
大規模言語モデル (LLM) は、企業が業務、顧客とのやり取り、意思決定プロセスを改善するために不可欠なツールになりつつあります。しかし、既製の LLM では、業界固有の用語や専門知識、または独自の要件が原因となって、企業の個別のニーズを満たすことができないことがよくあります。
ここで役立つのが、カスタム LLM です。
企業には、言語処理機能を自社特有のユースケースや専門知識に合わせてカスタマイズするためのカスタム モデルが必要です。企業はカスタム LLM により、業界内や組織の事情に合わせてテキストをより効率的かつ正確に生成、理解できるようになります。
カスタム モデルがあれば、自社の個性に合うパーソナライズされたソリューションの開発、ワークフローの最適化、インサイトの正確性向上、およびユーザー エクスペリエンスの強化が可能になり、最終的に市場での競争力を高めることができます。
本記事では、さまざまなモデルのカスタマイズ手法と、その手法をいつ使用するかについて説明します。NVIDIA NeMo は多くのメソッドをサポートしています。
NVIDIA NeMo は、どこにでも生成 AI モデルを構築、カスタマイズ、展開できるエンドツーエンドのクラウドネイティブ フレームワークです。トレーニングおよび推論フレームワーク、ガードレール ツールキット、データ キュレーション ツール、事前トレーニング済みモデルなどが用意されており、生成 AI を簡単かつコスト効率よく迅速に導入する方法を提供します。
LLM のカスタマイズ手法を選択する
カスタマイズ中のトレーニング作業のレベルは下流のタスクで求められる精度と比較して決定されますが、カスタマイズ手法はそのレベルとデータセットのサイズ要件のトレードオフによって分類することができます。
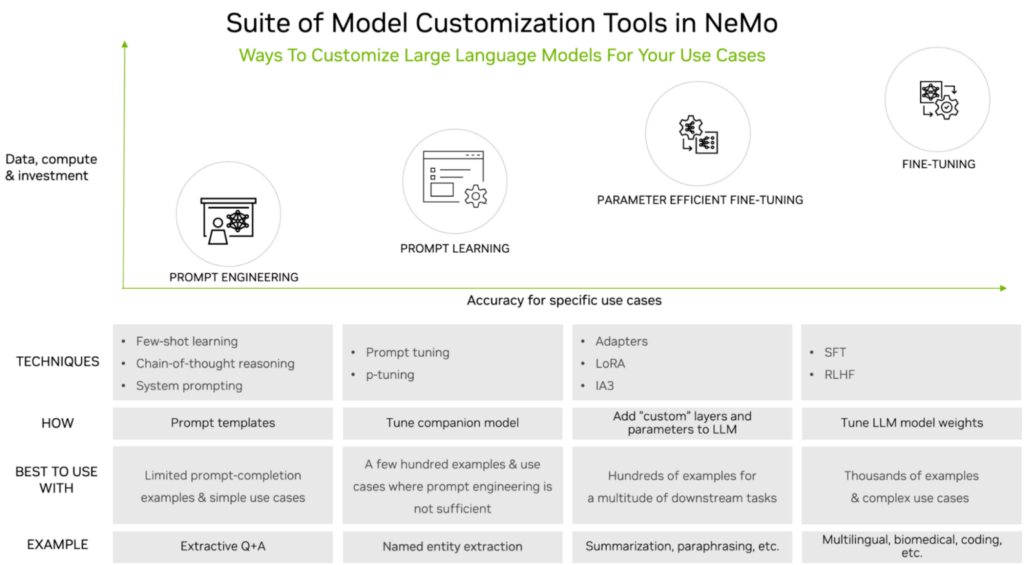
図 1 は、次の一般的なカスタマイズ手法を示しています。
- プロンプト エンジニアリング: LLM に送信されるプロンプトを操作しますが、LLM のパラメーターは一切変更しません。データとコンピューティング要件は軽量です。
- プロンプト ラーニング: プロンプトと補完 (completion) のペアを使用して、仮想トークンを通じてタスク固有の知識を LLM に伝えます。このプロセスはプロンプト エンジニアリングと比べると多くのデータとコンピューティングが必要ですが、高い精度が得られます。
- Parameter-Efficient Fine-Tuning (PEFT): 既存の LLM アーキテクチャに少数のパラメーターまたはレイヤーを導入し、ユースケース固有のデータでトレーニングします。プロンプト エンジニアリングやプロンプト ラーニングよりも精度が高いですが、その分トレーニング データとコンピューティングを多く必要とします。
- ファインチューニング: 前述の 3 種類のカスタマイズ手法は重みを固定したままにしますが、ファインチューニングは事前トレーニング済みの LLM の重みを更新できます。つまり、ファインチューニングは他の 3 手法と比較して、必要となるトレーニング データ量とコンピューティングが最も多くなりますが、特定のユース ケースに対する精度が最も高く、コストや複雑さが高くても納得できる手法です。
詳細については、「An Introduction to Large Language Models: Prompt Engineering and P-Tuning」を参照してください。
プロンプト エンジニアリング
プロンプト エンジニアリングは、推論時間のカスタマイズで「Show and Tell」の例を使用します。LLM には、プロンプトと補完の例が提供されます。補完とは、目的の補完を生成するために新しいプロンプトの前に追加される詳細な指示のことです。プロンプト エンジニアリングではモデルのパラメーターは変更されません。
