
大規模言語モデル (LLM) は自然言語理解、AI、機械学習における高度な機能を実現し、データ サイエンスに革命をもたらしています。ドメイン固有の洞察に合わせてカスタマイズされた LLM は、企業向けアプリケーションでますます注目されています。
NVIDIA Nemotron-3 8B ファミリの基盤モデルは、カスタマー サービス AI チャットボットから最先端の AI 製品にまで、企業向けに本番利用可能な生成 AI アプリケーションを構築するための強力な新しいツールです。
これらの新しい基盤モデルは、企業での利用に合わせて LLM を構築、カスタマイズ、展開するためのエンドツーエンドのフレームワークである NVIDIA NeMo の一部です。企業はこのツールを使用することで、AI アプリケーションを迅速かつコスト効率よく大規模に開発できるようになります。これらのアプリケーションは、クラウド、データ センター、Windows デスクトップ、ノート PC 上で実行できます。
Nemotron-3 8B ファミリは、Azure AI モデル カタログ、HuggingFace、および NVIDIA NGC カタログの NVIDIA AI Foundation Model ハブで入手可能です。このファミリには、さまざまな下流タスクを解決するために設計されたベース、チャット、質疑応答 (Q&A) の各モデルがあります。表 1 に基盤モデルの全ファミリをまとめます。
| モデル | バリアント | 主な利点 |
| ベース | Nemotron-3-8B-Base | 分野に適応した LLM のパラメーター効率の高いファインチューニングや継続的な事前トレーニングなどのカスタマイズを可能にします |
| チャット | Nemotron-3-8B-Chat-SFT | カスタム モデルやユーザー定義のアライメント (RLHF モデルや SteerLM モデルなど) をチューニングする命令用のビルディング ブロック |
| Nemotron-3-8B-Chat-RLHF | すぐに使用でき、優れたパフォーマンスをもたらすチャット モデル | |
| Nemotron-3-8B-Chat-SteerLM | 推論時の柔軟な調整ができ、すぐに使用できる優れたチャット モデル | |
| 質疑応答 | Nemotron-3-8B-QA | ナレッジ ベースでカスタマイズされる Q&A 用 LLM |
本番利用可能な基盤モデルを設計
基盤モデルは、有用なカスタム アプリケーションの構築に必要な時間とリソースを削減する強力な構成要素です。しかし、組織はこれらのモデルが企業要件を満たしていることを確認する必要があります。
NVIDIA AI Foundation モデルは、多様な声や経験を捉えた責任あるデータセットでトレーニングされています。厳格なモニタリングにより、データの信頼性が保証され、進化する法的規定に準拠できます。データの問題が発生しても迅速に対処でき、企業は法的規範とユーザーのプライバシーの両方に準拠した AI アプリケーションを開発することができます。これらのモデルでは、公開されているデータセットとドメイン固有のデータセットの両方を取り込むことができます。
Nemotron-3-8B ベース
Nemotron-3-8B ベース モデルは、人間が作成したようなテキストやコードを生成できる、コンパクトで高性能なモデルです。このモデルの MMLU (5-shot) の平均値は 54.4 です。多言語機能にも対応しており、英語、ドイツ語、ロシア語、スペイン語、フランス語、日本語、中国語、イタリア語、オランダ語など 53 言語に堪能でグローバル企業のニーズにも応えます。この基盤モデルは、37 種類の異なるコーディング言語でもトレーニングされています。
Nemotron-3-8B チャット
スイートには、LLM によるチャットボットのやり取りを対象にする Nemotron-3-8B チャット モデルが追加されます。3つのチャット モデルのバージョンがあり、それぞれユーザー固有の調整に対応するように設計されています。
- 教師ありファインチューニング (SFT)
- 人間のフィードバックからの強化学習 (RLHF)
- NVIDIA SteerLM
Nemotron-3-8B-SFT モデルは命令チューニングの最初のステップであり、そこから、チャット品質の指標として最も引用される 8B カテゴリ内で最高の MT-Bench スコアを持つ RLHF モデルを構築します。最良の即時チャット インタラクションを実現するには 8B-chat-RLHF から始めることをお勧めしますが、エンド ユーザーの好みに合わせて独自に調整することに関心がある企業の場合は、独自の RLHF を適用しながら SFT モデルの使用を推奨します。
最後に、最新の調整手法である SteerLM は、推論時の LLM のトレーニングとカスタマイズに新しいレベルの柔軟性をもたらします。SteerLM を使用するユーザーは必要なすべての属性を定義し、単一のモデルに埋め込むことができます。その後、モデルの実行中に、特定のユースケースに必要な組み合わせを選択できます。
この方法により、継続的な改善サイクルが可能になります。カスタム モデルからの応答は、モデルを新たなレベルの有用性へと導く将来のトレーニング実行のデータとして機能します。
Nemotron-3-8B 質疑応答
Nemotron-3-8B-QA モデルは、ターゲットのユース ケースに焦点を当てた大量のデータに基づいてファインチューニングされた質疑応答 (QA) モデルです。
Nemotron-3-8B-QA モデルは最先端のパフォーマンスを提供し、Natural Questions データセットで 41.99% の zero-shot F1 スコアを達成しました。この指標は、生成された回答が QA の真実にどの程度近いかを測定します。
Nemotron-3-8B-QA モデルは、より大きなパラメーター サイズを持つ他の最先端の言語モデルと比較してテストされています。このテストは、NVIDIA が作成したデータセット、Natural Question、Doc2Dial データセットで実施されました。その結果、このモデルがうまく機能することが示されています。
NVIDIA NeMo フレームワークでカスタム LLM を構築
