
大規模言語モデル (LLM) は、非常に大規模なデータセットを使用して言語を認識、要約、翻訳、予測、生成できる Transformer ネットワークを使用して構築された生成 AI モデルのクラスです。ご存知の通り、LLM は社会を変革する可能性を秘めていますが、このような基盤モデルのトレーニングは非常に困難です。
このブログでは、Transformer ネットワークを使用して構築された LLM の背後にある基本原則を、モデル アーキテクチャ、アテンション メカニズム、埋め込み手法、基盤モデルのトレーニング戦略にわたり説明します。
モデル アーキテクチャ
モデル アーキテクチャは Transformer ネットワークのバックボーンを定義し、モデルの能力や制限を広く決定づけます。 LLM のアーキテクチャは、しばしば、エンコーダー、デコーダー、またはエンコーダー/デコーダー モデルと呼ばれます
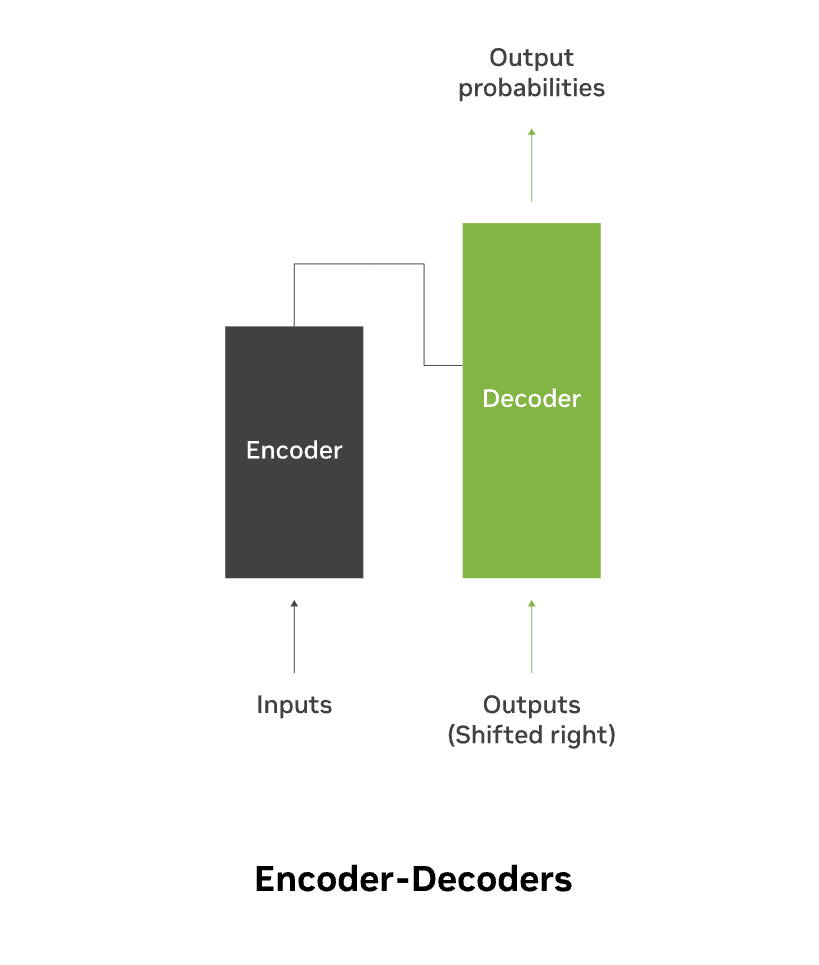
一般的なアーキテクチャには次のようなものがあります。
| アーキテクチャ | 説明 | 適した用途 |
| Bi-directional Encoder Representation from Transformers (BERT) | エンコーダーのみのアーキテクチャ。言語を理解するタスクに最適です。 | 分類と感情分析 |
| Generative Pre-trained Transformer (GPT) | デコーダーのみのアーキテクチャは生成タスクに適しており、識別タスクではラベル付きデータでファインチューニングを行います。 単方向アーキテクチャの前提として、コンテキストは前方にのみ流れます。GPT フレームワークは、生成的な事前トレーニングと識別的なファインチューニングを通じて、単一タスクに依存しないモデルを使用して強力な自然言語理解を実現するのに役立ちます。 | テキストの含意、文の類似性、質問への回答。 |
| Text-to-Text Transformer (Sequence-to-Sequence モデル) | エンコーダー/デコーダー アーキテクチャ。転移学習アプローチを利用して、テキストベースの言語の問題をすべてテキスト対テキスト形式に変換します。つまり、テキストを入力として受け取り、次のテキストを出力として生成します。双方向アーキテクチャでは、コンテキストは両方向に流れます。 | 翻訳、質疑応答、要約。 |
| Mixture of Experts (MoE) | どのアーキテクチャにも適用できるモデル アーキテクチャの決定。最小限の計算オーバーヘッドを追加しながらモデルの容量を大幅にスケールアップし、密なモデルを疎なモデルに変換するように設計されています。MoE 層は、多くのエキスパート モデルとスパース ゲート関数で構成されます。ゲートは、推論中に各入力を上位 K (K>=2 または K=1) の最良のエキスパートにルーティングします。 | 低レイテンシで推論中の計算効率を高めるためにタスク全体を適切に一般化します。 |
もう 1 つの一般的なアーキテクチャ上の決定は、テキスト、画像、オーディオ、ビデオなどの複数のモダリティまたはデータ形式からの情報を組み合わせるマルチモーダル モデルに拡張することです。トレーニングは困難ですが、マルチモーダル モデルは、人間が複数の感覚からのデータを分析することで理解するのと同じように、さまざまなモダリティからの情報を補完するという重要な利点をもたらします。
