Transformer 層を積み重ねて大規模なモデルを作成すると、精度が向上し、Few-shot Learning 能力を獲得し、さらには幅広い言語タスクで人間に近い創発的な能力が得られます。これらの基盤モデルはトレーニングにコストがかかり、推論中にメモリと計算を大量に消費する可能性があります (継続的にかかるコスト)。現在、最もポピュラーな大規模言語モデル (LLM)では、パラメーターのサイズは数百億から数千億に達することがあり、ユース ケースによっては長い入力 (またはコンテキスト) の取り込みが必要になる場合があり、これによって費用も増加する可能性があります。
この投稿では、LLM 推論における最も差し迫った課題と、いくつかの実用的な解決策について説明します。読者に、Transformer のアーキテクチャ、そして一般的なアテンション メカニズムについての基本的な理解があることを前提としています。LLM 推論の複雑さを理解することが不可欠ですが、これについては次のセクションで説明します。
LLM 推論を理解する
一般的なデコーダーのみの LLM (GPT-3 など) のほとんどは、因果モデリング目的のために事前トレーニングされており、次の単語の予測器として使用されます。これらの LLM は、一連のトークンを入力として受け取り、停止基準 (生成するトークン数の制限やストップ ワードのリストなど) を満たすまで、または特別なトークン、生成の終わりを示す <終了> トークンを生成するまで、後続のトークンを自己回帰的に生成します。このプロセスには、プレフィル フェーズとデコード フェーズの 2 つのフェーズが含まれます。
トークンはモデルが処理する言語の原子的な部分であることに注意してください。1 つのトークンはおよそ英語 4 文字です。自然言語のすべての入力は、モデルに入力される前にトークンに変換されます。
プレフィル フェーズまたは入力の処理
プレフィル フェーズでは、LLM は入力トークンを処理して中間状態 (キーと値) を計算します。これは、「最初の」新しいトークンを生成するために使用されます。新しいトークンはそれぞれ、以前のすべてのトークンに依存しますが、これは、入力の全範囲がわかっていることにより、大まかに言えば高度に並列化された行列対行列の演算となります。これは、GPU 使用率が事実上飽和状態になります。
デコード フェーズまたは出力の生成
デコード フェーズでは、LLM は停止基準が満たされるまで、出力トークンを 1 つずつ自己回帰的に生成します。各順次出力トークンは、以前のすべてのイテレーションの出力状態 (キーと値) を知っている必要があります。これは、プリフィル フェーズと比較して GPU の計算能力を十分に活用しない行列ベクトル演算のようなものです。データ (重み、キー、値、アクティベーション) がメモリから GPU に転送される速度が、レイテンシを支配します。実際の計算速度ではありません。言い換えれば、これはメモリに依存した操作です。
この投稿で紹介されている推論の課題と対応するソリューションの多くは、効率的なアテンション モジュール、キーと値の効果的な管理など、このデコード フェーズの最適化に関係しています。
異なる LLM は異なるトークナイザーを使用する可能性があるため、それらの間で出力トークンを比較することは簡単ではない可能性があります。推論スループットを比較する場合、2 つの LLM の 1 秒あたりのトークン出力が同等であっても、異なるトークナイザーを使用している場合は同等ではない可能性があります。これは、対応するトークンが異なる数の文字を表す可能性があるためです。
バッチ処理
GPU 使用率と効果的なスループットを向上させる最も簡単な方法は、バッチ処理を使用することです。複数のリクエストが同じモデルを使用するため、重みのメモリ コストが分散されます。より大きなバッチが GPU に転送されて一度に処理されると、利用可能なコンピューティングがさらに活用されます。
ただし、バッチ サイズは特定の制限までしか増やすことができず、それを超えるとメモリ オーバーフローが発生する可能性があります。これが発生する理由をより深く理解するには、キー/値 (KV) キャッシュと LLM メモリ要件を確認する必要があります。
