
企業は、イノベーションを起こし、顧客に価値を提供し、競争力を維持するために、これまで以上にデータと AI に依存しています。機械学習 (ML) の導入は、信頼性が高く、コスト パフォーマンスがよく、スケーラブルなコード、データ、モデルを管理するためのツールやプロセス、組織原則の必要性を生じさせました。これは MLOps として広く知られています。
世界は、特に基盤モデルと大規模言語モデル (LLM) を活用した新しい生成 AI 時代に急速に突入しています。ChatGPT のリリースにより、この変化はさらに加速されました。
GenAIOps と LLMOps の新しい専門領域は、本番環境での生成 AI および LLM を利用したアプリの開発と管理の課題に対処するための MLOps の進化として登場しました。
この投稿では、生成 AI アプリ開発の概要を説明し、GenAIOps と LLMOps の概念を定義し、それらを MLOps と比較します。また、全社規模の AI 変革を実行するビジネス リーダーにとって、運用をマスターすることがなぜ最重要となるのかについても説明します。
企業向けの最新の生成 AI アプリの構築
最新の生成 AI アプリへの道は基盤モデルから始まり、事前トレーニング段階を経て、世界に関する基礎知識を学習し、新たな機能を獲得します。次のステップは、人間が生成したプロンプトと応答の厳選されたデータセットを使用して、モデルを人間の好み、行動、価値観に合わせることです。これにより、モデルは正確に命令に従う能力を獲得します。ユーザーは、独自の基盤モデルをトレーニングするか、事前トレーニングされたモデルを使用するかを選択できます。
例えば、NVIDIA Nemotron-3 のような様々な基盤モデルや、Llama のようなコミュニティ モデルは、NVIDIA AI Foundations を通じて利用可能です。これらはすべて、NVIDIA 独自のアルゴリズムとシステムの最適化、セキュリティ、および NVIDIA AI Enterprise がカバーするエンタープライズグレードのサポートによって強化されています。
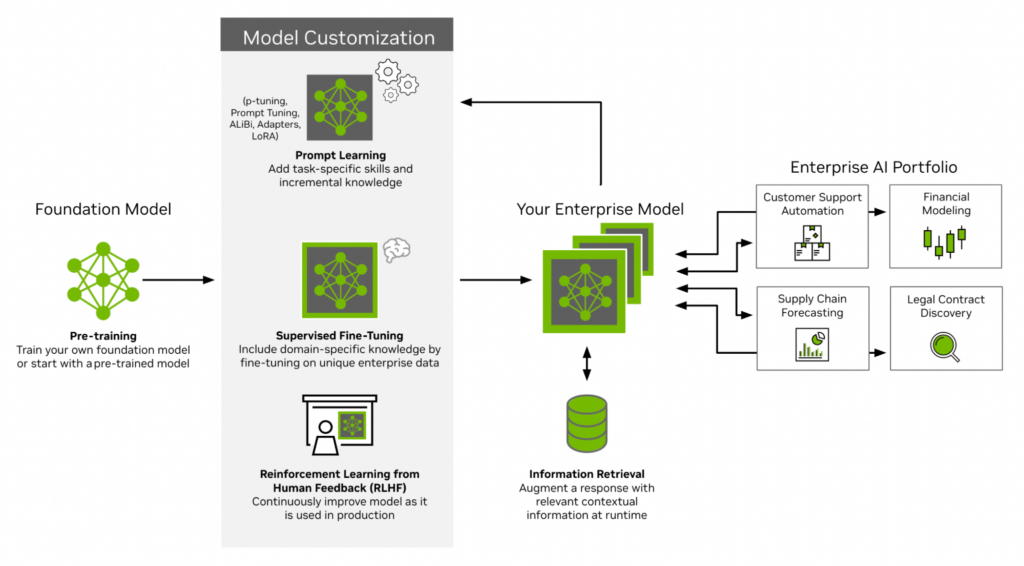
次に、カスタマイズの段階です。基盤モデルは、タスク固有のプロンプトと組み合わせられるか、厳選されたエンタープライズ データセットでファインチューニングされます。基盤モデルの知識は事前トレーニングとファインチューニング用データに限定されており、モデルを継続的に再トレーニングしないと時間の経過とともに古くなり、コストがかかる可能性があります。
Retrieval-Augmented Generation (RAG) ワークフローは、クエリ時に情報を最新の状態に維持し、グラウンディングするために使用されます。これは、生成 AI アプリ開発ライフサイクルにおいて最も重要なステップの 1 つであり、モデルが企業データに隠された固有の関係を学習する際に行われます。
カスタマイズ後、モデルは単独で、または複数の基盤モデルと API を組み合わせてエンドツーエンドのアプリケーション ロジックを提供するチェーンの一部として実際に使用できるようになります。この時点で、完全な AI システムの正確度度、速度、脆弱性をテストし、モデルの出力が正確で安全であることを確認するためのガードレールを追加することが重要です。