これらのモデルには、画像向けの CNN やテキスト向けの Transformer などのモダリティごとに個別のエンコーダーが含まれており、それぞれの入力データから高レベルの特徴表現を抽出します。複数のモダリティから抽出された特徴を組み合わせるのは困難な場合があります。これは、各モダリティから抽出された特徴を融合したり、アテンション メカニズムを使用してタスクに対する各モダリティの寄与を重み付けすることによって対処できます。
この共同表現はモダリティ間の相互作用を捉えます。モデル アーキテクチャには、分類、キャプション生成、翻訳、プロンプト テキストからの画像生成、プロンプト テキストからの画像編集などのタスク固有の出力を生成するための追加のデコーダーが含まれる場合があります。
Transformer ネットワークの詳細
Transformer ネットワークの領域では、トークン化のプロセスは、テキストをトークンと呼ばれる小さな単位に断片化する上で極めて重要な役割を果たします。
トークナイザー
トークン化は、モデルを構築するための最初のステップです。これは、テキストを LLM の基本構成要素となるトークンと呼ばれる小さな単位に分割します。これらの抽出されたトークンは、トークンを数値 ID にマッピングする語彙インデックスを構築するために使用され、ディープラーニングの計算に適した数値でテキストを表現します。エンコード プロセス中に、これらの数値トークンは各トークンの意味を表すベクトルにエンコードされます。デコード プロセス中に、LLM が生成を行う際に、トークナイザーが数値ベクトルを読み取り可能なテキスト シーケンスにデコードします。
このプロセスは、小文字を処理したり、句読点と空白の削除、ステミング、見出し語化、短縮形の処理、およびアクセントの削除といった正規化からはじまります。テキストがクリーンアップされたら、次のステップは単語と文の境界を認識してテキストをセグメント化することです。境界に応じて、トークナイザーは単語、サブワード、または文字レベルの粒度になります。
単語および文字ベースのトークナイザーが普及していますが、これらには課題があります。単語ベースのトークナイザーでは語彙サイズが大きくなり、トークナイザーのトレーニング プロセス中に表示されなかった単語により多くの語彙外トークンが発生します。文字ベースのトークナイザーでは、シーケンスが長くなり、個々のトークンの意味が薄れます。
これらの欠点のため、サブワードベースのトークナイザーが人気を集めています。サブワード トークン化アルゴリズムの焦点は、一般的な文字の n-gram とパターンに基づいて、まれな単語をより小さく意味のあるサブワードに分割することです。この技術により、既知のサブワードを介して珍しい単語や見たことのない単語を表現できるため、語彙サイズが削減されます。また、推論中には、語彙外の単語を処理して語彙サイズを効果的に削減しながら、推論中に語彙外の単語を適切に処理します。
一般的なサブワード トークン化アルゴリズムには、バイト ペア エンコーディング (BPE)、WordPiece、Unigram、SentencePiece などがあります。
- BPE は文字語彙から開始し、頻繁に隣接する文字のペアを新しい語彙用語に繰り返しマージし、最も一般的な単語を単一のトークンに置き換えることにより、デコード時の推論を高速化してテキスト圧縮を実現します。