従来のバッチ処理 (静的バッチ処理とも呼ばれます) は最適とは言えません。これは、バッチ内の各リクエストに対して、LLM が異なる数の完了トークンを生成する可能性があり、実行時間が異なるためです。その結果、バッチ内のすべてのリクエストは最も長いリクエストが終了するまで待機する必要があり、生成の長さに大きな差異があるとさらに状況が悪化する可能性があります。これを軽減する方法としては、後で説明するインフライト バッチングなどがあります。
キーと値のキャッシュ
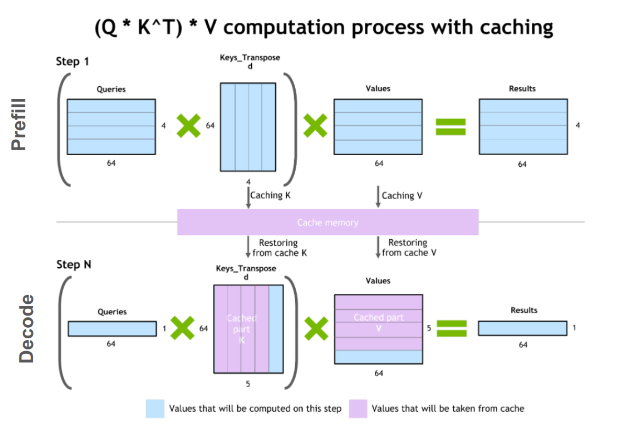
デコード フェーズの一般的な最適化の 1 つは、KV キャッシュです。デコード フェーズではタイム ステップごとに 1 つのトークンが生成されますが、各トークンは以前のすべてのトークン (プレフィル時に計算された入力トークンの KV テンソル、および現在のタイム ステップまでに計算された新しい KV テンソルを含む) のキーと値のテンソルに依存します。
各タイム ステップですべてのトークンに対してこれらすべてのテンソルを再計算することを避けるために、これらを GPU メモリにキャッシュすることができます。イテレーションごとに、新しい要素が計算されると、それらは次のイテレーションで使用されるように実行中のキャッシュに追加されます。一部の実装では、モデルの各レイヤーに 1 つの KV キャッシュがあります。
LLM メモリ要件
実際、GPU LLM メモリ要件に大きく影響する 2 つの要因は、モデルの重みと KV キャッシュです。
- モデルの重み: メモリはモデル パラメーターによって占有されます。例として、70 億個のパラメーター (たとえば、Llama 2 7B)を、16 ビット精度 (FP16 または BF16) でロードすると、メモリにおよそ 7B * sizeof(FP16) ~= 14 GB が必要になります。
- KV キャッシュ: メモリは、冗長な計算を避けるためにセルフアテンション テンソルのキャッシュによって占有されます。
バッチ処理では、バッチ内の各リクエストの KV キャッシュを個別に割り当てる必要があり、メモリ フットプリントが大きくなる可能性があります。以下の式は、今日の最も一般的な LLM アーキテクチャに適用できる KV キャッシュのサイズを示しています。
トークンごとの KV キャッシュのサイズ (バイト単位) = 2 * (num_layers) * (num_heads * dim_head) * precision_in_bytes
最初の係数 2 は、K 行列と V 行列を表します。通常、(num_heads * dim_head) の値は、Transformer の hidden_size (またはモデルの次元 d_model) と同じです。これらのモデル属性は、通常、モデル カードまたは関連する構成ファイルで見つけることができます。
このメモリ サイズは、入力のバッチ全体にわたって、入力シーケンス内の各トークンに必要です。半精度を仮定すると、KV キャッシュの合計サイズは次の式で求められます。
KV キャッシュの合計サイズ (バイト単位) = (batch_size) * (sequence_length) * 2 * (num_layers) * (hidden_size) * sizeof(FP16)
たとえば、16 ビット精度の Llama 2 7B モデルとバッチ サイズ 1 の場合、KV キャッシュのサイズは 1 * 4096 * 2 * 32 * 4096 * 2 バイトとなり、約 2 GB になります。
この KV キャッシュを効率的に管理することは、困難な作業です。バッチ サイズとシーケンスの長さに応じて線形に増加するため、メモリ要件は急速に拡大します。その結果、提供できるスループットが制限され、長いコンテキストの入力に課題が生じます。これが、この投稿で取り上げるいくつかの最適化の背後にある動機です。
モデルの並列化による LLM のスケールアップ