最後に、フィードバック ループが閉じます。ユーザーは、ユーザー インターフェイスを通じてアプリを操作するか、システム インストゥルメンテーションを使用してデータを自動的に収集します。この情報を使用してモデルと A/B テストを継続的に更新し、顧客にとっての価値を高めることができます。
通常、企業には、さまざまなユース ケース、ビジネス機能、ワークフローに合わせて調整された多数の生成 AI アプリがあります。この AI ポートフォリオには、スムーズな運用、倫理的な使用、インシデント、偏見、または回帰に対処するための迅速なアラートを確保するために、継続的な監視とリスク管理が必要です。
GenAIOps は、自動化を通じて研究から生産までのこの過程を加速します。開発コストと運用コストを最適化し、モデルの品質を向上させ、モデル評価プロセスに堅牢性を追加し、大規模な継続的な運用を保証します。
GenAIOps、LLMOps、RAGOps について
生成 AI には関連するいくつかの用語があります。次のセクションで定義の概要を説明します。
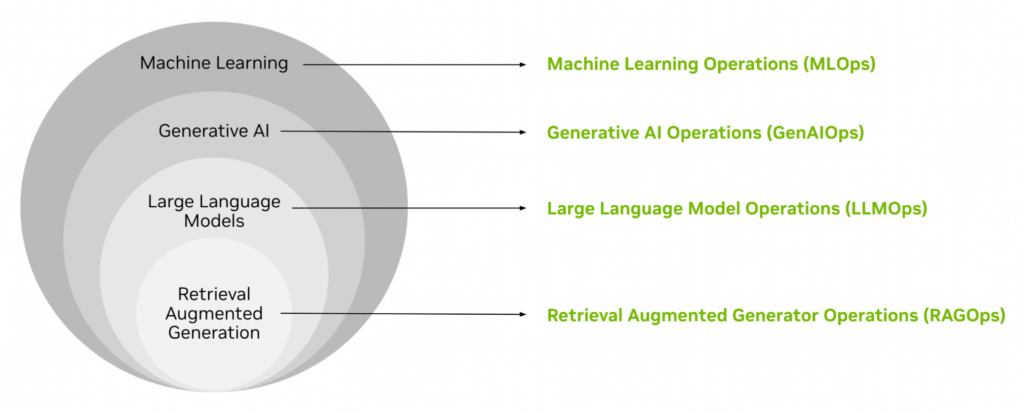
AI を一連の入れ子になったレイヤーとして考えてみましょう。ML は最も外側の層で、プログラムのロジックが明示的に定義されず、データから学習されるインテリジェントな自動化をカバーします。さらに深く掘り下げていくと、LLM や RAG に基づいて構築された AI タイプなどの特殊な AI タイプにたどり着きます。同様に、再現性、再利用、スケーラビリティ、信頼性、効率性を可能にする入れ子の概念があります。
それぞれは、基本的な MLOps から新しく開発された RAGOps ライフサイクルに至るまで、以前の機能を追加、または改良して構築されています。
- MLOps は、実稼働環境でのエンドツーエンドの機械学習システムの開発と運用のための中核となるツール、プロセス、ベスト プラクティスを網羅する包括的な概念です。
- GenAIOps は、MLOps を拡張して生成 AI ソリューションを開発および運用します。GenAIOps の明確な特徴は、基盤モデルの管理と基盤モデルとの対話です。
- LLMOps は、LLM ベースのソリューションの開発と運用に特に焦点を当てた、別個のタイプの GenAIOps です。
- RAGOps は、RAG の配信と運用に焦点を当てた LLMOps のサブクラスであり、大規模な導入を促進する生成 AI および LLM の究極のリファレンス アーキテクチャとも考えられます。
GenAIOps と LLMOps は AI ライフサイクル全体に及びます。これには、基盤モデルの事前トレーニング、教師付きファインチューニングによるモデルの調整、ヒューマン フィードバックからの強化学習 (RLHF)、前処理/後処理ロジックと組み合わせた特定のユース ケースへのカスタマイズ、他の基盤モデル、API、ガードレールとのチェーンが含まれます。RAGOps の範囲には事前トレーニングは含まれておらず、基盤モデルが RAG ライフサイクルへの入力として提供されることを前提としています。
GenAIOps、LLMOps、RAGOps は、AI 開発を可能にするツールやプラットフォーム機能だけを意味するものではありません。また、目標と KPI の設定、チームの組織化、進捗状況の測定、運用プロセスの継続的な改善のための方法論もカバーしています。
生成 AI および LLM 向けの MLOps の拡張
主要な概念を定義すると、一方を他方と区別するニュアンスに焦点を当てることができます。