- WordPiece はマージ操作を実行する点で BPE と似ていますが、これは言語の確率的な性質を利用して文字をマージし、トレーニング データの尤度を最大化します。
- Unigram は大きな語彙から開始し、トークンの確率を計算し、目的の語彙サイズに達するまで損失関数に基づいてトークンを削除します。
- SentencePiece は、言語モデリングの目標に基づいて生のテキストからサブワード単位を学習し、Unigram または BPE トークン化アルゴリズムを使用して語彙を構築します。
アテンション メカニズム
リカレント ニューラル ネットワーク (RNN) のような従来の seq-2-seq エンコーダー/デコーダー言語モデルは入力シーケンスの長さに応じてうまくスケールしませんでしたが、アテンションの概念が導入され、これが重要であることが証明されています。アテンション メカニズムにより、デコーダーは、エンコードされた入力シーケンスによって重み付けされた入力シーケンスの最も関連性の高い部分を使用でき、最も関連性の高いトークンには最も高い重みが割り当てられます。この概念は、重要度に応じてトークンを慎重に選択することにより、入力シーケンスの長さのスケーリングを改善します。
このアイデアはセルフアテンションに進化し、2017 年に Transformer モデル アーキテクチャとともに導入され、RNN の必要性がなくなりました。セルフアテンション メカニズムは、同じシーケンス内の異なる単語間の関係に基づいて入力シーケンスの表現を作成します。入力コンテキストを含めることで入力埋め込みの情報コンテンツを強化することにより、セルフアテンション メカニズムは Transformer アーキテクチャにおいて重要な役割を果たします。
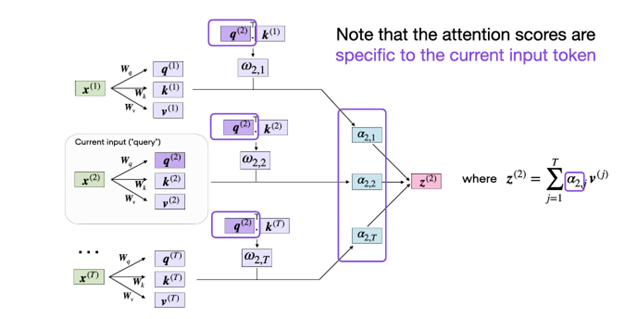
セルフアテンションは、コンテキストを意識した入力表現を実現する方法から、スケールドドット プロダクト アテンションと呼ばれます。入力シーケンス内の各トークンは、それぞれの重み行列を使用して、それ自体をクエリ (Q)、キー (K)、および値 (V) シーケンスに射影するために使用されます。目的は、他のすべての入力トークンをコンテキストとして与え、各入力トークンのアテンションを重み付けしたバージョンを計算することです。V 行列によって決定される関連ペアがより高い重みを持つようにQ 行列と K 行列の Scaled Dot-Product を計算することにより、セルフアテンション メカニズムは、シーケンス内の他のトークンであるすべてのキーと値のペアを考慮した、各入力トークン (Q) に適したベクトルを見つけます。
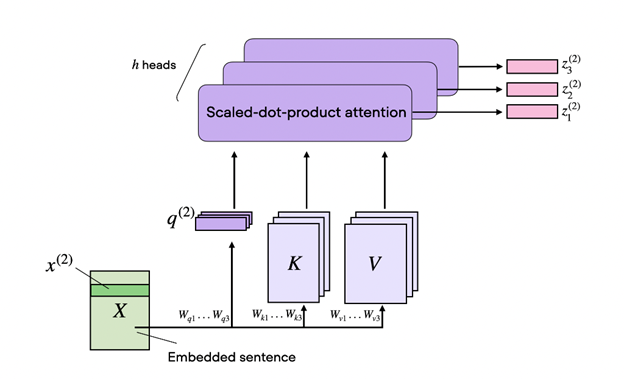
セルフアテンションはさらにマルチヘッド アテンションへと進化しました。前述の 3 つの行列 (Q、K、V) は単一ヘッドと考えることができます。マルチヘッド セルフアテンションは、そのようなヘッドを複数使用することです。これらのヘッドは CNN の複数のカーネルのように機能し、シーケンスのさまざまな部分に注目し、短期的な依存関係よりも長期的な依存関係に焦点を当てます。
そして最後に、クロスアテンションの概念が生まれました。セルフアテンションの場合のように単一の入力シーケンスの代わりに、これには 2 つの異なる入力シーケンスを含みます。Transformer モデル アーキテクチャでは、これはエンコーダーからの 1 つの入力シーケンスと、デコーダーによって処理されるもう 1 つのシーケンスとなります。