モデルの重みによるデバイスごとのメモリ フットプリントを削減する 1 つの方法は、モデルを複数の GPU に分散することです。メモリとコンピューティング フットプリントを分散することで、より大きなモデルやより大きな入力バッチを実行できるようになります。モデルの並列化は、単一デバイスで利用可能なメモリよりも多くのメモリを必要とするモデルでトレーニングまたは推論を行う場合、またトレーニング時間や推論の測定値 (レイテンシまたはスループット) を特定のユースケースに適したものにするために必要です。モデルの重みがどのように分割されるかに基づいて、モデルを並列化する方法がいくつかあります。
データ並列化も、以下に挙げる他の技術と同じ文脈でよく言及される技術であることに注意してください。この場合、モデルの重みが複数のデバイスにコピーされ、入力の (グローバル) バッチ サイズが各デバイスにわたってマイクロバッチにシャーディングされます。より大きなバッチを処理することにより、全体の実行時間が短縮されます。ただし、これはトレーニング時間の最適化であり、推論中にはあまり関係がありません。
パイプライン並列化
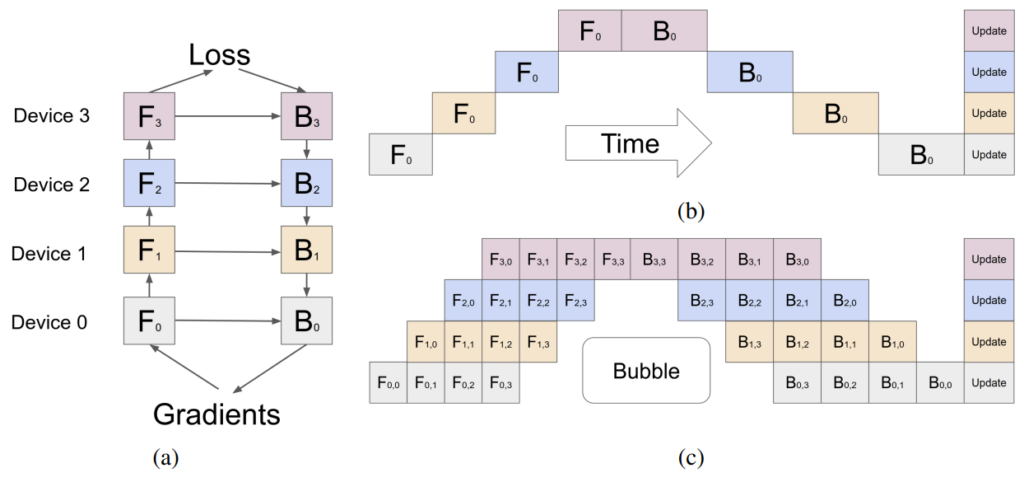
パイプライン並列化は、モデルをチャンクに (垂直に) シャーディングします。各チャンクは、別々のデバイスで実行されるレイヤーのサブセットで構成されます。図 2a は、4-way のパイプライン並列化を示しています。モデルは順次分割され、すべての層の 4 分の 1 のサブセットが各デバイスで実行されます。1 つのデバイス上の一連の操作の出力は次のデバイスに渡され、後続のチャンクの実行が継続されます。 そして
は、それぞれデバイス n での順方向パスと逆方向パスを示します。各デバイスでモデルの重みを保存するためのメモリ要件は実質的に 4 分の 1 になります。
この方法の主な制限は、処理の逐次的な性質により、前の層の出力 (アクティブ化、勾配) を待機している間、一部のデバイスまたは層がアイドル状態のままになる可能性があることです。これにより、順方向パスと逆方向パスの両方で非効率または「パイプライン バブル」が発生します。図 2b では、白い空白の領域が、デバイスがアイドル状態で十分に活用されていない単純なパイプライン並列化による大きなパイプライン バブルです。
図 2c に示すように、マイクロバッチ処理によりこれをある程度軽減できます。入力のグローバル バッチ サイズはサブバッチに分割され、1 つずつ処理され、最後に勾配が蓄積されます。 と
は、それぞれマイクロバッチ
を持つデバイス
上での順方向パスと逆方向パスを示すことに注意してください。このアプローチではパイプラインのバブルのサイズは縮小しますが、完全に排除することはできません。
テンソル並列化
テンソル並列化は、モデルの個々の層を、さまざまなデバイスで実行できる小さな独立した計算ブロックに (水平に) シャーディングします。アテンション ブロックと多層パーセプトロン (MLP) 層は、テンソル並列化を利用できる Transformer の主要コンポーネントです。マルチヘッド アテンション ブロックでは、各ヘッドまたはヘッドのグループを異なるデバイスに割り当てることができるため、それらを独立して並列に計算できます。
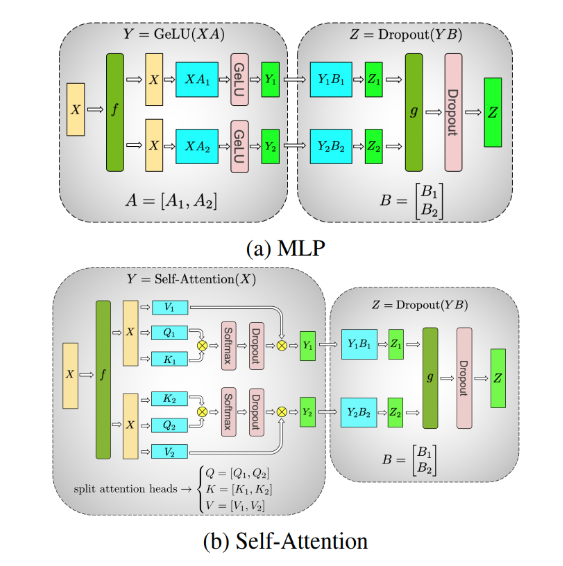
図 3a は、2 層 MLP 上の 2 -way テンソル並列化の例を示しており、各層は丸いボックスで表されています。最初の層内では、重み行列 は、
そして
に分割されます。
と
の計算は、入力
の同じバッチで 2 つの異なるデバイス上で独立して実行できます (
は入力の恒等演算です)。これにより、各デバイスに重みを格納するためのメモリ要件が実質的に半分になります。リダクション操作
は、2 番目の層の出力を結合します。
図 3b は、セルフアテンション層における 2-way テンソル並列化の例です。複数のアテンション ヘッドは本質的に並列しており、デバイス間で分割できます。
シーケンス並列化
テンソル並列化には、層を独立した管理可能なブロックに分割する必要があるため、制限があります。LayerNorm や Dropout などの操作には適用されず、代わりにテンソル並列グループ全体で複製されます。LayerNorm と Dropout は計算コストが低い一方で、(冗長な) アクティベーションを格納するためにかなりの量のメモリを必要とします。