MLOps
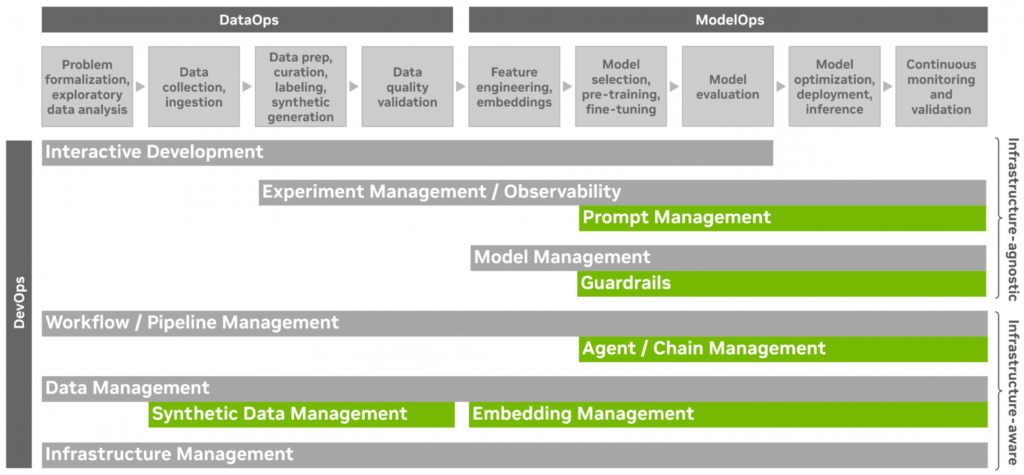
MLOps は、実稼働環境での機械学習モデルの開発、トレーニング、評価、最適化、展開、推論、監視に対する構造化されたアプローチの基礎を築きます。
生成 AI に関連する MLOps の主要なアイディアと能力には、以下のようなものがあります。
- インフラ管理: 基盤となるハードウェアにプログラムでアクセスするために、コンピューティング、ストレージ、およびネットワーキング リソースを要求、プロビジョニング、構成します。
- データ管理: トレーニングと評価のためにデータを収集、取り込み、保存、処理、ラベル付けします。役割ベースのアクセス制御を構成します。データセットの検索、参照、探索。データの出所追跡、データログ、データセットのバージョン管理、メタデータのインデックス作成、データ品質の検証、データセットカード、データ可視化のためのダッシュボード。
- ワークフローとパイプラインの管理: クラウド リソースまたはローカル ワークステーションを使用し、データの準備、モデルのトレーニング、モデルの評価、モデルの最適化、モデルの展開の各ステップを、データとコンピューティングを組み合わせたエンドツーエンドの自動化されたスケーラブルなワークフローに接続します。
- モデル管理: 実稼働用にモデルをトレーニング、評価、最適化します。モデルをモデル カードとともに一元化されたモデル レジストリに保存し、バージョン付けします。モデルのリスクを評価し、標準への準拠を確保します。
- 実験の管理と可観測性: トレーニング データ、モデル、ハイパーパラメーターの変更など、さまざまな機械学習モデルの実験を追跡および比較します。可能なモデル アーキテクチャの空間と特定のモデル アーキテクチャのハイパーパラメーターを自動的に検索します。推論中のモデルのパフォーマンスを分析し、コンセプトのドリフトについてモデルの入力と出力を監視します。
- インタラクティブな開発: 開発環境を管理し、外部のバージョン管理システム、デスクトップ IDE、その他のスタンドアロン開発者ツールと統合することで、チームのプロトタイプ作成、ジョブの立ち上げ、プロジェクトでの共同作業を容易にします。
GenAIOps
GenAIOps には、言語から画像、マルチモーダルに至るすべての生成 AI ワークロードに対する MLOps、DevOps、DataOps、および ModelOps が含まれます。生成 AI については、データのキュレーションとモデルのトレーニング、カスタマイズ、評価、最適化、展開、リスク管理を再考する必要があります。
新しい GenAIOps 機能には次のものが含まれます。
- 合成データ管理: 新しいネイティブの生成 AI 機能でデータ管理を拡張します。ドメインのランダム化を通じて合成トレーニング データを生成し、転移学習機能を強化します。エッジ ケースを宣言的に定義および生成して、モデルの精度と堅牢性を評価、検証、証明します。
- 埋め込み管理: あらゆるモダリティのデータ サンプルを高密度の多次元埋め込みベクトルとして表現します。ベクトル データベース内の埋め込みを生成、保存、およびバージョン管理します。埋め込みを可視化し、即座に探索します。アクティブ ラーニング ループの一部として、RAG のベクトル類似性検索、データ ラベリング、またはデータ キュレーションを通じて、関連するコンテキスト情報を見つけます。GenAIOps の場合、埋め込みとベクトル データベースを使用することで、MLOps に関連する機能管理と機能ストアが置き換えられます。