FlashAttention
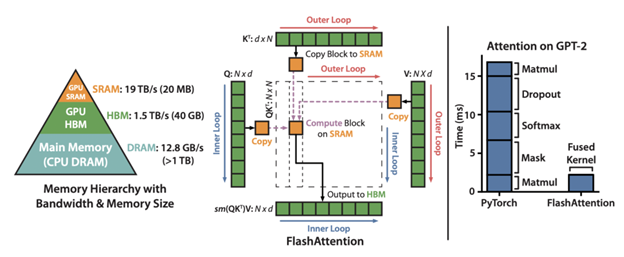
より大きなサイズの Transformer は、シーケンスが長くなるにつれて増加するアテンション層のメモリ要件によって制限されます。この増加はシーケンス長の二乗に比例します。アテンション層の計算を高速化し、メモリ フットプリントを削減するために、FlashAttention は、低速な GPU の高帯域幅メモリ (HBM) からの繰り返しの読み書き込みによるボトルネックが発生する、未熟な実装を最適化します。
FlashAttention は、古典的なタイリングを使用して、クエリ、キー、および値のブロックを GPU の HBM (メイン メモリ) から SRAM (高速キャッシュ) にロードしてアテンションの計算を行い、出力を HBM に書き戻します。また、順方向パスからの大きなアテンション行列を保存しないことにより、メモリ使用量も改善されます。代わりに、SRAM でのバックプロップ中にアテンション行列を再計算することに依存します。これらの最適化により、FlashAttention は長いシーケンスの速度を大幅に向上 (2 ~ 4 倍) します。
さらに改良された FlashAttention-2 は、シーケンス並列化による最適化を追加し、作業の分割を改善し、行列積ではない FLOPs を削減することにより、FlashAttention よりも 2 倍高速になっています。この新しいバージョンでは、グループ化されたクエリ アテンションだけでなく、次に説明するマルチクエリ アテンションもサポートしています。
マルチクエリ アテンション (MQA)
複数のクエリのヘッドが同じキーと値の射影のヘッドに注目するアテンションの一種です。これにより、KV キャッシュ サイズが削減され、インクリメンタル デコーディングのメモリ帯域幅要件が削減されます。結果として得られるモデルは、ベースラインのマルチヘッド アテンション アーキテクチャよりもわずかな品質劣化を伴いますが、推論において高速な自己回帰デコードをサポートします。
グループ クエリ アテンション (GQA)
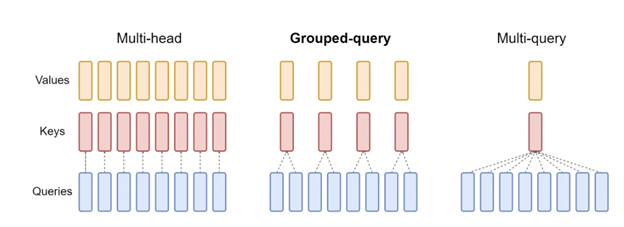
グループ クエリ アテンション (GQA) は、推論時の高速化を維持しながら品質低下の問題を克服するために MQA を改良したものです。さらに、マルチヘッド アテンションを使用してトレーニングされたモデルは、最初から再トレーニングする必要がありません。元のトレーニング コンピューティングのわずか 5% を使用して既存のモデル チェックポイントをアップトレーニングすることで、推論中に GQA を採用できます。また、これは、中間の (1 つ以上クエリ ヘッド数以下の) 数のキー/値ヘッドを使用した MQA の一般化です。GQA は、MQA と同等の速度で、ベースラインのマルチヘッド アテンションに近い品質を実現します。
埋め込み技術
文の中で単語が現れる順序は重要です。この情報は、各入力トークンの出現順序を 2D 位置エンコード行列に割り当てることにより、位置エンコードを使用して LLM にエンコードされます。行列の各行は、シーケンスのエンコードされたトークンにその位置情報を加算したものを表します。これにより、モデルは意味が似ているが文内で位置が異なる単語を区別できるようになり、単語の相対位置をエンコードできるようになります。
