
NVIDIA プラットフォームは、アクセラレーテッド コンピューティングのための最も成熟した完全なプラットフォームです。この記事では、最もシンプルで生産性が高く、ポータブルなアクセラレーテッド コンピューティングへのアプローチを取り上げます。GPU プログラミングには、3 つのアプローチがあります (図 1)。
CUDA C++ および Fortran は、NVIDIA が新しいハードウェアおよびソフトウェアのイノベーションを公開し、開発者が NVIDIA GPU 上で可能な限り最高のパフォーマンスを実現するためにアプリケーションをチューニングすることができるイノベーションの基盤です。多くの開発者は、NVIDIA が GPU プログラミングをする全ての人に期待している方法がこれだと思っています。
しかし我々は、NVIDIA プラットフォームを初めて利用する開発者が、ISO C++、ISO Fortran、Python などの標準的な並列プログラミング言語を使用することを期待しています。この記事では、NVIDIA CUDA エコシステムを使い始めるための最も生産的な方法を示すために、この並列プログラミングへのアプローチを使用したいくつかの成功例を紹介します。
NVIDIA 戦略の基本は、アプリケーションを構築するための豊富で成熟した SDK とライブラリのセットを提供することです。NVIDIA はすでに、 cuBLAS 、 cuSolver 、 cuFFT などの高度にチューニングされた数学ライブラリ、 Thrust 、 libcu++ などのコア ライブラリ、 NCCL 、 NVSHMEM などの通信ライブラリ、その他のパッケージやフレームワークを提供しており、これらをベースにしてアプリケーションを構築することができます。
その上に、NVIDIA は 3 つの異なるプログラミング アプローチを重ねています。
- 今回のテーマである「標準言語による並列処理」
- NVIDIA プラットフォームで最高のパフォーマンスを得るための CUDA C++ や CUDA Fortran のような「プラットフォーム特化型の言語」
- これら 2 つのアプローチのギャップを埋め、段階的なパフォーマンス最適化を可能にする「コンパイラ ディレクティブ」
これらのアプローチはそれぞれ、パフォーマンス、生産性、コードのポータビリティの点でトレードオフの関係にあります。これらはすべて相互運用が可能なため、特定のモデルを使用する必要はなく、必要に応じて任意のモデルを組み合わせて使用することができます。