NVIDIA NeMo は、複数のモデル アーキテクチャにエンドツーエンドの機能とコンテナー化されたレシピを提供することで、カスタマイズされたエンタープライズ生成 AI モデルを構築する方法を簡素化します。開発者は Nemotron-3-8B ファミリのモデルを使用すると、特定のユース ケースに容易に適応できる NVIDIA の事前トレーニング済みモデルにアクセスできます。
迅速なモデル展開
NeMo フレームワークを使用する場合、データの収集やインフラストラクチャのセットアップは必要ありません。NeMo はプロセスを合理化します。開発者は既存のモデルをカスタマイズし、本番環境に素早く展開できます。
モデルのパフォーマンス最適化
さらに、モデルのパフォーマンスを最適化する NVIDIA TensorRT-LLM オープンソース ライブラリや、推論処理プロセスを高速化する NVIDIA Triton Inference Server とシームレスに統合されます。このツールの組み合わせで最先端の精度、低レイテンシ、高スループットが可能になります。
データのプライバシーとセキュリティ
NeMo は、安全性とセキュリティの規制に準拠した安全かつ効率的な大規模展開を可能にします。例えば、データ プライバシーがビジネスにとって重要な懸念事項である場合、NeMo Guardrails を使用することで、パフォーマンスや信頼性を損なうことなく顧客データを安全に保存できます。
全体的に、NeMo フレームワークを使用してカスタム LLM を構築することは、品質やセキュリティ基準を犠牲にすることなくエンタープライズ AI アプリケーションを迅速に作成する効果的な方法です。開発者には、カスタマイズに柔軟があり、大規模展開に必要な堅牢なツールを提供します。
Nemotron-3-8B の活用
NeMo フレームワークを使用すると、Nemotron-3-8B モデルで推論を容易に実行できます。このフレームワークは、TensorRT-LLM を活用したオープン ソース ライブラリであり、NVIDIA GPU 上で効率的かつ容易な LLM 推論を提供します。
- KV キャッシング
- 効率的な Attention モデル (MQA、GQA、Paged Attention など)
- インフライト (連続) バッチ処理
- 低精度 (INT8/FP8) 量子化のサポート、およびその他の最適化。
NeMo フレームワーク推論コンテナーには、Nemotron-3-8B ファミリなどの NeMo モデルに TensorRT-LLM 最適化を適用して Triton Inference Server でホストするために必要なすべてのスクリプトと依存関係が含まれています。展開後、推論クエリを送信できるエンドポイントが公開されます。
前提条件
展開と推論を行うには以下のものが必要です。
- NVIDIA データ センター GPU: (1) A100 – 40 GB / 80 GB、(2) H100 – 80 GB、(3) L40S 以上。
- NVIDIA NeMo フレームワーク: Nemotron-3-8B ファミリのモデルをカスタマイズまたは展開するためのトレーニング コンテナーと推論コンテナーの両方を提供。
Azure ML に展開する手順
Nemotron-3-8B ファミリのモデルは Azure ML モデル カタログで入手でき、Azure ML マネージド エンドポイントに展開することができます。AzureML は、Nemotron-3-8B ファミリのモデル展開が非常に容易にする「ノーコード展開」フローを提供しています。NeMo フレームワーク推論コンテナーの基盤となるプラットフォームに統合されています。
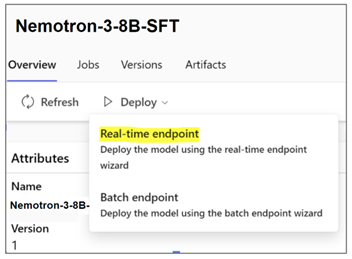
NVIDIA 基盤モデルを推論のために Azure ML へ展開するには、次の手順に従ってください。
- Azure アカウントにログインする: https://portal.azure.com/#home
- Azure ML Machine Learning スタジオに移動する
- ワークスペースを選択し、モデル カタログに移動する
NVIDIA AI Foundation モデルは、Azure 上でのファインチューニング、評価、展開に利用できます。モデルのカスタマイズは、NeMo トレーニング フレームワークを使用して Azure ML 内で行うことができます。トレーニング コンテナーと推論コンテナーで構成される NeMo フレームワークは、すでに AzureML 内に統合されています。
基盤モデルをファインチューニングするには、好きなモデル バリアントを選択し、[ファインチューニング] をクリックして、タスク タイプ、カスタム トレーニング データ、トレーニングと検証の分割、コンピューティング クラスターなどのパラメーターを入力します。
モデルを展開するには、好きなモデル バリアントを選択し、[リアルタイム エンドポイント] をクリックして、インスタンス、エンドポイント、その他のパラメーターを選択すると展開をカスタマイズできます。[展開] をクリックして、推論用のモデルをエンドポイントに展開します。
Azure CLI と SDK のサポートは、Azure ML 上でファインチューニング ジョブと展開を実行する際にも利用できます。詳細については、「Foundation Models in Azure ML」のドキュメントをご一読ください。
オンプレミスまたは他のクラウドに展開する手順
Nemotron-3-8B ファミリのモデルでは、推論リクエスト用の個別のプロンプト テンプレートがベスト プラクティスとして推奨されていますが、同じベース アーキテクチャを共有しているため、それらを展開する手順は似ています。
NeMo フレームワーク推論コンテナを使用した展開に関する最新の手順については、https://registry.ngc.nvidia.com/orgs/ea-bignlp/teams/ga-participants/containers/nemofw-inference を参照してください。
デモとして、Nemotron-3-8B-Base-4k を展開してみましょう。