オリジナルの Transformer アーキテクチャは、絶対位置エンコーディングと正弦関数を使用した単語埋め込みを組み合わせています。しかしながら、このアプローチでは、トレーニング中に見られたシーケンスよりも長いシーケンスを推論時に外挿することはできません。相対位置エンコーディングはこの課題を解決しました。ここでは、クエリとキー ベクトルのコンテンツ表現が、クエリと特定の距離を超えてクリップされたキーの間の距離に関連してトレーニング可能な位置表現と結合されます。
RoPE
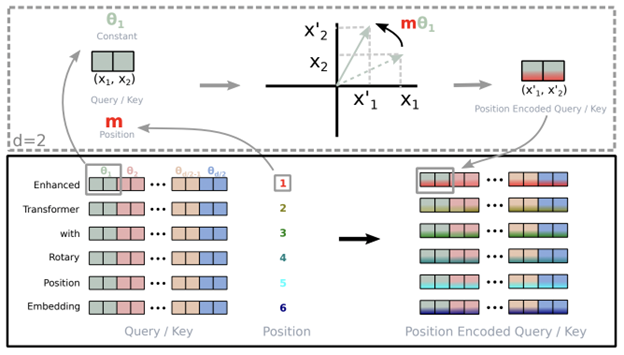
Rotary Position Embeddings (RoPE) は、絶対位置埋め込みと相対位置埋め込みの概念を組み合わせたものです。絶対位置は回転行列を使用してエンコードされます。相対位置依存性はセルフアテンションの定式化に組み込まれ、乗算的に文脈表現に追加されます。この手法は、相対位置エンコーディングを備えた線形セルフアテンションを備えながら、Transformer の正弦波位置埋め込みに導入されたシーケンス長の柔軟性の利点を維持します。また、相対距離の増加に伴って減衰するトークン間の依存関係が導入され、推論時により長いシーケンスへの外挿が可能になります。
AliBi
Transformer ベースの LLM は、セルフアテンションの 2 次コストにより、コンテキストのトークンの数が制限されるため、より長いシーケンスにはうまく拡張できません。さらに、元の Transformer アーキテクチャで導入された正弦波位置手法は、トレーニング中に確認されたものよりも長いシーケンスを外挿できません。これにより、LLM を適用できる実際のユース ケースが制限されます。これを克服するために、Attention with Linear Biases (ALiBi) が導入されました。この手法は、単語の埋め込みに位置の埋め込みを追加しません。代わりに、距離に比例するペナルティでクエリキー アテンション スコアにバイアスをかけます。
トレーニング時に見られたものよりもはるかに長いシーケンスの効率的な外挿を容易にするために、ALiBi は、関連するキーとクエリの間の距離に比例して線形に減少するペナルティを使用して、アテンション スコアに負のバイアスをかけます。正弦波モデルと比較して、この方法では追加のランタイムやパラメーターは必要なく、メモリの増加もごくわずか (0 ~ 0.7%) です。正弦波埋め込みに対する ALiBi の優位性は、初期のトークンの呪縛の回避が向上していることによって主に説明されます。この方法では、より長いコンテキスト履歴をより効率的に活用することで、さらなる利益を達成することもできます。
Transformer ネットワークのトレーニング
LLM をトレーニングする際、効率を向上させ、基礎となるハードウェア構成のリソース使用を最適化するための手法がいくつかあります。数十億のパラメーターと数兆のトークンを含むこれらの非常に大規模な AI モデルを拡張するには、膨大なメモリ容量が必要になります。
この要件を軽減するために、モデルの並列化やアクティベーションの再計算などのいくつかの方法が一般的です。モデルの並列化では、モデル パラメーターとオプティマイザーの状態が複数の GPU に分割され、各 GPU がモデル パラメーターのサブセットを保存します。さらに、テンソル並列化とパイプライン並列化に分類されます。