「Reducing Activation Recomputation in Large Transformer Models」で示されているように、これらの操作は入力シーケンス全体で独立しており、これらの操作はその「シーケンス次元」に沿って分割できるため、メモリ効率が向上します。これをシーケンス並列化と呼びます。
モデル並列化の手法は排他的なものではなく、組み合わせて使用できます。これらは、LLM の拡張と GPU ごとのメモリ フットプリントの削減に役立ちますが、アテンション モジュールに特化した最適化手法もあります。
アテンション メカニズムの最適化
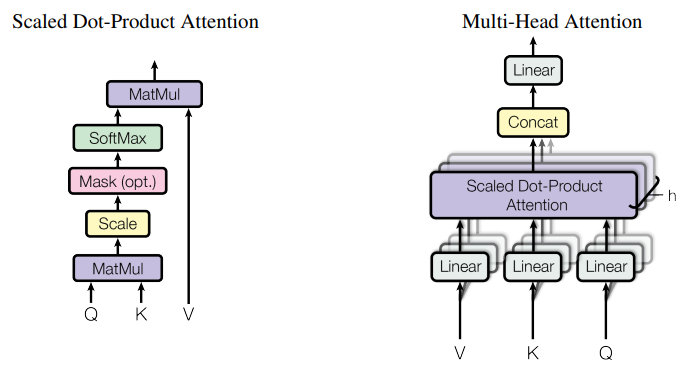
Scaled Dot-Product Attention (SDPA) 操作は、「Attention Is All You Need」で説明されているように、クエリとキーと値のペアを出力にマップします。
マルチヘッド アテンション
SDPA の拡張機能として、Q、K、V 行列の学習済みの異なる射影を使い、アテンション レイヤーを複数回並行して実行することで、モデルが異なる位置にある異なる表現部分空間からの情報に共同で注目できるようになります。これらの部分空間は独立して学習され、モデルが入力内のさまざまな位置をより深く理解できるようになります。
図 5 に示すように、複数の並列アテンション操作からの出力は連結され、線形射影されて結合されます。それぞれの並列アテンション層は「ヘッド」と呼ばれ、このアプローチはマルチヘッド アテンション (MHA) と呼ばれます。
オリジナルの動作では、8 つの並列アテンション ヘッドを使用する場合、各アテンション ヘッドはモデルの縮小次元で動作します (例: )。これにより、単一ヘッドのアテンションと同様の計算コストが維持されます。
マルチクエリ アテンション
MHA に対する推論最適化の 1 つである、マルチクエリ アテンション (MQA) は、「Fast Transformer Decoding」にて提案され、複数のアテンション ヘッド間でキーと値を共有します。クエリ ベクトルは、以前と同様に複数回射影されます。
MQA で実行される計算量は MHA と同じですが、メモリから読み出されるデータ (キー、値) の量は以前の数分の一です。メモリ帯域幅が制限される場合、これによりコンピューティング利用率が向上します。また、メモリ内の KV キャッシュのサイズも削減され、より大きなバッチ サイズに対応できるスペースが確保されます。
Key-Value ヘッドの削減により、正確度が低下する可能性があります。さらに、推論時にこの最適化を利用する必要があるモデルは、MQA を有効にしてトレーニング (または少なくともトレーニング量の ~5% でファインチューニング) する必要があります。
グループ化されたクエリ アテンション
Grouped-query attention (GQA) は、キーと値をいくつかのクエリ ヘッドのグループに射影することで、MHA と MQA の間のバランスを取ります (図 6)。各グループ内では、マルチクエリ アテンションのように動作します。
図 6 は、マルチヘッド アテンションに複数のキーと値のヘッドがあることを示しています (左)。グループ化されたクエリ アテンション (中央) には、キーと値のヘッドが 1 つよりも多くありますが、クエリ ヘッドの数よりも少なく、メモリ要件とモデルの品質のバランスが取れています。マルチクエリ アテンション (右) には、メモリを節約するために単一のキーと値のヘッドがあります。
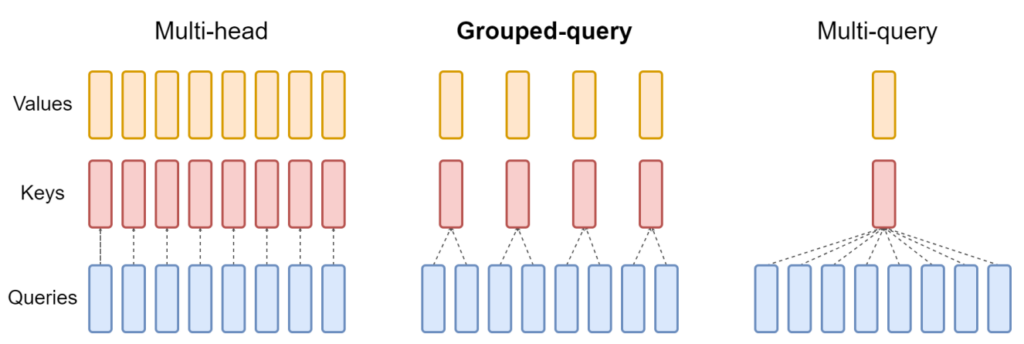
元々 MHA でトレーニングされたモデルは、元のトレーニング コンピューティングの一部を使用して GQA で「アップトレーニング」できます。MQA に近い計算効率を維持しながら、MHA に近い品質を実現します。Llama 2 70B は、GQA を活用するモデルの例です。
MQA や GQA などの最適化は、保存されるキーと値のヘッドの数を減らすことで、KV キャッシュに必要なメモリを削減します。この KV キャッシュの管理方法には依然として非効率性がある可能性があります。次のセクションでは、アテンション モジュール自体の最適化とは異なる、より効率的な KV キャッシュ管理の手法を紹介します。