- NGC カタログにログインし、推論コンテナーを取得する
# log in to your NGC organization
docker login nvcr.io
# Fetch the NeMo framework inference container
docker pull nvcr.io/ea-bignlp/ga-participants/nemofw-inference:23.10- モデルをダウンロードする。8B ファミリのモデルは、NGC カタログもしくは Hugging Face で入手可能。どちらからモデルをダウンロードしても構いません。
NVIDIA NGC
NGC からモデルをダウンロードする最も容易な方法は、CLI を使用することです。NGC CLI がインストールされていない場合は、「Getting Started instructions」(使用開始の手順) に従ってインストールし、設定してください。
# Downloading using CLI. The model path can be obtained from it’s page on NGC
ngc registry model download-version "dztrnjtldi02/nemotron-3-8b-base-4k:1.0"Hugging Face Hub
以下のコマンドでは git-lfs を使用しますが、Hugging Face でサポートされている方法のどれを使用してもモデルをダウンロードできます。
git lfs install
git clone https://huggingface.co/nvidia/nemotron-3-8b-base-4k nemotron-3-8b-base-4k_v1.0- 推論コンテナーをインタラクティブ モードで実行し、関連するパスをマウントする
# Create a folder to cache the built TRT engines. This is recommended so they don’t have to be built on every deployment call.
mkdir -p trt-cache
# Run the container, mounting the checkpoint and the cache directory
docker run --rm --net=host \
--gpus=all \
-v $(pwd)/nemotron-3-8b-base-4k_v1.0:/opt/checkpoints/ \
-v $(pwd)/trt-cache:/trt-cache \
-w /opt/NeMo \
-it nvcr.io/ea-bignlp/ga-participants/nemofw-inference:23.10 bash- TensorRT-LLM バックエンドを備えた Triton Inference Server にモデルを変換し、展開する
python scripts/deploy/deploy_triton.py \
--nemo_checkpoint /opt/checkpoints/Nemotron-3-8B-Base-4k.nemo \
--model_type="gptnext" \
--triton_model_name Nemotron-3-8B-4K \
--triton_model_repository /trt-cache/8b-base-4k \
--max_input_len 3000 \
--max_output_len 1000 \
--max_batch_size 2このスクリプトは、構築した TensorRT-LLM エンジン ファイルを「-triton_model_repository」で指定されたパスにエクスポートすることに注意してください。その後の展開でエンジンを再構築せずにエクスポートされたモデルをロードするには、「-nemo_checkpoint」、「-max_input_len」、「-max_output_len」、「max_batch_size」の各引数をスキップできます。このスクリプトの使用方法の詳細については、こちらのドキュメントを参照してください。
このコマンドが正常に完了すると、クエリできるエンドポイントが出現します。どうすればそれが可能になるかを見てみましょう。
推論を実行する手順
推論を実行するために使用できるオプションは複数あり、サービスをどのように統合するかによって決定します。
- NeMo フレームワーク推論コンテナーで使用できる NeMo クライアント API を使用する
- PyTriton を使用して環境内にクライアント アプリを作成する
- 展開したサービスによって HTTP エンドポイントが出現するため、HTTP リクエストを送信できるライブラリ/ツールを使用する
NeMo クライアント API を使用するオプション 1 の例を以下に示します。これは、サービス IP とポートにアクセスできる同じマシンまたは別のマシン上の NeMo フレームワーク推論コンテナーから使用できます。
from nemo.deploy import NemoQuery
# In this case, we run inference on the same machine
nq = NemoQuery(url="localhost:8000", model_name="Nemotron-3-8B-4K")
output = nq.query_llm(prompts=["The meaning of life is"], max_output_token=200, top_k=1, top_p=0.0, temperature=0.1)
print(output)他のオプションの例については、推論コンテナーの README で入手できます。
注: チャット モデル (SFT、RLHF、SteerLM) は、応答を「<extra_id_1>」で終了するようにトレーニングされているため、出力の後処理が必要ですが、`NemoQuery` API はこの特別なトークンが生成されるタイミングでの生成の自動停止にまだ対応していません。自動停止は、「output」を次のように変更することで実現可能です。
output = nq.query_llm(...)