- テンソル並列化は、GPU 間で演算を分割します。これは、行列積などの演算内の計算の並列化に焦点を当てた層内並列化としてよく知られています。この手法では、結果が正しいことを確認するために追加の通信が必要になります。
- パイプライン並列化はモデルのレイヤーを GPU 間で分割し、レイヤー間並列処理とも呼ばれ、モデルをレイヤーごとにチャンクに分割することに重点を置いています。各デバイスはそのチャンクを計算し、中間アクティベーションを次のステージに渡します。これにより、一部のデバイスが計算に従事している間に他のデバイスが待機するバブルタイムが発生し、計算リソースの浪費につながる可能性があります。
- シーケンス並列化は、これまで並列化されておらず、シーケンス次元に沿って独立している Transformer 層の領域に注目することで、テンソル レベルのモデル並列化を拡張します。これらの層をシーケンス次元に沿って分割することで、テンソル並列デバイス全体にこれらの領域のコンピューティングとアクティベーション メモリを分散できるようになります。アクティベーションは分散され、メモリ フットプリントが小さいため、より多くのアクティベーションを逆方向パス用に保存できます。
- 選択的アクティベーションの再計算は、シーケンス並列化と連携して行われます。これは、アクティベーションが異なれば再計算に必要な操作数も異なることに注目し、メモリの制約によってアクティベーションのすべてではなく一部の再計算が強制されるケースを改善します。Transformer 層全体をチェックポイントして再計算する代わりに、各 Transformer 層のうち、多くのメモリを使用するが再計算に計算コストがかからない部分のみをチェックポイントして再計算することができます。
すべての手法で、通信または計算のオーバーヘッドが追加されます。したがって、効率的な LLM トレーニングには、最大のパフォーマンスを達成する構成を見つけて、データ並列化を使用してトレーニングをスケーリングすることが不可欠です。
データ並列トレーニングでは、データセットがいくつかのシャードに分割され、各シャードがデバイスに割り当てられます。これは、バッチ次元に沿ってトレーニング プロセスを並列化することに相当します。各デバイスはモデル レプリカの完全なコピーを保持し、割り当てられたデータセット シャードでトレーニングします。バックプロパゲーションの後、モデルの勾配は all-reduce されるため、さまざまなデバイス上のモデル パラメーターの同期が維持されます。
このバリエーションとして、完全シャード データ並列処理 (FSDP) 技術と呼ばれるものがあります。これは、モデル パラメーターとトレーニング データをデータ並列ワーカー間で均一にシャーディングします。データの各マイクロバッチの計算は各 GPU ワーカーに対してローカルに行われます。
FSDP は、ハードウェアの異種混合に対処するためにクラスターの物理的な相互接続トポロジに一致するようにカスタマイズできる構成可能なシャーディング戦略を提供します。演算の並べ替えとパラメーターのプリフェッチにより、通信と計算を積極的にオーバーラップさせ、バブルを最小限に抑えることができます。最後に、FSDP は、処理中の非シャード パラメーターに割り当てられるブロックの数を制限することで、メモリ使用量を最適化します。これらの最適化により、FSDP は、TFLOPS の点でほぼ線形のスケーラビリティを備えた大幅に大規模なモデルのサポートを提供します。
