
Developing custom generative AI models and applications is a journey, not a destination. It begins with selecting a pretrained model, such as a Large Language Model, for exploratory purposes—then developers often want to tune that model for their specific use case. This first step typically requires using accessible compute infrastructure, such as a PC or workstation. But as training jobs get larger, developers are forced to expand into additional compute infrastructure in the data center or cloud.
The process can become incredibly complex and time consuming, especially when trying to collaborate and deploy across multiple environments and platforms. NVIDIA AI Workbench helps simplify the process by providing a single platform for managing data, models, resources, and compute needs. This enables seamless collaboration and deployment for developers to develop cost-effective scalable generative AI models quickly.
What’s NVIDIA AI Workbench?
NVIDIA AI Workbench is a unified, easy-to-use developer toolkit to create, test, and customize pretrained AI models on a PC or workstation. Then users can scale the models to virtually any data center, public cloud, or NVIDIA DGX Cloud. It enables developers of all levels to generate and deploy cost-effective and scalable generative AI models quickly and easily.
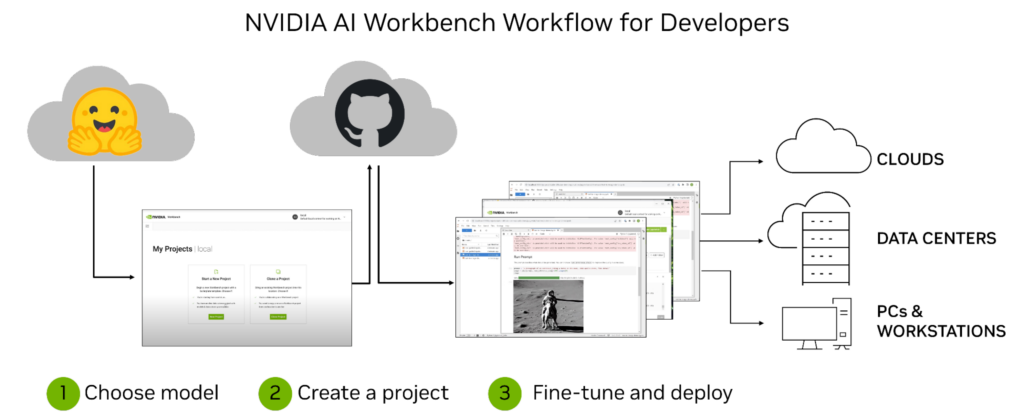
After installation, the platform provides management and deployment for containerized development environments to make sure everything works, regardless of a user’s machine. AI Workbench integrates with platforms like GitHub, Hugging Face, and NVIDIA NGC, as well as with self-hosted registries and Git servers.
Users can develop naturally in both JupyterLab and VS Code while managing work across a variety of machines with a high degree of reproducibility and transparency. Developers with an NVIDIA RTX PC or workstation can also launch, test, and fine-tune enterprise-grade generative AI projects on their local systems, and access data center and cloud computing resources when scaling up.
Enterprises can connect AI Workbench to NVIDIA AI Enterprise, accelerating the adoption of generative AI and paving the way for seamless integration in production. Sign up to get notified when AI Workbench is available for early access.
Enterprise AI development workflow challenges
While generative AI models offer incredible potential for businesses, the development process can be complex and time consuming.
Some of the challenges faced by enterprises as they begin their journey developing custom generative AI include the following.
Technical expertise: having the right technical skills is key when working on generative AI models. Developers must have a deep understanding of machine learning algorithms, data manipulation techniques, languages such as Python, and frameworks like TensorFlow.
Data access and security: the proliferation of sensitive customer data means it’s important to make sure proper security measures are taken during such projects. Additionally, businesses must consider how they’ll access the necessary datasets for training their models, which may involve dealing with large amounts of unstructured or semi-structured data from multiple sources.
Moving workflows and applications: development and deployment across machines and environments can be complex due to dependencies between components. Keeping track of different versions of the same application or workflow can be difficult, especially in more distributed environments such as cloud computing platforms like Amazon AWS, Google Cloud Platform, or Microsoft Azure. Additionally, managing credentials and confidential information is essential for protecting secure access to resources across machines and environments.
These challenges underscore the importance of having a comprehensive platform like NVIDIA AI Workbench that simplifies the entire generative AI development process. This makes it easier to manage data, models, compute resources, dependencies between components, and versions. All while providing seamless collaboration and deployment capabilities across machines and environments.