フラッシュ アテンション
アテンション メカニズムを最適化するもう 1 つの方法は、GPU のメモリ階層をより有効に活用するために特定の計算の順序を変更することです。ニューラル ネットワークは一般にレイヤーの観点から記述され、ほとんどの実装もそのようにレイアウトされ、入力データに対して一度に 1 種類の計算が順番に実行されます。これは常に最適なパフォーマンスをもたらすわけではありません。メモリ階層のより高い、よりパフォーマンスの高いレベルに既に取り込まれている値に対してさらに多くの計算を実行する方が有益な場合があります。
実際の計算中に複数のレイヤーを結合すると、GPU がメモリに対して読み書きする回数を最小限に抑え、たとえそれらがニューラル ネットワーク内の異なるレイヤーの一部であっても、同じデータを必要とする計算をグループ化することができます。
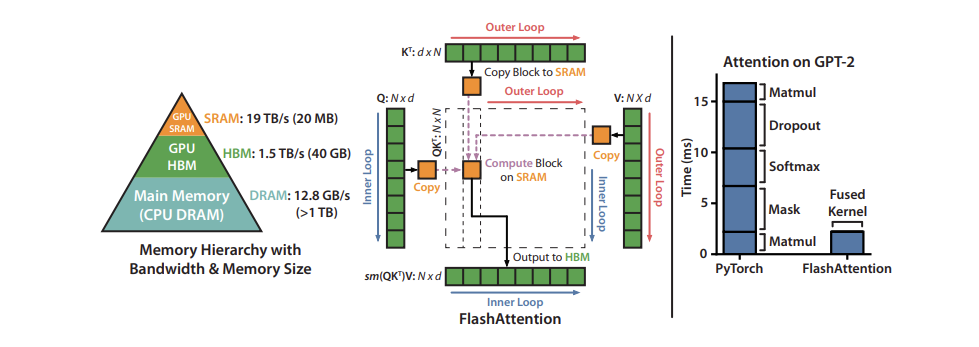
非常に人気のある融合の 1 つは、I/O を意識した正確なアテンション アルゴリズムである FlashAttention です。詳細については、「FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness」を参照してください。Exact attention は、標準のマルチヘッド アテンション (マルチクエリおよびグループ化クエリ アテンションに利用可能な変種を含む) と数学的に同一であるため、既存のモデル アーキテクチャ、またはすでにトレーニング済みのモデルに変更を加えることなく置き換えることができます。
「I/O を意識した」とは、操作を融合するときに前述したメモリ移動コストの一部を考慮することを意味します。特に、FlashAttendant は、行列全体の計算の一部を段階的に実行し、その間の中間値を書き出すのではなく、「タイリング」を使用して最終行列の一部を完全に計算して一度に書き出します。
図 7 は、40 GB GPU 上のタイル化された FlashAttendant 計算パターンとメモリ階層を示しています。右側のグラフは、アテンション メカニズムのさまざまなコンポーネントを融合および並べ替えることによってもたらされる相対的な高速化を示しています。
ページングによる KV キャッシュの効率的な管理
入力のサイズは予測できないため、KV キャッシュは、考えうる最大の入力 (サポートされるシーケンスの長さ) を考慮して静的に「オーバープロビジョニング」されることがあります。たとえば、モデルでサポートされている最大シーケンス長が 2,048 の場合、リクエスト内の入力のサイズと生成された出力に関係なく、サイズ 2,048 がメモリ内に予約されます。このスペースは連続的に割り当てられる可能性があり、多くの場合、その大部分が未使用のままになり、メモリの無駄や断片化が発生します。この予約されたスペースは、リクエストの存続期間中拘束されます。

PagedAttention は、オペレーティング システムのページングからインスピレーションを受けており、このアルゴリズムにより、連続キーや値をメモリ内の非連続領域に保存できます。各リクエストの KV キャッシュを固定数のトークンを表すブロックに分割し、非連続に格納できます。
これらのブロックは、アカウントを保持するブロック テーブルを使用して、アテンションの計算中に必要に応じてフェッチされます。新しいトークンが生成されると、新しいブロック割り当てが行われます。これらのブロックのサイズは固定されているため、異なるリクエストに異なる割り当てが必要になるなどの課題から生じる非効率性が排除されます。これによりメモリの浪費が大幅に制限され、より大きなバッチ サイズ (結果としてスループット) が可能になります。
モデル最適化手法
これまで、LLM がメモリを消費するさまざまな方法、メモリを複数の異なる GPU に分散する方法、アテンション メカニズムと KV キャッシュの最適化について説明してきました。モデルの重み自体を変更することで各 GPU のメモリ使用量を削減するモデル最適化手法もいくつかあります。GPU には、これらの変更された値の演算を高速化するための専用ハードウェアもあり、モデルの速度がさらに向上します。