量子化認識トレーニング
量子化は、ディープラーニング モデルが完全な精度 (浮動小数点) 値と比較して低い精度で計算のすべてまたは一部を実行するプロセスです。この技術により、正確度の損失を最小限に抑えながら、推論の高速化、メモリの節約、ディープラーニング モデルの使用コストの削減が可能になります。
量子化認識トレーニング (QAT) は、トレーニング プロセス中に量子化の影響を考慮する方法です。モデルは、トレーニング中に量子化プロセスを模倣する量子化対応操作でトレーニングされます。モデルは量子化表現で適切に実行する方法を学習し、トレーニング後の量子化と比較して正確度が向上します。順方向パスでは、重みとアクティベーションが低精度表現に量子化されます。逆方向パスでは、完全精度の重みとアクティベーションを使用して勾配を計算します。これにより、モデルは、順方向パスで導入された量子化エラーに対して堅牢なパラメーターを学習できるようになります。その結果、正確度への影響を最小限に抑えながらトレーニング後に量子化できるトレーニング済みモデルが得られます。
今すぐ LLM をトレーニングしましょう
この投稿では、さまざまなモデル トレーニング手法と、それらをいつ使用するかについて説明しました。LLM ワークフローの学習を続けるには、大規模言語モデルのカスタマイズ手法を選択するの投稿もチェックしてみてください。
トレーニング方法の多くは NVIDIA NeMo でサポートされており、3D 並列化技術を使用したトレーニングのための加速されたワークフローを提供します。また、いくつかのカスタマイズ手法も提供されます。これはマルチ GPU およびマルチノード構成を使用した、言語および画像ワークロードの大規模モデルの大規模推論用に最適化されています。今すぐ NeMo フレームワークをダウンロードして、 お好みのオンプレミスおよびクラウド プラットフォームで LLM をトレーニングしましょう。
関連情報
- GTC セッション: Leveraging Large Language Models for Generating Content (Spring 2023)
- GTC セッション: Applications in AI to Assist Law Practitioners and In-House Legal Departments (Spring 2023)
- GTC セッション: Training and Productionizing LLMs with PyTorch on AWS (Presented by Amazon Web Services) (Spring 2023)
- NGC コンテナー: genai-llm-playground
- ウェビナー: Implementing Large Language Models
- ウェビナー: Harness the Power of Cloud-Ready AI Inference Solutions and Experience a Step-By-Step Demo of LLM Inference Deployment in the Cloud
翻訳に関する免責事項
この記事は、「Mastering LLM Techniques: Training」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。