Key benefits of NVIDIA AI Workbench
Developing generative AI models is a complex process, and AI Workbench streamlines it. With its unified platform for managing data, models, and compute resources, developers of all skill levels can quickly and easily create and deploy cost-effective, scalable AI models.
Some of the key benefits of using AI Workbench include the following:
Easy-to-use development platform: AI Workbench simplifies the development process by providing a single platform for managing data, models, and compute resources that supports collaboration across machines and environments.
Integration with AI development tools and repositories: AI Workbench integrates with services such as GitHub, NVIDIA NGC, and Hugging Face, self-hosted registries, and Git servers. Users can develop using tools like JupyterLab and VS Code, across platforms and infrastructure with a high degree of reproducibility and transparency.
Enhanced collaboration: AI Workbench uses an architecture focused around a project, which is a Git repository with metadata files describing the contents and their relationships, instructions for configuration, and execution. Location or user-dependent data is handled by AI Workbench transparently and injected at runtime so that such information isn’t hard coded into projects. The project structure helps to automate complex tasks around versioning, container management, and handling confidential information while also enabling collaboration across teams.
Access to accelerated compute: AI Workbench deployment is a client-server model. The Workbench user interface runs on a local system and communicates with the Workbench Service remotely. Both the user interface and service run locally on a user’s primary resource, such as a work laptop. The service can be installed on remote machines accessible through SSH connections. This enables teams to begin development on local compute resources in their workstations and shift to data center or cloud resources as the training jobs get larger.
NVIDIA AI Workbench in action
At SIGGRAPH 2023, we demonstrated the power of AI Workbench for generative AI customization across both text and image workflows.
Custom image generation with Stable Diffusion XL
While Gradio apps on services like Hugging Face Spaces provide one-click interaction with models like StableDiffusion XL, getting those models and apps to run locally can be tough.
Users must get the local environment set up with the appropriate NVIDIA software, such as NVIDIA TensorRT and NVIDIA Triton. Then, they need models from Hugging Face, code from GitHub, and containers from NVIDIA NGC. Finally, they must configure the container, handle apps like JupyterLab, and make sure their GPUs support the model size.
Only then are they ready to get to work. It is a lot to do, even for experts.
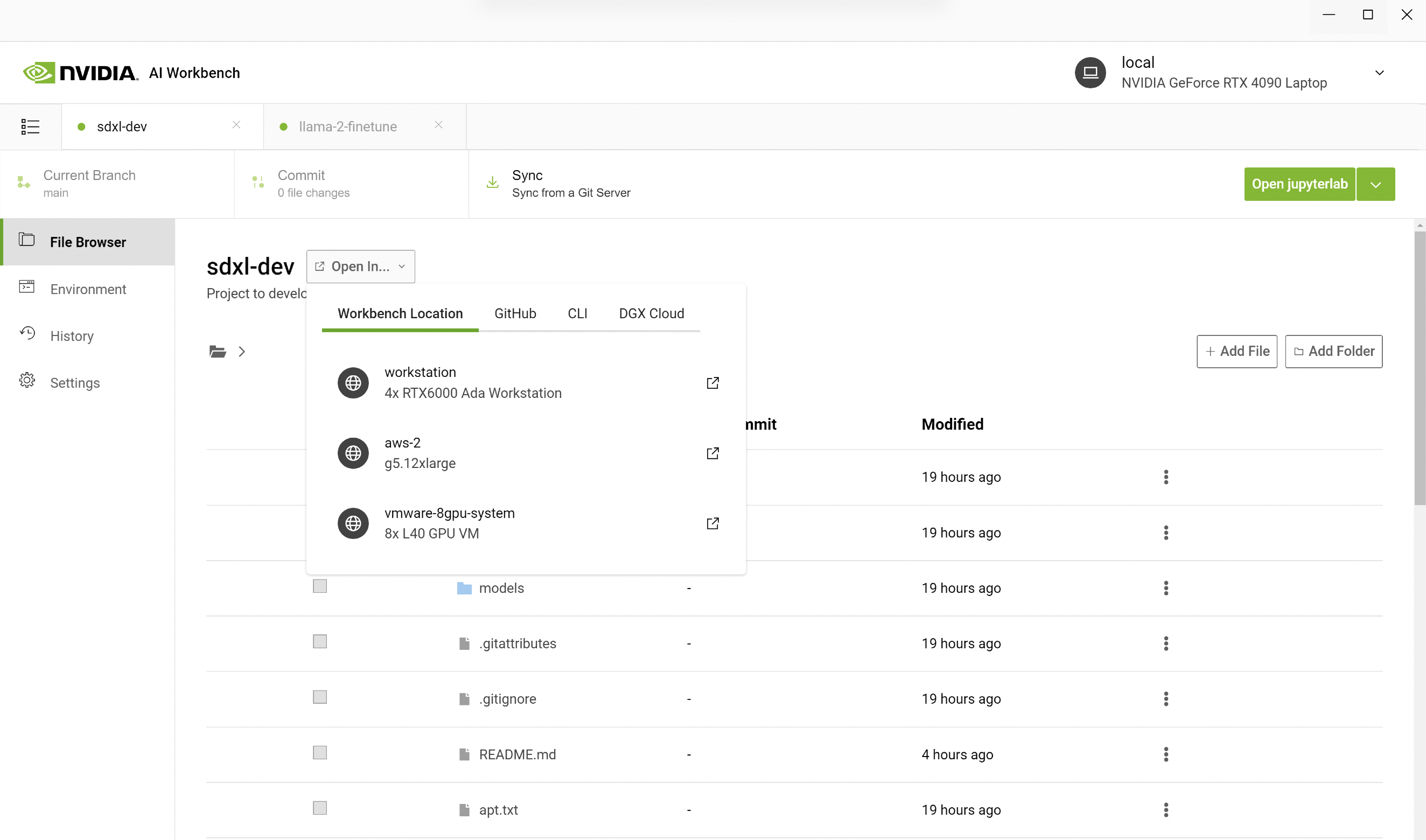
AI Workbench makes it easy to accomplish the entire process by cloning a Workbench project from GitHub. The following example outlines the steps that our team took when creating a Toy Jensen image.
We started by opening AI Workbench on a PC and cloning a repo with the URL. Instead of running Jupyter Notebook locally, we opened it on a remote workstation with more GPUs. In AI Workbench, you can select your workstation and open the Jupyter Notebook.
