連情報
カスタム言語モデルを構築する
企業の場合、言語処理機能を特定のユース ケースやドメイン知識に合わせてカスタマイズするために、カスタム モデルを必要とすることになるかもしれません。カスタム LLM は、特定の業界や組織のコンテキストにおいて、より効率的かつ正確にテキストを生成し、理解することを可能にします。カスタム LLM は、企業のブランド ボイスに沿ったパーソナライズされたソリューションの作成、ワークフローの最適化、より正確なインサイトの提供、ユーザー体験の向上を可能にし、最終的に市場での競争力を高めます。
NVIDIA NeMo は、カスタム LLM を構築し、学習させるためのコンポーネントを提供する強力なフレームワークです。オンプレミス、すべての主要なクラウド サービス プロバイダー、または NVIDIA DGX Cloud で動作します。プロンプト ラーニングから PEFT (Parameter-Efficient Fine Tuning)、RLHF (Reinforcement Learning from Human Feedback: 人間のフィードバックからの強化学習) まで、一連のカスタマイズ手法が含まれています。NVIDIA はまた、推論中のチューニングを可能にする SteerLM と呼ばれる新しいオープンなカスタマイズ技術もリリースしました。
LLM を学習させる際は、常に「garbage in, garbage out (ゴミを入れたら、ゴミが出てくる)」になる危険性があります。LLM のトレーニングやカスタマイズに使用されるデータの取得と整理は、労力の大部分を占めます。
NeMo Data Curator はスケーラブルなデータ キュレーション ツールで、LLM の事前学習のために 1 兆トークンの多言語データセットをキュレーションすることができます。このツールを使用すると、データセットの前処理と重複排除を、厳密重複除去とファジィ重複除去で行うことができるため、一意の文書でモデルを確実に学習させることができ、学習コストを大幅に削減できる可能性があります。
関連情報
- NVIDIA NeMo
- NVIDIA DGX Cloud
- 大規模言語モデルのカスタマイズ手法を選択する
- ハンドルを握る: NVIDIA NeMo SteerLM、推論中のモデルの反応をカスタマイズ可能に
- 1 兆トークンのデータセットをキュレーション: NVIDIA NeMo Data Curator のご紹介
LLM を外部データに接続する
LLM を外部の企業データ ソースに接続することで、その機能が強化されます。これによって LLM は、より複雑なタスクを実行したり、前回のトレーニング以降に作成されたデータを活用したりできるようになります。
RAG (Retrieval Augmented Generation: 検索拡張生成) は、LLM に、追加、削除、更新が容易な、最新の、キュレーションされた、ドメイン固有のデータ ソースを使用する能力を提供するアーキテクチャです。RAG では、外部データ ソースは (埋め込みモデルを使用して) ベクトルに変換され、推論時に高速に検索できるようにベクトル データベースに格納されます。
計算コストと財務コストの削減に加えて、RAG は精度を向上させ、より信頼性の高い AI 搭載アプリケーションを実現します。ベクトル探索の高速化は、LLM や生成 AI への応用により、AI 業界で最もホットなトピックの 1 つです。
関連情報
LLM を安全に軌道に乗せる
LLM の動作が望ましい結果に沿うようにするためには、ガイドラインを確立し、そのパフォーマンスを監視し、必要に応じてカスタマイズすることが重要です。これには、倫理的な境界を定義し、学習データのバイアスに対処し、モデルの出力を事前に定義されたメトリクスに対して定期的に評価することが含まれます。詳細については、「信頼性、安全性、セキュリティに優れた大規模言語モデル対話システムを実現」をご覧ください。
このニーズに対応するため、NVIDIA は、開発者が生成 AI アプリケーションの正確性、適性、安全性を確保できるよう支援するオープンソースのツールキット、NeMo Guardrails を開発しました。これは、OpenAI の ChatGPT を含むすべての LLM で動作するフレームワークを提供し、開発者が基盤モデルを活用した安全で信頼できる LLM 対話型システムを簡単に構築できるようにします。
LLM を安全に保つことは、生成 AI を搭載したアプリケーションにとって最も重要です。NVIDIA はまた、アクセラレーテッド コンフィデンシャル コンピューティングを導入しました。これは、AI ワークロード向け NVIDIA H100 Tensor コア GPU の前例のない高速化へのアクセスを提供しながら、脅威を軽減する画期的なセキュリティ機能です。この機能により、処理中であっても機密データが安全に保護されます。
関連情報
- 信頼性、安全性、セキュリティに優れた大規模言語モデル対話システムを実現
- NVIDIA のオープンソース ソフトウェアが、開発者による AI チャットボットへのガードレール追加を支援
- NVIDIA Hopper H100 上のコンフィデンシャル コンピューティング
本番利用における LLM 推論の最適化
LLM 推論の最適化には、モデルの量子化、ハードウェアによる高速化、効率的なデプロイ戦略などの技術が含まれます。モデルの量子化はモデルのメモリ フットプリントを削減し、ハードウェアによる高速化は GPU のような特殊なハードウェアを活用して推論を高速化します。効率的なデプロイ戦略は、本番環境における拡張性と信頼性を保証します。