量子化
量子化は、モデルの重みとアクティベーションの精度を下げるプロセスです。ほとんどのモデルは 32 ビットまたは 16 ビットの精度でトレーニングされ、各パラメーターとアクティベーション要素は 32 ビットまたは 16 ビットのメモリ (単精度浮動小数点) を占有します。しかし、ほとんどのディープラーニング モデルは、値あたり 8 ビットまたはそれ以下のビットでも効果的に表現できます。
図 9 は、考えられる 1 つの量子化方法の前後の値の分布を示しています。この場合、丸めにより精度の一部が失われ、クリッピングによりダイナミック レンジの一部が失われるため、値をより小さい形式で表現できます。
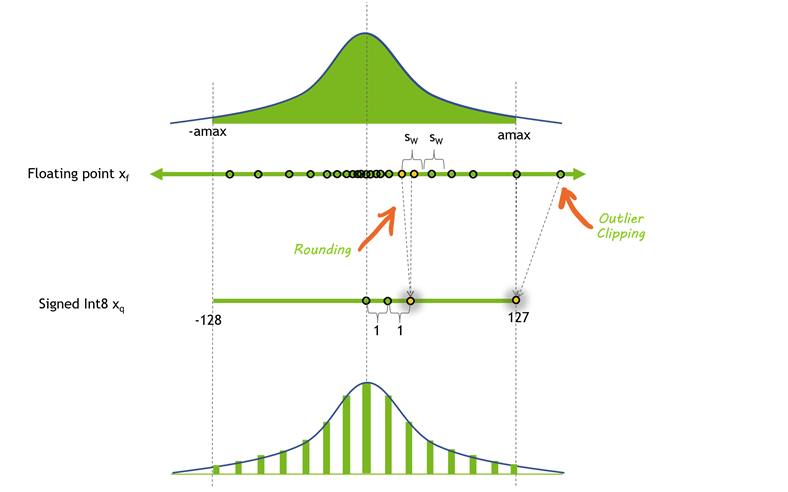
モデルの精度を下げると、いくつかの利点が得られます。モデルがメモリ内で占めるスペースが少なくなると、同じサイズのハードウェアに大きなモデルを収めることができます。量子化は、同じ帯域幅でより多くのパラメーターを転送できることも意味し、帯域幅が制限されているモデルを高速化するのに役立ちます。
LLM には、アクティベーション、重み、またはその両方に低精度を用いるさまざまな量子化手法があります。重みはトレーニング後に固定されるため、重みを量子化する方がはるかに簡単です。しかし、アクティベーションはより高い精度で維持されるため、パフォーマンスが若干低下する可能性があります。GPU には INT8 と FP16 の数値を乗算するための専用のハードウェアがないため、実際の演算では重みをより高い精度に変換し直す必要があります。
アクティベーション、トランス ブロックおよびネットワーク層の入力を量子化することも可能ですが、これには独自の課題が伴います。アクティベーション ベクトルには外れ値が含まれることが多いため、そのダイナミック レンジが効果的に増加し、重みを使用する場合よりも低い精度でこれらの値を表現することがより困難になります。
1 つのオプションは、代表的なデータセットをモデルに渡し、特定のアクティベーションを他のアクティベーションよりも高い精度で表すことを選択する (LLM.int8()) ことで、これらの外れ値が表示される可能性が高い場所を見つけることです。もう 1 つのオプションは、量子化が容易な重みのダイナミック レンジを借用し、その範囲をアクティベーションで再利用することです。
スパーシティ
量子化と同様に、多くのディープラーニング モデルは枝刈り、つまり 0 に近い特定の値を 0 自体に置き換えることに対して堅牢であることが示されています。スパース行列は、要素の多くが 0 である行列です。これらは、完全な密行列よりも占有スペースが少ない圧縮形式で表現できます。
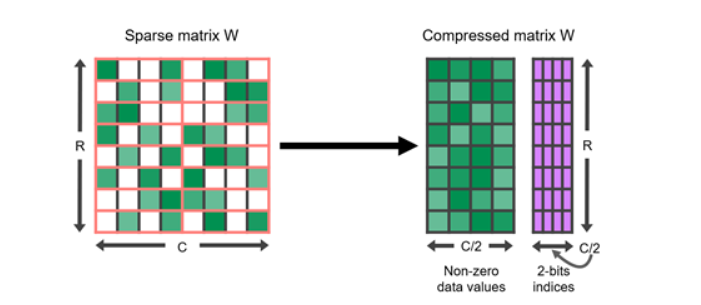
特に GPU は、4 つの値のうち 2 つが 0 で表される、ある種の構造化されたスパース性に対する、ハードウェア アクセラレーションが備わっています。スパース表現を量子化と組み合わせて、実行のさらなる高速化を実現することもできます。大規模言語モデルをスパース形式で表現する最適な方法を見つけることは、現在も活発な研究分野であり、推論速度の将来の改善に有望な方向性を提供します。
蒸留
モデルのサイズを縮小するもう 1 つのアプローチは、蒸留と呼ばれるプロセスを通じてその知識をより小さなモデルに転送することです。このプロセスには、より大きなモデル (教師) の動作を模倣するために、より小さなモデル (生徒) をトレーニングすることが含まれます。
蒸留モデルの成功例としては、DistilBERT があります。これは、言語理解能力の 97% を維持しながら、BERT モデルが 40% 圧縮され、速度は 60% 高速です。
LLM での蒸留は活発な研究分野ですが、一般的なアプローチはニューラル ネットワークに関して「Distilling the Knowledge in a Neural Network」にて最初に説明されました。