Few-Shot プロンプト: このアプローチでは、LLM がこれまでにない新しいプロンプトに対する応答を生成する方法を学習できるように、プロンプトと補完のサンプルのペアをいくつか、プロンプトの前に追加する必要があります。Few-Shot プロンプトでは、他のカスタマイズ手法に比べて必要なデータ量が比較的少なく、ファインチューニングも必要ありませんが、その分推論が遅くなります。
思考連鎖推論: 人間が大きな問題を小さな問題に分解し、思考連鎖を適用して問題を効果的に解決するのと同じ要領で、思考連鎖推論は、LLM が複数ステップのタスクでパフォーマンスを向上できるようにするプロンプト エンジニアリング手法です。思考連鎖推論では問題をより単純なステップに分割し、各ステップではゆっくりと慎重な推論が必要になります。このアプローチは、論理的、算術的、演繹的推論のタスクに適しています。
システム プロンプト: このアプローチでは、ユーザー プロンプトにシステム レベルのプロンプトが加わり、LLM が意図したとおりに動作するように具体的かつ詳細な指示が出されます。システム プロンプトは、応答を生成するための LLM への入力と考えることができます。システム プロンプトの品質と専門性の高さは、LLM の応答の目的適合性や正確性に大きな影響を与える可能性があります。
プロンプト ラーニング
プロンプト ラーニングは、事前トレーニングされたモデルのパラメータ一式をチューニングする必要なく、多くの下流タスクで事前トレーニング済みの LLM が使用できる効率的なカスタマイズ方法です。プロンプト ラーニングには、P チューニングとプロンプト チューニングと呼ばれる 2 つのバリエーションがあり、微妙な違いがあります。これら 2 つの方法を総称してプロンプト ラーニングと呼びます。
プロンプト ラーニングにより、すでに事前トレーニング済みの以前のタスクをモデルが上書きしたり中断したりすることなく、新しいタスクを LLM に追加できます。元のモデルのパラメーターは凍結され、決して変更されないため、プロンプト ラーニングではモデルのファインチューニング時によく発生する「壊滅的忘却」の問題も回避されます。壊滅的忘却は、LLM がファインチューニングのプロセスにおいて新しい動作を学習するために事前トレーニング中に得られた基礎的な知識を代償として忘れてしまうことで発生します。
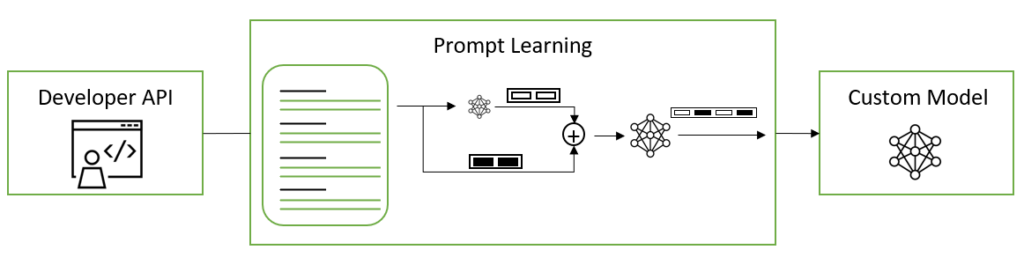
離散的なテキスト プロンプトを手動または自動で選択する代わりに、プロンプト チューニングと P チューニングでは仮想プロンプト埋め込みを使用し、勾配降下法によって最適化できます。この「仮想トークン」の埋め込みは、モデルの語彙を構成する離散トークン、ハード トークン、またはリアル トークンとは対照的な存在です。仮想トークンは、リアル トークンの各埋め込みの次元と等しい次元を持つ純粋な 1D ベクトルです。トレーニングや推論では、モデルの設定で提供されるテンプレートに従って、連続したトークンの埋め込みが離散トークンの埋め込みの間に挿入されます。
プロンプト チューニング: 事前トレーニング済み LLM の場合、ソフト プロンプトの埋め込みはサイズ (total_virtual_tokens, hidden_size) の 2D 行列として初期化されます。モデルが実行するようにプロンプト チューニングされる各タスクには、関連する独自の 2D 埋め込み行列があります。タスクは、トレーニング中や推論中にパラメーターを共有しません。NeMo フレームワークのプロンプト チューニングは、論文「The Power of Scale for Parameter-Efficient Prompt Tuning」に基づいて実装しています。