- エージェント/チェーン管理: 複雑な複数ステップのアプリケーション ロジックを定義します。RAG パターンに従って、複数の基盤モデルと API を結合し、外部メモリと知識で基盤モデルを強化します。非決定的な出力または複雑な計画戦略を使用してチェーンをデバッグ、テスト、トレースし、複数ステップのチェーンの実行フローをリアルタイムおよびオフラインで可視化および検査します。エージェント/チェーン管理は、推論パイプラインの重要な部分として、生成 AI ライフサイクル全体を通じて価値があります。これは、MLOps のワークフロー/パイプライン管理の拡張機能として機能します。
- ガードレール: 敵対的な入力またはサポートされていない入力を基盤モデルに送信する前に防ぎます。モデルの出力が正確で、関連性があり、安全であることを確認します。会話とアクティブなコンテキストの状態を維持および確認し、意図を検出し、コンテンツ ポリシーを適用しながらアクションを決定します。ガードレールは、モデル管理の対象となる AI の入力/出力のルールベースの前処理/後処理に基づいて構築されます。
- プロンプト管理: プロンプトの作成、保存、比較、最適化、バージョン管理を行います。プロンプト エンジニアリング中に、入力と出力を分析し、テスト ケースを管理します。パラメーター化されたプロンプト テンプレートを作成し、最適な推論時間のハイパーパラメーターと、ユーザーとアプリの対話時の開始点として機能するシステム プロンプトを選択します。各基盤モデルのプロンプトを調整します。独自の機能を備えたプロンプト管理は、生成 AI の実験管理の論理的な拡張です。
LLMOps
LLMOps は、より広範な GenAIOps パラダイムのサブセットであり、運用アプリケーションでの言語ユースケース向けの Transformer ベースのネットワークの運用化に焦点を当てています。言語は、AI システムの動作をガイドするために他のモダリティと組み合わせることができる基本的なモダリティです。NVIDIA Picasso は、ビジュアル コンテンツ制作のためにテキストと画像のモダリティを組み合わせたマルチモーダル システムです。
この場合、テキストは、特定のタスクのプラグインとして使用される他のデータ モダリティと基盤モデルを使用して AI システムの制御ループを駆動します。自然言語インターフェイスはユーザーと開発者の基盤を拡大し、AI 導入の障壁を減らします。LLMOps に含まれる一連の操作には、プロンプト管理、エージェント管理、RAGOps があります。
RAGOps で生成 AI の導入を推進
RAG は、汎用の LLM の機能を強化するために設計されたワークフローです。クエリ時に独自のデータセットからの情報を組み込み、生成された回答を事実に基づいて作成することで、事実の正確性が保証されます。従来のモデルは、外部の知識を必要とせずに感情分析などのタスク向けにファインチューニングできますが、RAG は、質問応答など、外部の知識ソースにアクセスすることで恩恵を受けるタスク向けに調整されています。
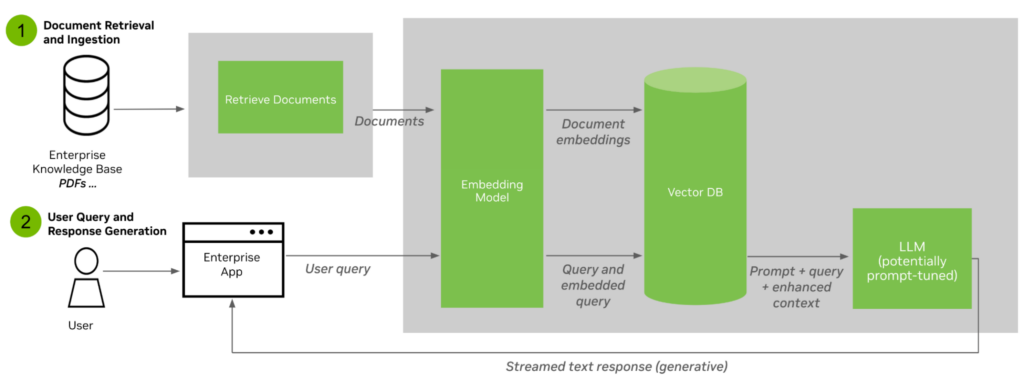
RAG は、情報検索コンポーネントとテキスト ジェネレーターを統合します。このプロセスは次の 2 つのステップで構成されます。