NVIDIA TensorRT-LLM は、NVIDIA アクセラレーテッド コンピューティングにおける大規模な LLM 推論を強化するオープンソースのソフトウェア ライブラリです。ユーザーは、モデルの重みを新しい FP8 フォーマットに変換し、NVIDIA H100 GPU で最適化された FP8 カーネルを利用するためにモデルをコンパイルすることができます。TensorRT-LLM は、NVIDIA A100 GPU と比較して、推論性能を 4.6 倍高速化することができます。TensorRT-LLM は、LLM をより高速かつ効率的に実行する方法を提供し、LLM をより利用しやすく、費用対効果を高めます。
このようなカスタム生成 AI プロセスには、モデル、フレームワーク、ツールキットなどを組み合わせることが含まれます。これらのツールの多くはオープン ソースであり、開発プロジェクトの維持に時間と労力を要します。特に、複数の環境やプラットフォームにまたがってコラボレーションやデプロイを行おうとすれば、そのプロセスは信じられないほど複雑で時間のかかるものになる場合があります。
NVIDIA AI Workbench は、データ、モデル、リソース、およびコンピューティング ニーズを 1 つのプラットフォームで管理することができ、このプロセスを簡素化するのに役立ちます。これにより、開発者は円滑なコラボレーションとデプロイが可能になり、費用対効果を高め拡張性に優れた生成 AI モデルを迅速に作成することができます。
NVIDIA と VMware は、VMware Cloud Foundation 上に構築された最新のデータ センターを変革し、すべての企業に AI をもたらすために協力しています。NVIDIA AI Enterprise スイートと NVIDIA の最新鋭 GPU およびデータ処理ユニット (DPU) を使用することで、VMware の顧客は、NVIDIA-Certified Systems 上で既存の企業アプリケーションとともに、最新の高速化されたワークロードを安全に実行することができます。
関連情報
- NVIDIA TensorRT-LLM で大規模言語モデルの推論を最適化
- NVIDIA AI Workbench でスケーラブルな生成 AI モデルをシームレスに開発/展開
- VMware と NVIDIA によるデータ センターのモダナイズ
LLM を使い始める
LLM を使い始めるには、費用、労力、利用可能な学習データ、およびビジネス上の目的などの要素を比較検討する必要があります。組織は、ほとんどの状況において、既存のモデルを使用し、ドメイン固有の知識でカスタマイズするべきか、カスタム モデルをゼロから構築するべきか、兼ね合いを評価すべきです。特定のユース ケースや技術的要件に合ったツールやフレームワークを選択することが重要です。
生成 AI のナレッジベース チャットボット ラボでは、特定のユース ケースに対応した応答を正確に生成するために、既存の AI 基盤モデルを適応させる方法をご紹介しています。こちらの無料ラボでは、プロンプトラーニングを使用してモデルをカスタマイズし、ベクトル データベースにデータを取り込み、すべてのコンポーネントを関連付けてチャットボットを作成する実習を体験することができます。
NVIDIA AI Enterprise は、すべての主要なクラウドおよびデータセンター プラットフォームで利用可能な、AI およびデータ分析ソフトウェアのクラウドネイティブなスイートであり、NeMo フレームワークを含む 50 以上のフレームワーク、学習済みモデル、および高速化された GPU インフラストラクチャに最適化された開発ツールを提供します。このエンドツーエンドのエンタープライズ対応ソフトウェア スイートは、90 日間の無料トライアルでお試しいただけます。
NeMo は、数十億ものパラメーターを持つ生成 AI モデルを構築、カスタマイズ、デプロイするための、開発者向けのエンドツーエンドのクラウドネイティブなエンタープライズ フレームワークです。マルチ GPU とマルチノード構成によるモデルの大規模な推論に最適化されています。このフレームワークにより、企業は生成 AI モデルの開発を容易に、高い費用対効果で、迅速に行えるようになります。詳細は NeMo チュートリアルをご覧ください。
NVIDIA トレーニングは、技術的で実践的なワークショップとコースを包括的に提供することで、企業が最新テクノロジに関する人材を育成し、スキルのギャップを埋めるお手伝いをします。NVIDIA の対象分野のエキスパートによって開発された LLM ラーニング パスは、ソフトウェア エンジニアリングおよび IT 運用チームに関連する基本的なトピックから高度なトピックまで多岐にわたります。NVIDIA トレーニング アドバイザーは、カスタマイズされたトレーニング プランの開発を支援し、グループ単位で費用をご提案します。
関連情報
- 生成 AI ナレッジ ベース チャットボット
- 検索拡張生成 (RAG) AI チャットボット
- NVIDIA AI Enterprise 無料トライアル
- NVIDIA NeMo チュートリアル
- NVIDIA トレーニング
まとめ
企業が AI の進化に合わせようと競争するのであれば、LLM を採用するために最適なアプローチを特定することは不可欠です。基盤モデルは、開発プロセスを飛躍的に加速させるのに役立ちます。データを効率的に処理/保存し、モデルをカスタマイズするために主要なツールと環境を使用することで、生産性を大幅に加速し、ビジネスの目標を前進させることができます。
翻訳に関する免責事項
この記事は、「Getting Started with Large Language Models for Enterprise Solutions」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。