P チューニング: 仮想トークンの埋め込みを予測するために、prompt_encoder と呼ばれる LSTM または MLP のモデルが使用されます。prompt_encoder パラメーターは、P チューニングの開始時にランダムに初期化されます。すべての基本 LLM パラメータは凍結され、各トレーニング ステップで prompt_encoder の重みのみが更新されます。P チューニングが完了すると、prompt_encoder からのプロンプト チューニングされた仮想トークンが、すべてのプロンプト チューニングおよび P チューニングされたソフト プロンプトが保存される prompt_table に自動的に移動されます。prompt_encoder はその後、モデルから削除されます。これにより、将来的に新しい P チューニングまたはプロンプト チューニングされたソフト プロンプトを追加する機能は維持しつつ、以前に P チューニングされたソフト プロンプトを保存できます。
prompt_table は、タスク名をキーとして使用して、指定されたタスクの正しい仮想トークンを検索します。NeMo フレームワークの P チューニングは、論文「GPT Understands, Too」に基づいて実装しています。
Parameter-Efficient Fine-Tuning
Parameter-Efficient Fine-Tuning (PEFT) 手法は、巧みな最適化を使用して、元の LLM アーキテクチャに少数のパラメーターまたはレイヤーを選択的に追加および更新します。PEFT を使用すると、モデル パラメーターが特定のユースケースに合わせてトレーニングされます。事前トレーニングされた LLM の重みは固定されたままであるため、専門知識やタスクに固有のデータセットを使用する PEFT 中に更新されるパラメーターが大幅に少なくなります。これにより、LLM はトレーニング済みのタスクで高い精度を達成できるようになります。
事前トレーニング済み言語モデルをファインチューニングするための、パラメーター効率の高い代替手段としてはいくつか一般的なものがあります。プロンプト ラーニングとは異なり、これらの方法では仮想プロンプトが入力に挿入されません。代わりに、タスクに固有の学習のために、トレーニング可能な層をトランスフォーマー アーキテクチャに導入します。これにより、ファインチューニングと比較してトレーニング可能なパラメーター数を数桁レベル削減 (パラメーター数を 10,000 分の 1 近く削減) しながら、下流のタスクで強力なパフォーマンスを達成することができます。
- アダプター学習
- Infused Adapter by Inhibiting and Amplifying Inner Activations (IA3)
- 低ランク適応 (LoRA)
アダプター学習: コア トランス アーキテクチャの層の間に小さなフィードフォワード層を導入します。特定の下流タスクをファインチューニングする際には、これらの層 (アダプター) のみがトレーニングされます。アダプター層は通常、下方射影を使用して入力 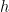 を低次元空間に射影させ、その後に非線形活性化関数を使用し、
を低次元空間に射影させ、その後に非線形活性化関数を使用し、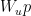 による上方射影を使用します。余り部分を結合させてこの出力を入力に追加し、最終的な形式になります。
による上方射影を使用します。余り部分を結合させてこの出力を入力に追加し、最終的な形式になります。