- ドキュメントの取得と取り込み – ドキュメントを取り込み、埋め込みモデルを使用してテキストをチャンク化してベクトルに変換し、ベクトル データベースに保存するプロセス。
- ユーザーのクエリと応答の生成 – ユーザー クエリは、クエリ時に埋め込みモデルとともに埋め込み空間に変換され、その結果、ベクトル データベースに対して最もよく一致するチャンクとドキュメントを検索するために使用されます。元のユーザー クエリとトップ ドキュメントは、カスタマイズされたジェネレーター LLM に供給され、最終応答が生成されてユーザーに返されます。
また、包括的な再トレーニングを必要とせずに知識を更新できるという利点もあります。このアプローチは、生成された応答の信頼性を確保し、出力における「ハルシネーション」の問題に対処します。
RAGOps は LLMOps の拡張です。これには、埋め込みモデルと検索モデルとともに、従来の意味とベクトル化された形式の両方でドキュメントとデータベースを管理することが含まれます。RAGOps は、生成 AI アプリ開発の複雑さを 1 つのパターンに抽出します。したがって、より多くの開発者が新しい強力なアプリケーションを構築できるようになり、AI 導入の障壁が軽減されます。
GenAIOps がもたらす多くのビジネス上の利点
研究者や開発者が GenAIOps をマスターして DevOps、DataOps、ModelOps を超えて拡張すると、ビジネス上のメリットが数多く生まれます。これらには以下が含まれます。
- 市場投入までの時間の短縮: エンドツーエンドの生成 AI ワークフローの自動化と高速化は、AI 製品のイテレーション サイクルの短縮につながり、組織をよりダイナミックにし、新しい課題への適応性を高めます。
- より高い収率と革新性: AI システム開発プロセスを簡素化し、抽象化レベルを高めることで、GenAIOps の実験が増え、エンタープライズ アプリケーション開発者のエンゲージメントを高め、AI 製品リリースが最適化します。
- リスクの軽減: 基盤モデルは業界に革命を起こす可能性を秘めていますが、トレーニング データに固有のバイアスや不正確さを増幅させるリスクも孕んでいます。1 つの基盤モデルの欠陥は、下流のすべてのモデルとチェーンに伝播します。GenAIOps は、これらの欠陥を最小限に抑え、倫理的課題に正面から取り組むという積極的な姿勢を確保します。
- 効率的なコラボレーション: GenAIOps は、1 つのプロジェクト内でデータ エンジニアリングから研究、製品エンジニアリングに至るまで、チーム間でのスムーズな引き継ぎを可能にし、プロジェクト全体で成果物や知識の共有を促進します。複数のチームの同期を維持するには、厳格な運用の厳密さ、標準化、および共同ツールが必要です。
- 無駄のない運用: GenAIOps は、ワークロードの最適化、日常的なタスクの自動化、AI ライフサイクルのあらゆる段階での専用ツールの可用性を通じて無駄を削減します。これにより、生産性が向上し、TCO が削減されます。
- 再現性: GenAIOps は、コード、データ、モデル、構成の記録を維持し、成功した実験の実行をオンデマンドで再現できるようにします。これは、再現性がもはや機能ではなく、ビジネスを行うための厳しい要件である規制された業界にとって特に重要になります。
生成 AI の変革の可能性
GenAIOps を組織構造に組み込むことは、単なる技術的なアップグレードではありません。これは、顧客と企業全体のエンドユーザーの両方に長期的なプラスの効果をもたらす戦略的な動きです。