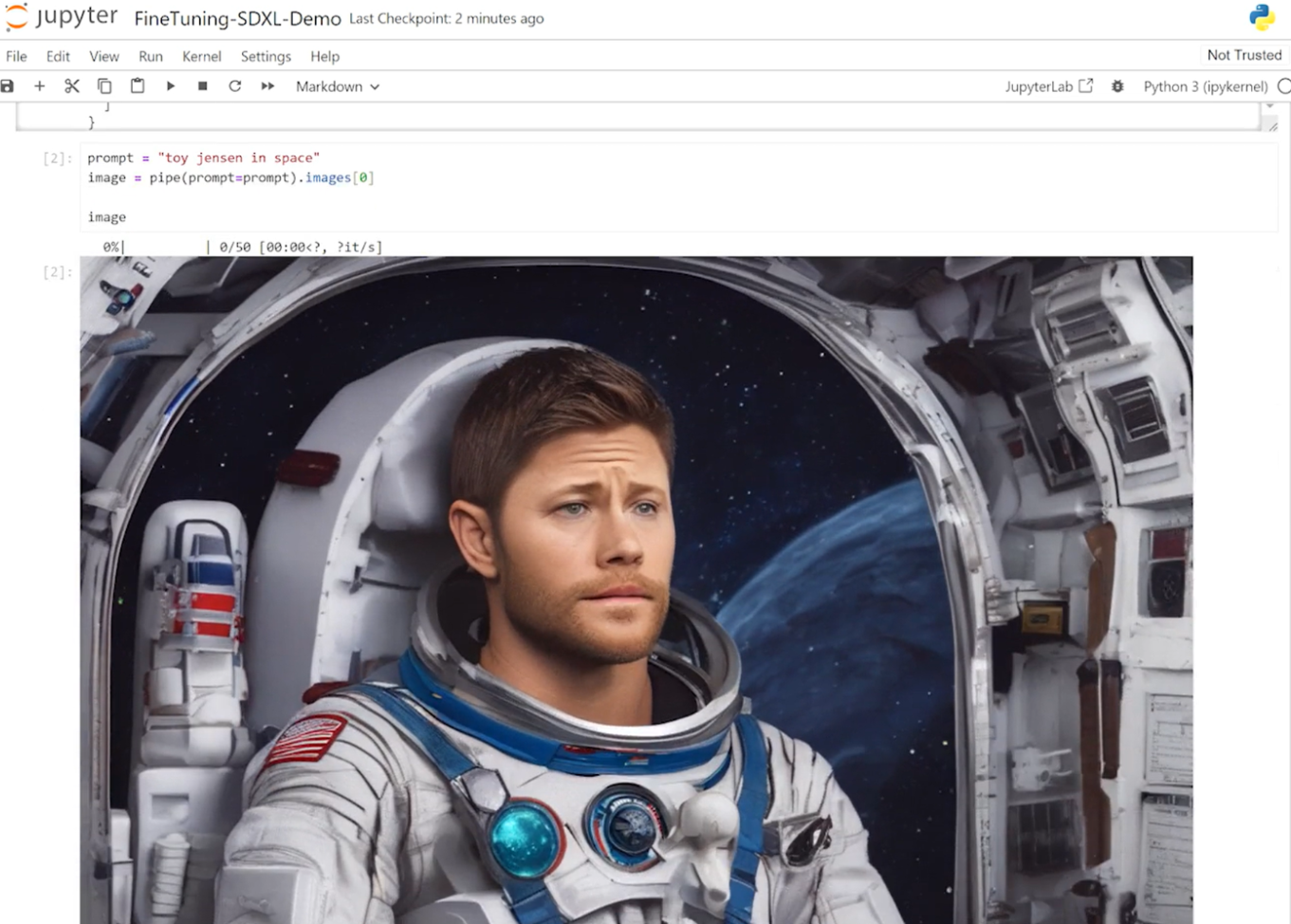
In the Jupyter Notebook, we loaded the pretrained Stable Diffusion XL model from Hugging Face and asked it to generate an image of “Toy Jensen in space.” However, based on the output image, the model doesn’t know who Toy Jensen is.
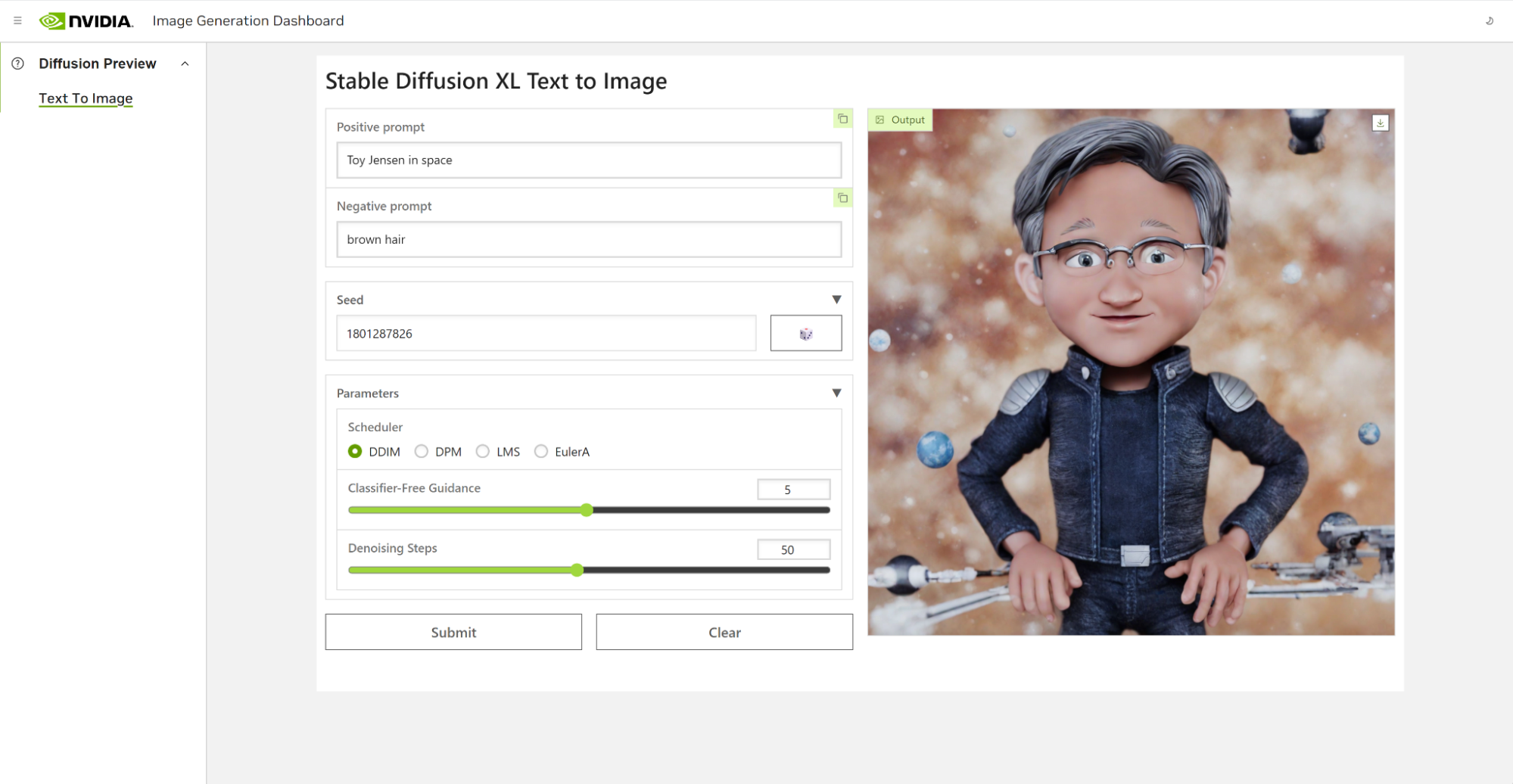
Using DreamBooth to fine-tune the model enabled us to personalize it to a specific subject of interest. In the case of Toy Jensen, we used eight photos of Toy Jensen to fine-tune the model and get good results. Now we’re ready to rerun inference with the user interface. The model now knows what Toy Jensen looks like and can produce better pictures, as shown in Figure 4.
Fine-tuning Llama 2 for medical reasoning
Larger models like Llama 2 70B require a bit more accelerated compute power for both fine-tuning and inference. In this demo, we needed to set up GPUs in the data center to be able to customize the model.
Normally, the work that goes into setting up environments, connecting services, downloading resources, configuring containers, and so on is done on a remote resource. With AI Workbench, we only have to clone a project from GitHub and click Start JupyterLab.
The goal of this demo is to use the Llama-2 model to build a specialized chatbot for a medical use case. Out of the box, the Llama-2 model does not respond well to medical questions about research papers, so we must customize the model.
Starting on a laptop, we connect to eight NVIDIA L40 GPUs running in either the data center or the cloud. The local project is migrated to a remote machine using AI Workbench.