標準的なプログラミング言語で並列処理を使ったコードを書き始めれば、NVIDIA プラットフォームやその他のプラットフォームに、すでに並列処理が可能なベースラインコードを持ってくることができます。このような理由から、私たちは 10 年以上をかけて、標準言語の委員会において、追加の拡張機能や API を必要とせずに並列プログラミングを可能にする機能の採用に協力してきました。標準言語による並列処理は、すべての船を引き上げる満ち潮のようなものです。
ISO C++
C++ は、最近のプログラミング トレンド調査で常に上位にランクインしているプログラミング言語です。また、科学技術計算の分野での利用も大幅に増加しています。標準テンプレートライブラリが充実しているため、新しいコードを開発するのに非常に生産性の高い言語であり、C++17 以降は並列プログラミングのためのいくつかの重要な機能をサポートしています。
私はいくつかのアプリケーションで、従来の for ループからこれらの C++ 並列アルゴリズムへとリファクタリングされたものを見てきました。以下にその結果を示します。
Lulesh
Lulesh は Lawrence Livermore National Laboratory (LLNL) が開発した C++ で書かれた流体力学のミニアプリです。このミニアプリには、コードの品質と性能の両面からさまざまなプログラミング手法を評価するための複数のバージョンがあります。私たちは開発者と協力して、OpenMP ベースの既存のコードを C++ 並列アルゴリズムを使用するように書き換えました.図 2 は、このアプリケーションの重要な関数の一例です。

左のコードでは、OpenMP を使用して、コード内のループを CPU スレッド間で並列化しています。このコードのシリアル版とパラレル版の両方を維持するために、開発者は #ifdef マクロとコンパイラ プラグマを使用しました。その結果、コードが繰り返され、ソースには OpenMP という追加の API が導入されることになりました。
右側のコードは、同じルーチンを C++ の transform_reduce アルゴリズムで書き直したものです。結果として、コードははるかにコンパクトになり、エラーが起こりにくく、読みやすく、メンテナンス性も向上しました。また、OpenMP への依存を排除し、代わりに C++ 標準のテンプレート ライブラリを利用するとともに、すべてのプラットフォームに対応するシングル ソース コードを維持しています。このコードは ISO C++ に完全に準拠しており、C++17 をサポートするあらゆる C++ コンパイラでビルドすることができます。また、結果的に高速化も実現しています。