- ユーザー エクスペリエンスの向上: GenAIOps は、本番環境で AI アプリの最適なパフォーマンスを提供します。企業は、強化されたユーザー エクスペリエンスを提供できます。チャットボット、自律エージェント、コンテンツ ジェネレーター、データ分析ツールなどを使用します。
- 新たな収益源の開拓: GenAIOps によって促進される生成 AI のカスタマイズされたアプリケーションにより、企業はこれまで未知の領域に挑戦し、新たな収益源を開拓し、提供内容を多様化することができます。
- 倫理基準の主導: ブランド イメージが倫理的考慮事項と密接に結びついている世界では、GenAIOps に導かれて AI の潜在的な落とし穴に積極的に対処する企業が業界リーダーとして台頭し、他社が追従するベンチマークを設定する可能性があります。
AI の世界はダイナミックで急速に進化しており、可能性に満ちています。テキスト、画像、分子、音楽を理解して生成する比類のない機能を備えた基盤モデルは、この革命の最前線にあります。
MLOps から GenAIOps、LLMOps、RAGOps まで AI 運用の進化を検討する場合、企業は柔軟に対応し、運用の精度を向上させ、精度を優先する必要があります。GenAIOps を包括的に理解し、戦略的に適用することで、組織は生成 AI 革命の軌道を形作る準備が整います。
どうやって始めるのか
NVIDIA AI Foundation Models を使って、最適化された NVIDIA アクセラレーテッド ハードウェア/ソフトウェア スタック上で動作する最先端の生成 AI モデルをブラウザからお試しください。NVIDIA NeMo で LLM 開発を始めましょう。これは、どこにでも生成 AI モデルを構築、カスタマイズ、展開するためのエンドツーエンドのクラウドネイティブ フレームワークです。
または、学習の旅を始めるには、NVIDIA トレーニングが最適です。講師によるワークショップと自分のペースで学べるオンライン コースは、NVIDIA ソリューションの可能性を最大限に引き出すために必要な知識と実践経験を学習者に提供します。
生成 AI と LLM については、生成 AI および LLM にフォーカスした学習パスをチェックしてください。
関連情報
- GTC セッション: Taming LLMs with the Latest Customization Techniques (Spring 2023)
- GTC セッション: Leveraging Large Language Models for Generating Content (Spring 2023)
- GTC セッション: Training and Productionizing LLMs with PyTorch on AWS (Presented by Amazon Web Services) (Spring 2023)
- NGC Containers: genai-llm-playground
- SDK: NeMo Guardrails
- ウェビナー: Implementing Large Language Models
翻訳に関する免責事項
この記事は、「Mastering LLM Techniques: LLMOps」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。