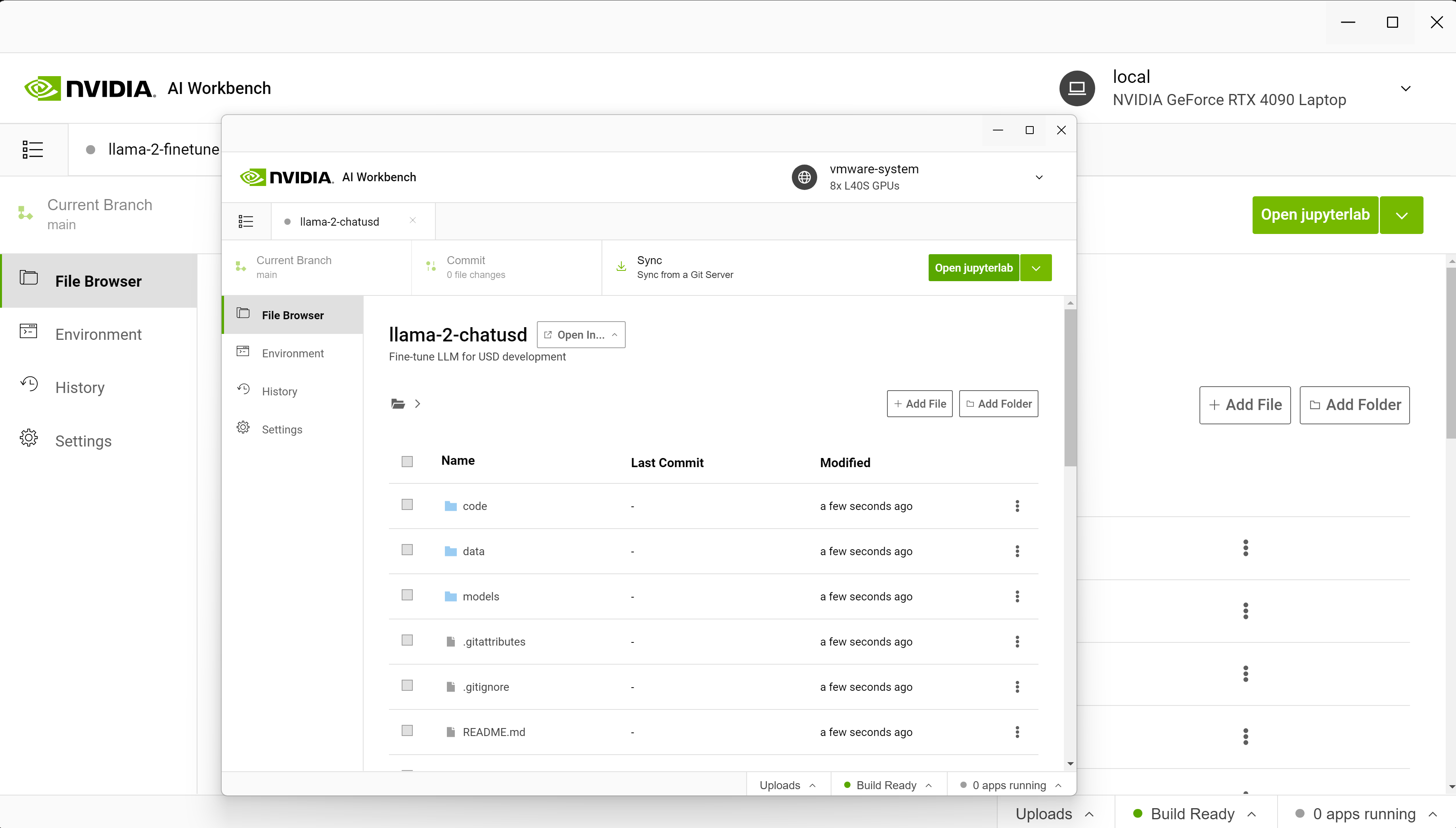
From AI Workbench, a Jupyter environment is launched and includes the P-tuning notebook where we load the pretrained Llama-2 model.
Next, we use NeMo to P-tune it with the open-source PubMedQA dataset. Then, we open the user interface to run inference again, and now our model more accurately answers questions about previously unknown ailments based on given medical context.
In this example, we provided the following prompt to guide the tuned model on how to respond.
| OBJECTIVE: To determine the ability of early sonograms to predict the presentation of twin A at birth. METHODS: Sonogram records were reviewed for the presentation of twin A at seven gestational age intervals and inpatient medical records were reviewed for the presentation of twin A at delivery. RESULTS: The positive predictive value of cephalic presentation of twin A as determined by ultrasound for the persistence of cephalic presentation at delivery reached 95% after 28 weeks gestation. The positive predictive value for noncephalic presentation as established by sonogram for noncephalic at delivery was >90% after 32 weeks gestation. QUESTION: Can third-trimester ultrasound predict the presentation of the first twin at delivery? |
The p-tuned model was able to respond to the prompt correctly with information that it learned from the PubMedQA dataset.