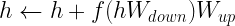
アダプター モジュールは通常、モジュールを追加したことで元のモデルのパフォーマンスが低下しないように、アダプターの初期出力が常に 0 になるように初期化されます。NeMo フレームワーク アダプターは、論文「Parameter-Efficient Transfer Learning for NLP」に基づいて実装しています。
IA3: 学習済みのベクトルを使用してトランスフォーマー層内の隠れた表現を単純にスケーリングするアダプター学習と比較して、追加するパラメーターがさらに少なく済みます。これらのスケーリング パラメーターを特定の下流タスク用にトレーニングできます。学習済みのベクトル lk、lv、lff はそれぞれ、アテンション メカニズムのキーと値、および Position-wise Feed-Forward ネットワークの内部アクティベーションを再スケーリングします。この手法により、混合タスク バッチも可能になります。バッチ内のアクティブ化の各シーケンスを、関連する学習済みタスク ベクトルで個別に低コストで増加できるためです。NeMo フレームワーク IA3 は、論文「Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning」に基づいて実装しています。
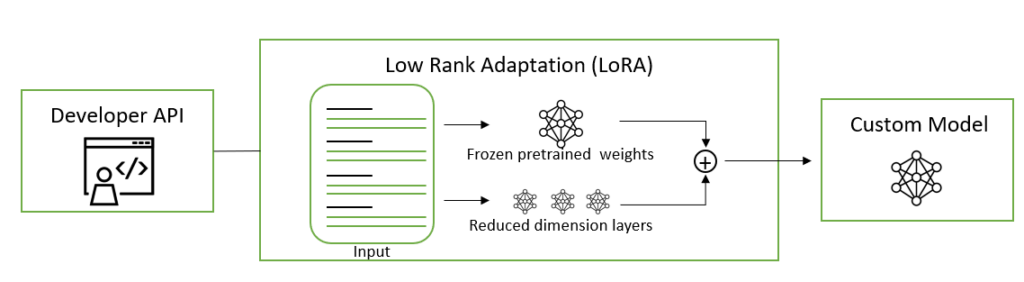
LoRA: トレーニング可能な低ランク行列をトランスフォーマー層に注入して、重みの更新の近似値を求めます。LoRA は、事前トレーニングされた重み行列 W を完全に更新する代わりに、その低ランク分解を更新し、ファインチューニングと比較してトレーニング可能なパラメータの数を 10,000 分の 1 に減らすことができ、GPU メモリ要件が 3 分の 1 に削減されます。この更新は、マルチヘッド アテンションのサブレイヤーのクエリおよび値射影重み行列に適用されます。行列全体ではなく低ランク分解に更新を適用すると、モデルの品質がファインチューニングと同等かそれ以上になることが証明されており、推論レイテンシを追加で発生させることなく、トレーニングのスループットを向上させることができます。
NeMo フレームワーク LoRA は、論文「Low-Rank Adaptation of Large Language Models」に基づいて実装しています。LoRA モデルを抽出 QA タスクに適用する方法の詳細については、LoRA チュートリアルのノートブックを参照してください。
ファインチューニング
データやコンピューティングのリソースに厳しい制約がない場合、教師ありファインチューニング (SFT) や人間のフィードバックによる強化学習 (RLHF) などのカスタマイズ手法は、PEFT およびプロンプト エンジニアリングに代わる優れたアプローチです。ファインチューニングは、他のカスタマイズ手法と比較して、さまざまなユースケースで最高の精度を達成することができます。
教師ありファインチューニング: SFT は、入力と出力のラベル付きデータを使用してモデルのすべてのパラメータをファインチューニングするプロセスで、分野固有の用語とユーザー指定の指示に従う方法をモデルに教えます。これは通常、モデルの事前トレーニング後に行われます。事前トレーニング済みのモデルを使用すると、最初からトレーニングする必要がない最先端のモデルを使用できる、コンピューティング コストを削減できる、データ収集の必要性が減少するなど、事前トレーニング段階と比較して多くの利点が得られます。SFT の形式は、命令を通じて記述されたデータセット収集に対する言語モデルのファインチューニングを伴うため、命令チューニングと呼ばれます。
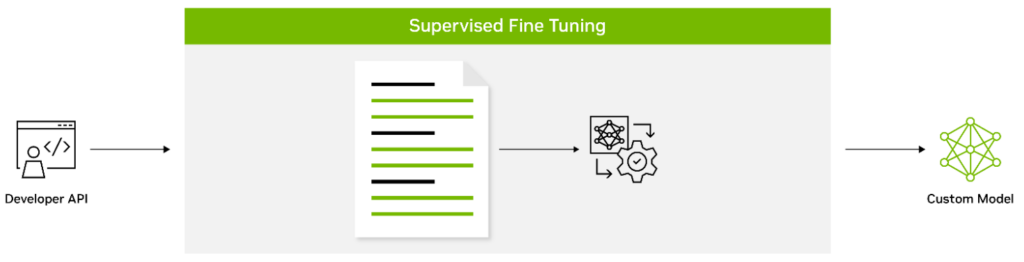