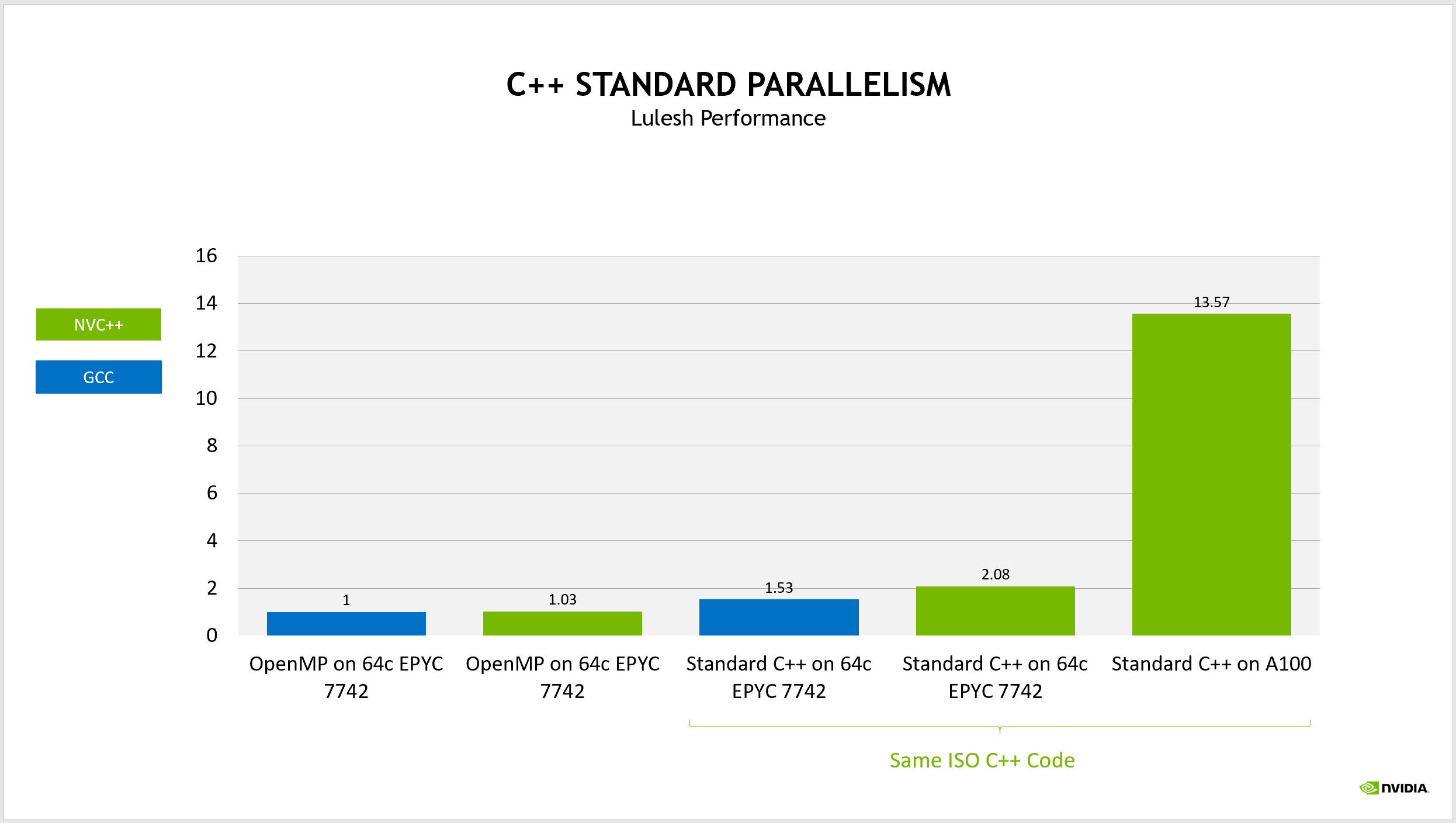
nvc++ コンパイラで再構築すると、CPU 上でほぼ同じ性能が得られます。同じバージョンの GCC を使って ISO C++ のコードをビルドし、同じ CPU で動作させた場合、さまざまなオーバーヘッドが改善され、コンパイラがコードをより最適化できるようになったため、パフォーマンスは約 50 %向上しました。
また nvc++ を使ってこのコードをビルドし、同じ CPU 上で動作させた場合、2 倍の性能向上となります。これはすでにエキサイティングな成果ですが、同じコードを、マルチコア CPU ではなく NVIDIA GPU をターゲットとするようにコンパイルオプションを変更するだけでビルドすることができます。同じコードを NVIDIA A100 GPU で実行すると、13 倍以上の速度で動作します。厳密に ISO C++ コードを使用して、 CPU と GPU の両方で並列実行した場合、元のコードと比べて 13.5 倍の性能向上が見られました。
STLBM
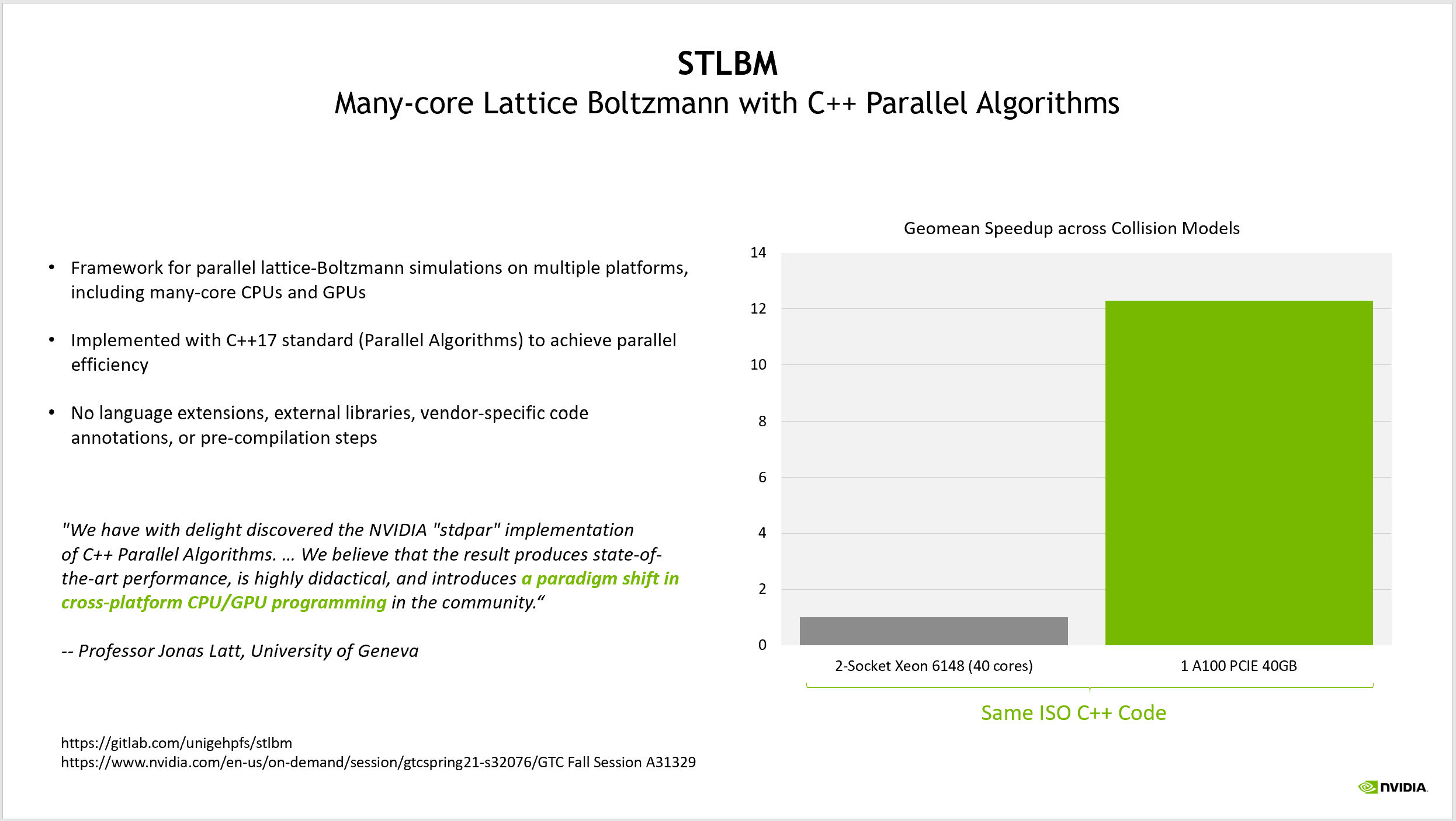
C++ 標準の並列処理を利用したアプリケーションの他の例としては、ジュネーブ大学の格子ボルツマン ソルバー STLBM があります。Jonas Latt 教授は,このアプリケーションについて、いくつかの GTC セッションで議論しました。そこでは、外部の SDK に依存せずに ISO C++ でどのようにコードを書き、複数のコンパイラと、NVIDIA GPU を含む複数のハードウェア プラットフォーム上で動作することを示しました。詳細については Fluid Dynamics on GPUs with C++ Parallel Algorithms: State-of-the-Art Performance through a Hardware-Agnostic Approach そして Porting a Scientific Application to GPU Using C++ Standard Parallelism をご覧ください。
彼のアプリケーションは、GPU を用いて 12 倍以上の性能向上を達成しています。注目すべき点は、彼の比較の基準がデフォルトで並列化されたソース コードであり、アプリケーションに内在する並列処理を表現するために C++17 標準テンプレート ライブラリの並列アルゴリズムを使用していることです。
