
大規模言語モデル (LLM) スケーリング則における最新の開発では、モデル パラメーターの数をスケーリングする場合、トレーニングに使用されるトークンの数も同じ割合でスケーリングする必要があることが示されました。Chinchilla モデルや LLaMA モデルは、経験的に導き出されたこのスケーリング則を立証しており、これまで最先端と呼ばれてきたモデルの数々は、事前トレーニング中に使用されるトークンの総数に関してトレーニングが不十分だったことを示唆しています。
こうした最近の開発動向を考えると、LLM にはこれまで以上に大規模なデータセットが必要であることは明らかです。
しかし、必要性が明確であるにもかかわらず、LLM のトレーニングに使用する大規模なデータセットを作成するために開発されたソフトウェアやツールのほとんどは、一般に公開されておらず、拡張性もありません。したがって、LLM 開発者は大規模な言語データセットをキュレーションするための独自のツールを構築する必要があります。
この大規模なデータセットに対するニーズの高まりに応えるために、私たちは NeMo Data Curator を開発、リリースしました。NeMo Data Curator は、LLM の事前トレーニング用に 1 兆トークンの多言語データセットをキュレーションできるスケーラブルなデータキュレーション ツールです。
Data Curator は、Message-Passing Interface (MPI)、Dask、Redis Cluster を使用する Python モジュールのセットで、以下のようなタスクを数千のコンピューティング コアにスケーリングします。
- データ ダウンロード
- テキスト抽出
- テキストの再フォーマットとクリーニング
- 品質フィルタリング
- 完全重複排除、あいまい重複排除
これらのモジュールをデータセットに適用することで、非構造化データ ソースを調べる負担が軽減されます。ドキュメントレベルの重複排除により、モデルが一意のドキュメントでトレーニングされるようになるため、事前トレーニングのコストが大幅に削減される可能性があります。
本記事では Data Curator の各モジュールについて概説し、1000 を超える CPU コアに線形スケーリングを提供するデモを行います。データがキュレーションされていることを確認するために、Common Crawl から処理されるドキュメントを事前トレーニングに使用すると、ダウンロードされた生のドキュメントを使用する場合よりも下流のタスクが大幅に改善されることも実証します。
データキュレーション パイプライン
このツールによって、データをダウンロードしてドキュメントを大規模に抽出、クリーンアップ、重複排除、フィルタリングすることができます。図 1 は、実装可能な一般的な LLM データキュレーション パイプラインを示しています。この後のセクションで、利用可能なこれらの各モジュールの実装について簡単に説明します。

ダウンロードとテキスト抽出
多くの LLM プラクティショナー向けにカスタム事前トレーニング データセットを準備するにあたって、最初に用意するのは、LLM 事前トレーニングに関係のあるコンテンツを含むデータ ファイルまたは Web サイトへリンクする URL のリストです。
Data Curator を使用すると、Common Crawl、Wikidumps、ArXiv などのデータ リポジトリから事前にクロールされた Web ページをダウンロードし、関連するテキストを JSONL ファイルに大規模に抽出できます。また、Data Curator は独自のダウンロードおよび抽出機能を提供することで、さまざまなソースから取得したデータセットを処理できる柔軟性も備えています。MPI と Python Multiprocessing を組み合わせて使用すると、実行時に多数のコンピューティング ノードにわたって数千件の非同期ダウンロード ワーカーや抽出ワーカーを起動できます。
テキストの再フォーマットとクリーニング
ドキュメントからテキストをダウンロードして抽出する際、抽出中にテキスト データが適切にデコードされなかったときに Unicode 関連のエラーが発生し、このエラーをすべて修正する必要が出てくる場合がよくあります。Data Curator は、Fixes Text For You library (ftfy) を使用して Unicode 関連のエラーをすべて修正します。クリーニングはテキストの正規化にも役立ち、ドキュメントの重複排除を実行する際に再現率が高くなります。
ドキュメントレベルの重複排除
Common Crawl などの大規模な Web クロール ソースからデータをダウンロードする場合、完全に重複したドキュメントにも、類似性の高い (ほぼ重複した) ドキュメントにも遭遇するのが一般的です。繰り返しのドキュメントを使用して LLM を事前トレーニングすると、汎化が不十分になり、テキスト生成時に多様性が欠如する可能性があります。
NVIDIA では、テキスト データから重複を排除するための完全重複およびあいまい重複排除用ユーティリティを提供しています。完全重複排除ユーティリティは、各ドキュメントの 128 ビットのハッシュ値を計算し、ハッシュ値ごとにドキュメントをバケットにグループ化し、バケットごとに 1 つのドキュメントを選択して、バケット内の残りの完全重複を排除します。
あいまい重複排除ユーティリティは、MinHashLSH ベースのアプローチを使用します。このアプローチでは、ドキュメントごとに MinHash が計算され、min-wise ハッシュの局所性鋭敏型プロパティを使用してドキュメントがグループ化されます。ドキュメントがバケットにグループ化された後、各バケット内のドキュメント間の類似性が計算され、MinHashLSH 中に作成される誤検知の可能性がチェックされます。