| ANSWER: Yes, third-trimester ultrasound can predict the presentation of the first twin at delivery with a high degree of accuracy. According to the study you provided, the positive predictive value of cephalic presentation of twin A as determined by ultrasound for the persistence of cephalic presentation at delivery reached 95% after 28 weeks gestation. Similarly, the positive predictive value for noncephalic presentation as established by sonogram for noncephalic presentation at delivery was >90% after 32 weeks gestation. These findings suggest that ultrasound in the third trimester can provide a reliable prediction of the presentation of the first twin at birth. However, it’s important to note that ultrasound is not always 100% accurate and other factors such as fetal movement and positioning can affect the accuracy of the prediction. |
With AI Workbench users can quickly create or clone existing generative AI projects to get started. Developers can go from early exploration on local machines, all the way up to model tuning on workstations and push into scalable resources in the cloud and data center for large-scale training.
Cost-effective scalability of generative AI using NVIDIA AI Workbench
As AI models become increasingly complex and computationally intensive, it’s essential for developers to have cost-effective tools that enable them to scale up quickly and efficiently. AI Workbench provides a single platform for managing data, models, and compute resources, for seamless collaboration and deployment across machines and environments. With this platform, developers of all skill levels can quickly create and deploy cost-effective, scalable generative AI models.
To learn more about AI Workbench, or to sign up to be notified about the availability of early access, visit the AI Workbench page.