彼は、ISO C++ を使って GPU のプログラムを作成した経験を、「 クロスプラットフォームの CPU / GPU プログラミングにおけるパラダイムシフト」と分類しています。彼のチームは、デフォルトでシリアルなアプリケーションを書いて後から並列処理を追加するのではなく、実行したいと思うあらゆる並列プラットフォームに対応したアプリケーションを書きました。
NVIDIA は、C++ における並列処理と並行処理の継続的な開発に多大な投資を行っており、来るべき C++23 仕様に対して、並列優先のコードを書く能力をさらに向上させるための様々な提案を共同で行なっています。
ISO Fortran
Fortran は、今でも科学技術計算やハイパフォーマンス コンピューティングに主眼を置いた言語です。もともと FORmula TRANslator と呼ばれていた Fortran は、開発者とコンパイラの両方にさまざまなメリットをもたらし、また、モデリングやシミュレーション コードの膨大な既存コード ベースを持っています。
Fortran は、Fortran 2008 で並列プログラミングをサポートするための機能を追加し始め、Fortran 2018 ではその機能を強化し、現在 Fortran 202X と呼ばれている次期バージョンでもその機能に磨きをかけています。ISO C++ と同様に、NVIDIA はアプリケーション開発者と協力して、Fortran の標準言語による並列処理を利用してアプリケーションをモダンで並列第一主義なものにしています。
計算化学
私の同僚である Jeff Hammond は、FortranCon2021: Standard Fortran on GPUs and its utility in quantum chemistry codes のセッションで、NWChem や別の計算化学アプリケーションである GAMESS から取り出したカーネルに Fortran の do concurrent ループを使用した期待できる結果を発表しました。
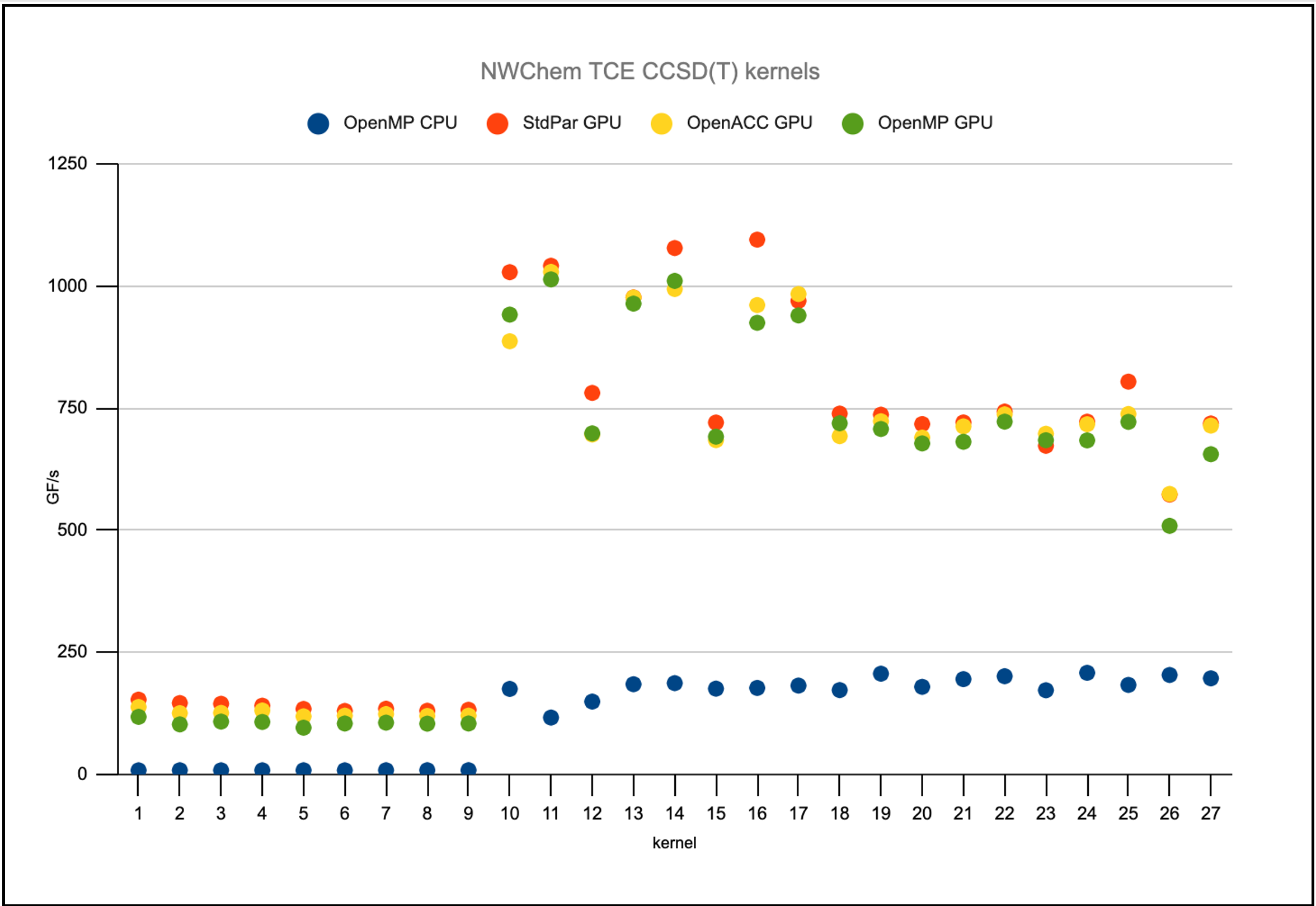
NWChem では、テンソル縮約を行うパフォーマンス クリティカルなループをいくつか分離し、いくつかのプログラミング モデルを用いて記述しました。マルチコアの CPU では、これらのテンソル縮約は CPU コア間のスレッド化に OpenMP を使用しています。GPU では、OpenACC、OpenMP ターゲット オフロード、そして Fortran の do concurrent ループを使用したバージョンがあります。