output = [[s.split("<extra_id_1>", 1)[0].strip() for s in out] for out in output]8B ファミリのモデルのプロンプト
NVIDIA Nemotron-3-8B ファミリのモデルは、事前トレーニング済みの共通の基盤を共有しています。ただし、チャット (SFT、RLHF、SteerLM) と QA モデルのチューニングに使用されるデータセットは、個々の目的に合わせてカスタマイズされています。また、これらのモデルの構築にはさまざまなトレーニング手法が使用されます。従って、これらのモデルは、トレーニング方法と同様のテンプレートに従うカスタマイズされたプロンプトを使用すると効率性が最大限に向上します。
それぞれのモデルに推奨されるプロンプト テンプレートは、各々のモデル カードに記載されています。
例として、Nemotron-3-8B-Chat-SFT モデルと Nemotron-3-8B-Chat-RLHF モデルに適用できるシングルターン フォーマットとマルチターン フォーマットを次に示します。
| Nemotron-3-8B-Chat-SFT および Nemotron-3-8B-Chat-RLHF | |
| シングルターン プロンプト | マルチターンまたは Few-shot |
<extra_id_0>System | <extra_id_0>System |
プロンプト フィールドと応答フィールドは、入力が送信される場所に対応します。シングルターン テンプレートを使用して入力をフォーマットする例を次に示します。
PROMPT_TEMPLATE = """<extra_id_0>System
{system}
<extra_id_1>User
{prompt}
<extra_id_1>Assistant
"""
system = ""
prompt = "Write a poem on NVIDIA in the style of Shakespeare"
prompt = PROMPT_TEMPLATE.format(prompt=prompt, system=system)
print(prompt)注: Nemotron-3-8B-Chat-SFT および Nemotron-3-8B-Chat-RLHF モデルの場合は、システム プロンプトを空のままにすることをお勧めします。
さらなるトレーニングとカスタマイズ
NVIDIA Nemotron-3-8B ファミリのモデルは、ドメイン固有のデータセットをさらにカスタマイズするのに適しています。カスタマイズする上では、チェックポイントからの事前トレーニングの継続、SFT または PEFT (Parameter-Efficient Fine-Tuning)、RLHF による人のデモンストレーションとの調整、NVIDIA の新しい SteerLM 技術の使用などのオプションを利用できます。
前述した方法に対応する使いやすいスクリプトが NeMo フレームワーク トレーニング コンテナーに用意されています。また、データ キュレーション、トレーニングと推論に最適なハイパーパラメーターの特定、オンプレミス DGX Cloud、Kubernetes 対応プラットフォーム、Cloud Service Provider など、お好みのハードウェア上で NeMo フレームワークを実行できるツールも提供しています。
詳細については、NeMo Framework ユーザー ガイドまたはコンテナーの README をご確認ください。
Nemotron-3-8B ファミリのモデルはさまざまなユース ケース向けに設計されており、さまざまなベンチマークで競争力のあるパフォーマンスを発揮するだけでなく、複数の言語にも対応しています。
関連リソース
- DLI コース: Building Conversational AI Applications
- GTC セッション: Accelerate the Development of AI Solutions With AI Workflows (2023 年春)
- GTC セッション: NVIDIA NeMo Service | Boosting Enterprise Productivity with Customized Generative AI Models (2023 年春)
- SDK: NeMo
- ウェビナー: Implementing Large Language Models
- ウェビナー: What AI Teams Need to Know About Generative AI