命令付き SFT は直感を活用します。直感は、「次の記事を 3 文で要約してください」や、「次の学園祭についてスペイン語でメールを書いてください」といった自然言語命令を通じて NLP タスクを記述できます。この方法は、ファインチューニングのパラダイムとプロンプトのパラダイムの長所をうまく組み合わせて、推論時の LLM ゼロショットのパフォーマンスを向上させます。
命令チューニング プロセスには、さまざまな割合でブレンドされた自然言語命令によって表現された複数の NLP データセットの混合物で、事前トレーニング済みのモデルに対するファインチューニングの実行が関連しています。推論時に、ファインチューニングされたモデルがこれまでにない新しいタスクで評価されます。そのためこのプロセスにより、これまでにない新しいタスクでのゼロショット パフォーマンスが大幅に向上することが知られています。SFT は、強化学習を使用して LLM 機能を向上させるプロセスにおける重要な中間ステップでもあります。強化学習については、次に説明します。
人間のフィードバックによる強化学習: 人間のフィードバックによる強化学習 (RLHF) は、LLM が人間の価値観や好みとの一致をさらに向上させることを可能にするカスタマイズ手法です。強化学習を使用して、モデルが受け取ったフィードバックに基づいて動作を適応できるようにします。これには、人間の好みを損失関数として使用する 3 段階のファインチューニング プロセスが含まれます。前のセクションで説明したように命令を使用してファインチューニングされた SFT モデルは、RLHF 手法の最初のステージと考えられます。
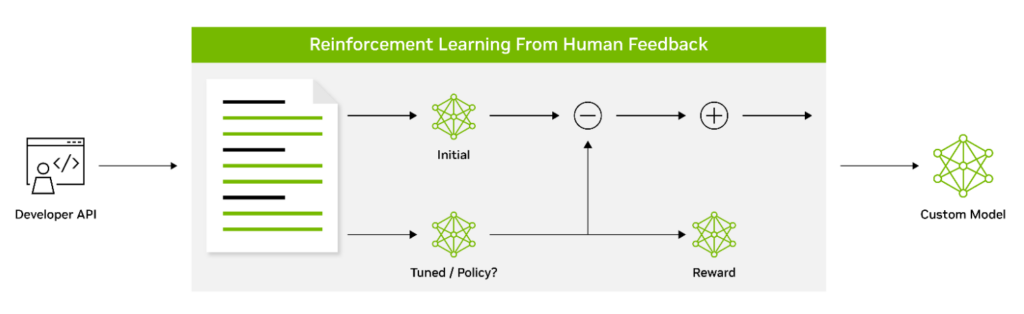
SFT モデルは、RLHF の 2 番目のステージで報酬モデル (RM) としてトレーニングされます。人間によってランク付けされた複数の応答を含むプロンプトで構成されるデータセットは、人間の好みを予測するように RM をトレーニングするために使用されます。
RM がトレーニングされた後、RLHF の 3 番目のステージでは、近接ポリシー最適化 (PPO) アルゴリズムによる強化学習を使用して、RM に対して初期ポリシー モデルをファインチューニングすることに焦点を当てます。RLHF のこれら 3 つのステージを繰り返し実行することで、LLM は人間の好みに合わせた出力を生成し、より効果的に指示に従うことができるようになります。
RLHF は強力な LLM を生成しますが、マイナス面は、この方法が誤用されたり、望ましくないコンテンツや有害なコンテンツを生成するために悪用されたりする可能性があることです。NeMo のメソッドは、LLM が有害なコンテンツを生成しないように導くための批判的モデルとして PPO 価値ネットワークを使用します。研究コミュニティでは、LLM を適切な行動に導き、LLM が事実をでっち上げた場合の有害コンテンツの生成やハルシネーションを減らす他のアプローチの採用が積極的に検討されています。
LLM をカスタマイズしましょう
本記事では、さまざまなモデルのカスタマイズ手法と、その手法をいつ使用するかについて説明しました。NVIDIA NeMo では、これらのメソッドの多くをサポートしています。
NeMo により、3D 並列処理技術を使用したトレーニングのワークフローが高速化します。カスタマイズ手法の選択肢が複数提供され、マルチ GPU およびマルチノード構成により、言語アプリケーションや画像アプリケーションの大規模モデルを大規模に推論できるように最適化されています。
今すぐ NeMo フレームワークをダウンロードし、オンプレミスやクラウドの希望のプラットフォームで事前トレーニングされた LLM をカスタマイズしましょう。