図 5 は、do concurrent ループが、NVIDIA GPU で OpenACC および OpenMP ターゲット オフロードの両方と同じレベルの性能を発揮していることを示しています。しかしこれらのような追加 API をアプリケーションに組み込む必要はありません。すべて標準の Fortran です。
高性能フラックス輸送
SC21 で開催された Workshop for Accelerator Programming Using Directives (WACCPD) では、Predictive Science Inc. の開発者チームが、以前は OpenACC を使っていた NVIDIA GPU 上で動作するプロダクション コードを、do concurrent のループを使ってリファクタリングした成果を発表しました。
彼らは、この純粋な ISO Fortran アプリケーションを NVIDIA nvfortran、gfortran、ifort を用いてビルドした結果を比較しました。その結果、このアプリケーションで nvfortran コンパイラを使用した場合、純粋な Fortran はディレクティブを使用しなくても必要なパフォーマンスが得られるという結論に達しました。さらに、このコードは、 GPU やマルチコアの CPU でも修正なしで並列に実行できました。

Legate と cuNumeric を利用した Python
Python 言語は、過去 10 年間で人気が急上昇しました。現在では、機械学習やデータサイエンス、さらには従来のモデリングやシミュレーションのアプリケーションでもよく使われています。Python は C++ や Fortran のような ISO プログラミング言語ではありませんが、標準言語による並列処理の精神を Python 言語にも実装しています。
NVIDIA CEO のジェンスン フアンは GTC21 Fall の基調講演で、NumPy をモデルとし、私が ISO C++ や Fortran で説明したような機能を実現するライブラリである cuNumeric のアルファ リリースを紹介しました。NumPy パッケージは Python による開発で非常に普及しており、 Python で書かれた HPC アプリケーションではほぼ確実に使用しています。
cuNumeric パッケージは、 Legate と呼ばれるパッケージ上で書かれており、 NumPy アプリケーションが、その作業を GPU 上だけでなく、大規模なクラスタ内の GPU 全体に自動的にスケーリングできるようにします。いくつかのアプリケーション例では、コード中の NumPy への参照を cuNumeric への参照に置き換えるだけで、世界最速のスーパーコンピューターである NVIDIA 内部クラスター Selene のフルサイズにウィークスケールできることを確認しました。