- 生徒ネットワークは、出力間の不一致を測定する損失関数を使用して、大規模な教師ネットワークのパフォーマンスを反映するようにトレーニングされます。この目的には、生徒の出力を正解のラベルと照合するという元の損失関数が含まれる可能性があることに加えて行われます。
- 一致する教師の出力は、最後の層 (ロジットと呼ばれる) または中間層のアクティベーションの場合があります。
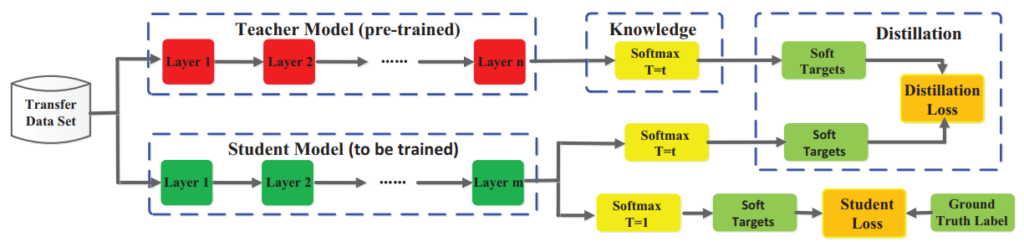
図 11 は、知識蒸留の一般的なフレームワークを示しています。教師のロジットは、生徒が蒸留損失を使用して最適化するソフト ターゲットです。他の蒸留方法では、教師からの知識を「蒸留」するために他の損失尺度が使用される場合があります。
蒸留の代替となるアプローチは、教師が合成したデータを生徒 LLM の教師付きトレーニングに使用することです。これは、人間によるアノテーションが不足している場合、または利用できない場合に特に役立ちます。「Distilling Step by Step!」では、グラウンド トゥルースとして機能するラベルに加えて、教師 LLM から理論的根拠を抽出することで、さらに一歩進んでいます。これらの理論的根拠は、データ効率の高い方法で小規模な生徒 LLM をトレーニングするための中間推論ステップとして機能します。
現在、多くの最先端の LLM は、その出力を他の LLM をトレーニングするために使用することを禁止する制限的なライセンスを持っているため、適切な教師モデルを見つけることが困難になっていることに注意する必要があります。
モデル提供手法
モデルの実行はメモリ帯域幅の制約を受けることが多く、特に重みの帯域幅の制約が大きくなります。前述したモデルの最適化をすべて適用したとしても、依然としてメモリ制限が発生する可能性は非常に高くなります。したがって、ロード時にモデルの重みをできる限り調整する必要があります。言い換えれば、物事を並行してやってみるということです。次の 2 つのアプローチが可能です。
- インフライト バッチング 複数の異なるリクエストを同時に実行する必要があります。
- 投機的推論 時間を節約するために、シーケンスの複数の異なるステップを並行して実行する必要があります。
インフライト バッチング
LLM には独自の実行特性がいくつかあり、実際にはリクエストを効果的にバッチ処理することが困難になる可能性があります。単一のモデルは、互いに大きく異なるさまざまなタスクに同時に使用できます。チャットボットでの単純な質問と回答の応答から、ドキュメントの要約や長いコード チャンクの生成に至るまで、ワークロードは非常に動的であり、出力のサイズは数桁異なります。
この多用途性により、リクエストをバッチ処理して効果的に並列実行することが困難になる可能性があります。バッチ処理は、ニューラル ネットワークにサービスを提供するための一般的な最適化です。これにより、一部のリクエストが他のリクエストよりもはるかに早く終了する可能性があります。
これらの動的な負荷を管理するために、多くの LLM サービス ソリューションには、連続バッチ処理またはインフライト バッチングと呼ばれる最適化されたスケジューリング手法が含まれています。これは、LLM のテキスト生成プロセス全体がモデル上で複数回のイテレーション実行に分割できるという事実を利用しています。
インフライト バッチングでは、バッチ全体が終了するのを待ってから次のリクエスト セットに進むのではなく、サーバー ランタイムは終了したシーケンスをバッチから即座に削除します。その後、他のリクエストがまだ処理中である間に、新しいリクエストの実行を開始します。したがって、インフライト バッチングにより、実際のユース ケースにおいて全体的な GPU 使用率が大幅に増加する可能性があります。
投機的推論
投機的サンプリング、支援生成、またはブロック単位の並列デコードとも呼ばれる投機的推論は、LLM の実行を並列化する別の方法です。通常、GPT スタイルの大規模言語モデルは、トークンごとにテキスト トークンを生成する自己回帰モデルです。
生成されるすべてのトークンは、その前にあるすべてのトークンに依存してコンテキストを提供します。これは、通常の実行では、同じシーケンスから複数のトークンを並行して生成することが不可能であることを意味します。n+1 を生成するには、n 番目のトークンが生成されるまで待つ必要があります。