どちらの重複排除ユーティリティでも、Data Curator はコンピューティング ノード全体に分散された Redis クラスターを使用して、ドキュメントをバケットにクラスタリングするための分散ディクショナリを実装します。Redis Cluster によって実装されたスケーラブルな設計とゴシップ プロトコルにより、重複排除ワークロードを多くのコンピューティング ノードに効率的にスケーリングできます。
ドキュメントレベルの品質フィルタリング
Common Crawl などの Web クロール ソースからのデータには、重複ドキュメントがかなりの割合を占めていることに加えて、非公式の文章を含むドキュメントが多数含まれる傾向があります。例えば、URL、記号、定型コンテンツ、省略記号、繰り返しのサブストリングなどが多数含まれます。これらは言語モデリングの観点からは低品質のコンテンツと考えられます。
LLM 事前トレーニング データセットが多様であれば下流のパフォーマンスが向上することが示されていますが、低品質のドキュメントが大量に含まれているとパフォーマンスを妨げる可能性があります。Data Curator は、コーパスにカスタム ヒューリスティック フィルターを大規模に適用できる、高度に設定可能なドキュメント フィルター ユーティリティを提供しています。このツールでは言語データ フィルター (分類子とヒューリスティック ベースの両方) の実装も可能で、このフィルターは Web クロール データに適用すると全体的なデータ品質と下流タスクのパフォーマンスを向上させることが実証されています。
多数のコンピューティング コアへのスケーリング
Data Curator 内で利用できるさまざまなモジュールのスケーリング機能を実証するために、私たちはモジュールを使用して約 400 億トークンで構成される小さなデータセットを準備しました。ここでは、前述のデータ キュレーション パイプラインを 5 TB の Common Crawl WARC ファイルで実行しています。
各パイプライン ステージでは、入力データセットのサイズを固定し、データ キュレーション モジュールのスケーリングに使用される CPU コアの数を直線的に増加させました (強力なスケーリング)。次に、各モジュールの速度向上を測定しました。品質フィルタリング モジュールとあいまい重複排除モジュールの速度向上の測定結果を図 2 に示します。
測定結果の傾向を調べると、データ キュレーション ワークロードの分散に使用される CPU コアの数を増加させるとモジュールの速度が大幅に向上する可能性があることがわかります。線形リファレンス (オレンジ色の曲線) と比較すると、最大 1,000 台またはそれ以上の CPU を使用する場合、どちらのモジュールも大幅な高速化を達成できていることがわかります。

事前トレーニング データのキュレーションによってモデルの下流パフォーマンスが向上
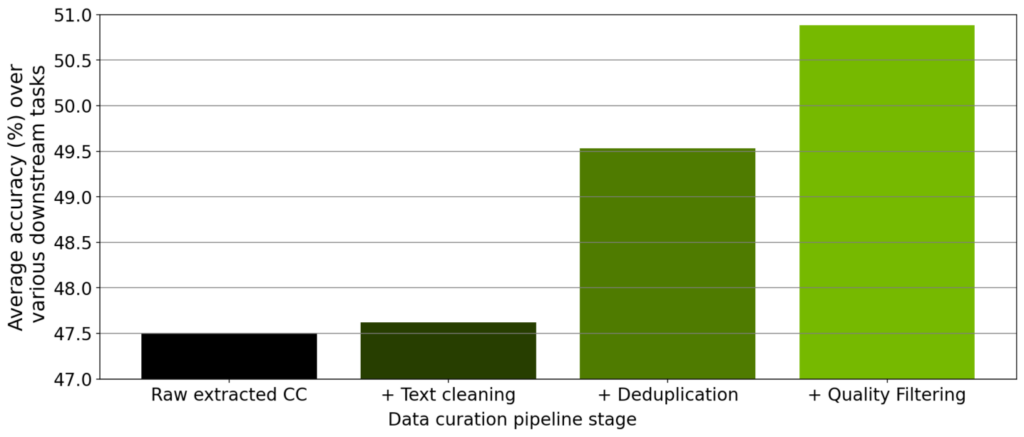
各モジュールのスケーリングを検証しましたが、その他に、ツール内で実装されたデータ キュレーション パイプラインの各ステップからキュレーションされたデータのアブレーション スタディも行いました。ダウンロードした Common Crawl のスナップショットから始めて、抽出、クリーニング、重複排除、フィルタリングを行った後、このスナップショットからキュレーションされた 7,800 万のトークンで 3 億 5,700 万パラメーターの GPT モデルをトレーニングしました。
事前トレーニングをそれぞれ実験した後、ゼロショット設定で RACE-High、PiQA、Winogrande、Hellaswag のタスクすべてでモデルを評価しました。図 3 は、アブレーション実験の結果における 4 つのタスクすべての平均値を示しています。データがパイプラインの各ステージを進むにつれて、4 つのタスクすべての平均値が大幅に増加し、データ品質が向上していることがわかります。
NeMo Data Curator による 2 兆トークン データセットのキュレーション
最近、NVIDIA NeMo のサービスとして早期アクセス ユーザー向けに、NVIDIA がトレーニングした 430 億パラメーターの多言語大規模基盤モデルをカスタマイズできるサービスの提供を開始しました。この基盤モデルを事前トレーニングするために、さまざまな分野に由来する 53 の自然言語と 37 種のプログラミング言語を含む 2 兆トークンで構成されるデータセットを準備しました。
この大規模なデータセットをキュレーションするには、Data Curator 内で実装されたデータ キュレーション パイプラインを、6,000 台超の CPU の CPU クラスター上にある合計 8.7 TB のテキスト データに適用する必要がありました。この 1 兆 1,000 億のトークンで 430 億の基盤モデルを事前トレーニングした結果、最先端の LLM が生まれ、現在は LLM のニーズに合わせて NVIDIA のお客様にご利用いただいています。
結論
LLM の事前トレーニング データセットをキュレーションするという需要の高まりに応えるために、NeMo フレームワークの一環として Data Curator をリリースしました。私たちは、このツールが LLM における下流のパフォーマンス向上につながる高品質データ キュレーションを行うツールであることを実証しました。さらに、Data Curator 内で利用可能なデータ キュレーション モジュールはそれぞれ、数千の CPU コアを使用できるまでにスケーリングできることも実証しています。事前トレーニング データセットを構築しようとしている LLM 開発者にとって、このツールが大きなプラスをもたらすと期待しています。