cuNumeric についての詳しい情報は NVIDIA Announces Availability for cuNumeric Public Alpha と GTC On-Demand セッション Legate: Scaling the Python Ecosystem をご覧ください。
結論
この記事を読んで、 GPU プログラミングは聞いていたほど難しいものではないことがわかってもらえたと思います。標準言語による並列処理を利用すれば、コードを全く変更せずに実現できるかもしれません。
NVIDIA は、アプリケーションを新しいプラットフォームに「移植」する必要がないように、アプリケーションを並列第一主義で書くことを奨励しています。標準言語による並列処理は、ISO 標準言語以外に何も必要としないため、これを行うための最良のアプローチです。そのために、私たちは ISO プログラミング言語への投資を続け、これらの言語に並列処理と並行処理のためのさらなる機能を提供しています。
要約すると、標準言語による並列処理を使うことで、以下のようなメリットがあります。
- ISO 言語に完全準拠し、よりポータブルなコードを実現
- よりコンパクトで読みやすく、エラーの少ないコード
- デフォルトで並列化されているコードなので、より多くのプラットフォームで変更なしに実行可能
以下は、このような並列プログラミングへのアプローチについて、さらに詳しく紹介した GTC21 の講演です。
- Shifting through the Gears of GPU Programming: Understanding Performance and Portability Trade-offs
- Accelerated Computing with Standard C++, Python, and Fortran
- Legate: Scaling the Python Ecosystem
詳しくは以下の資料をご覧ください。
- コンパイラのサポートやその他の投稿については HPC SDK をご覧ください。
- HPC SDK ソフトウェアを無料でダウンロードできます。
翻訳に関する免責事項
この記事は、「Developing Accelerated Code with Standard Language Parallelism」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。