図 12 は、ドラフト モデルが、並行して検証または拒否される複数の将来のステップを一時的に予測する、投機的推論の例を示しています。この場合、ドラフト内の最初の 2 つの予測トークンは受け入れられますが、最後のトークンは拒否され、生成を続行する前に削除されます。
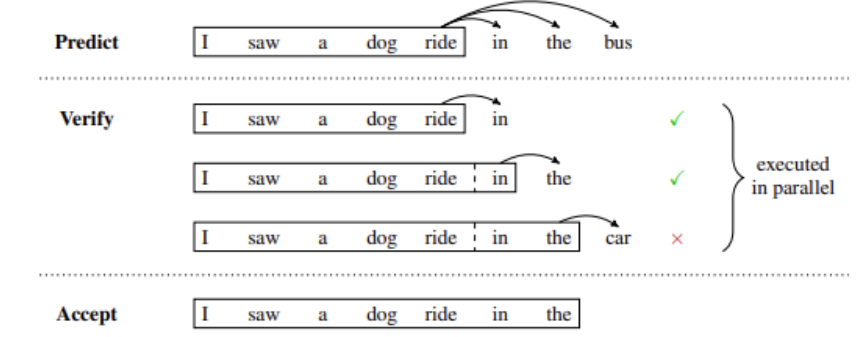
投機的サンプリングは回避策を提供します。このアプローチの基本的な考え方は、「より安価な」プロセスを使用して、数トークンの長さのドラフト継続を生成することです。次に、必要な実行ステップの「投機的」コンテキストとして安価なドラフトを使用して、メインの「検証」モデルを複数のステップで並行して実行します。
検証モデルがドラフトと同じトークンを生成する場合は、それらのトークンを出力として受け入れることができます。それ以外の場合は、最初の不一致トークン以降のすべてを破棄し、新しいドラフトでプロセスを繰り返すことができます。
ドラフト トークンを生成する方法にはさまざまなオプションがあり、それぞれに異なるトレードオフがあります。複数のモデルをトレーニングしたり、単一の事前トレーニングされたモデルで複数のヘッドを微調整したりして、将来の複数のステップのトークンを予測することができます。または、小規模なモデルをドラフト モデルとして使用し、より大型でより機能の高いモデルを検証モデルとして使用することもできます。
結論
この投稿では、データ センターであろうと PC 上のエッジであろうと、LLM を最適化し、効率的にサービスを提供するのに役立つ、最も一般的なソリューションの多くを概説しました。これらのテクニックの多くは NVIDIA TensorRT-LLM にて最適化され、提供されています。、これは、TensorRT ディープラーニング コンパイラーと、最適化されたカーネル、前処理および後処理ステップ、および NVIDIA GPU で画期的なパフォーマンスを実現するマルチ GPU/マルチノード通信プリミティブで構成されるオープンソース ライブラリです。詳細については、「NVIDIA TensorRT-LLM で大規模言語モデルの推論を最適化」を参照してください。
NVIDIA TensorRT-LLM は NVIDIA Triton Inference Server でサポートされています。これにより、企業は、さまざまな AI フレームワーク、ハードウェア アクセラレータ、展開モデルにわたって、最高のスループットと最小限のレイテンシで複数の AI モデルを同時に提供できるようになります。
TensorRT-LLM は、NVIDIA NeMo でも活用されています。これは開発者が数十億のパラメーターを持つ生成 AI モデルを構築、カスタマイズ、展開するためのエンドツーエンドのクラウドネイティブ エンタープライズ フレームワークを提供します。NeMo を始めましょう。
関連情報
- GTC セッション: Taming LLMs with the Latest Customization Techniques (Spring 2023)
- GTC セッション: Optimizing Data Systems for Merlin and Triton (Spring 2023)
- GTC セッション: Leveraging Large Language Models for Generating Content (Spring 2023)
- ウェビナー: Deeper Dive into TensorRT and TRITON
- ウェビナー: Implementing Large Language Models
- ウェビナー: Optimization Strategies for Deploying Self-Driving DNNs with NVIDIA TensorRT
翻訳に関する免責事項
この記事は、「Mastering LLM Techniques: Inference Optimization」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。