Mixture of Experts (MoE) 大規模言語モデル (LLM) アーキテクチャは、GPT-4 などの商用の LLM と Mistral Mixtral 8x7B のオープン ソース リリースによりコミュニティ モデルの両方で最近登場しました。Mixtral モデルの強力な相対的性能は、MoE を LLM アーキテクチャでどのように使用できるのか、多くの関心と疑問を引き起こしました。では、MoE とは何であり、なぜそれが重要なのでしょうか?
Mixture of Experts は、レイヤーまたは演算 (線形レイヤー、MLP、注意投影など) の計算を複数の「エキスパート」サブネットワークに分割するニューラル ネットワークのアーキテクチャ パターンです。こうしたサブネットワークはそれぞれの計算を独立して実行し、その結果を組み合わせて MoE レイヤーの最終出力とします。MoE アーキテクチャは密 (すべての入力ですべてのエキスパートが使用される) になるか、疎 (すべての入力にエキスパートのサブセットが使用される) になるかのいずれかになります。
この記事では主に、LLM アーキテクチャにおける MoE の応用に焦点を当てます。他の分野で MoE を応用する方法については、「Scaling Vision with Sparse Mixture of Experts」、「Mixture-of-Expert Conformer for Streaming Multilingual ASR」、「FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting」を参照してください。
LLM アーキテクチャにおける Mixture of Experts
このセクションでは、背景にある情報をいくつか紹介し、LLM アーキテクチャで MoE を使用する利点について説明します。
モデル容量
モデル容量は、あるモデルで理解または表現できる複雑さのレベルとして定義することができます。一般的に、モデルのパラメーターが多ければ多いほど (十分にトレーニングされている場合) 容量がそれだけ大きくなることがこれまで証明されています。
MoE は容量にどのように関係するのでしょうか? 通常、モデルのパラメーターが多ければ多いほど、容量はそれだけ大きくなります。MoE モデルでは、モデルのレイヤーを、エキスパート サブネットワークが元のレイヤーと同じ大きさになる MoE レイヤーへ置換することで、ベースのモデルに比べ、容量を効果的に増やすことができます。
同量のトークンでトレーニングされた同様のサイズの完全な密モデルに対する MoE モデルの精度を研究者が調査しています (MoE サイズ: E*P パラメーターを完全に密なサイズ: EP パラメーターと比較)。一般的に完全な密モデルのほうが性能的に優れていますが、この分野はまだ活発な研究が行われている最中です。詳細については、「Unified Scaling Laws for Routed Language Models」を参照してください。
これは、密モデルだけを使用していればよいのではないかという疑問を生じさせます。ここでの答えは疎 MoE にあります。とりわけ、使用されるパラメーターあたりの FLOP 効率については、疎 MoE のほうが優れているという事実があります。
Mixtral 8x7B について考えてみてください。これは、8 つのエキスパートによる MoE を使用するモデルであり、トークンごとにエキスパートが 2 つだけ使用されます。この場合、モデル内で 1 個のトークンを前方にパスするとき、あるバッチで特定のトークンに使用されるパラメーター数がはるかに少なくなります (合計 460 億パラメーターのうち 120 億パラメーターが使用されます)。8 つ全てのエキスパートや同様のサイズの完全な密モデルを使用する場合と比較して必要な計算量が少なくなります。トークンはトレーニングでバッチ処理されるため、全てではないにしてもほとんどのエキスパートが使用されます。つまり、この方式では、疎 MoE は、同じサイズの密モデルと比較したとき、メモリ容量が同じで計算量が少なくなります。
GPU 時間がとても貴重なリソースとなる世界では、完全な密モデルを大規模にトレーニングすることは、時間とコストの両面で法外に高くつきます。(完全に密な) モデルの Llama 2 セットを Meta がトレーニングしたところ、事前トレーニングに 330 万 NVIDIA A100 GPU 時間かかったと報告されています。これを具体的に説明すると、1,024 基の GPU 全てを使って 330 万 GPU 時間をダウンタイムなしで実行するには、およそ 134 日かかる計算になります。これには、実験、ハイパーパラメーターの探索、トレーニングの中断は含まれていません。
コストを削減しながら、MoE でより大きなモデルをトレーニング
MoE モデルは、パラメーターあたりのフロップ効率を上げることでコストを削減します。つまり、固定時間または計算コストの制約がある条件下では、処理できるトークンが増え、モデルをさらにトレーニングできます。モデルのパラメーターが多ければ多いほど、完全収束のために必要なサンプルがそれだけ多くなるため、つまるところ、固定された予算では、密モデルよりも MoE モデルをよりトレーニングできることになります。
MoE はレイテンシが小さい
演算がボトルネックとなる大規模なプロンプトやバッチでは、MoE アーキテクチャを利用することで、ファーストトークンの待ち時間を短縮できます。検索拡張生成 (RAG) や自律型エージェントなどの用途ではモデルへの多数の呼び出しが発生するため、1 回の呼び出しのレイテンシを小さくすることがさらに重要になります。
MoE アーキテクチャの仕組みとは?
MoE モデルには重要なコンポーネントが 2 つあります。1 つ目は混合を構成する「エキスパート」サブネットワークです。これは密 MoE と疎 MoE の両方に使用されます。2 つ目は疎モデルで使用されるルーティング アルゴリズムであり、どのトークンをどのエキスパートが処理するか決定します。密および疎 MoE の一部の式には、エキスパート出力の加重平均を実行する重み付けメカニズムが含まれることがあります。この記事では疎のケースを取り上げます。
発表されている多くの論文では、MoE 手法は Transformer Block 内の多層パーセプトロン (MLP) に適用されています。 この場合、Transformer Block 内の MLP は通常、エキスパート MLP サブネットワークのセットで置き換えられます。その結果が統合されて、平均または合計を使って MLP MoE の出力が生成されます。
研究では、MoE の概念を Transformer アーキテクチャの他の部分にも適用できることも示唆されています。最近の論文「SwitchHead: Accturerating Transformers with Mixture-of-Experts Attention」では、入力を Q、K、V 行列に変換し、アテンション演算に使用させるプロジェクション レイヤーにも MoE を応用できることが示唆されています。アテンション ヘッド自体に条件付き実行 MoE の概念を適用することを提案している論文もあります。
ルーティング ネットワーク (またはアルゴリズム) は、特定の入力の場合にどのエキスパートが活性化するか判断する目的で使用されます。「Mixture-of-Experts with Expert Choice Routing」で説明されているように、ルーティング アルゴリズムはシンプルなもの (一様に選択または Tensor の平均値でのビン分割) から複雑なものまで様々です。
特定のルーティング アルゴリズムをある問題に応用できるか決定する要因は色々ありますが、その中でも 2 つの中心的な要因についてしばしば議論されています。特定のルーティング方式の下でのモデル精度と、特定の方式の下での負荷分散です。正しいルーティング アルゴリズムの選択は、精度と FLOP 効率性のトレードオフになることがあります。負荷分散が完璧なルーティング アルゴリズムでは、トークンあたりの精度が落ちる可能性があり、最も精度の高いルーティング アルゴリズムではエキスパート間でトークンが不均等に分配される可能性があります。
提案されているルーティング アルゴリズムの多くは、モデル精度を最大化しつつ、特定のエキスパートから提示されるボトルネックを最小化するように設計されています。Mixtral 8x7B では Top-K アルゴリズムでトークンをルーティングしますが、「Mixture-of-Experts with Expert Choice Routing」などの論文では、特定のエキスパートへ過度にルーティングされないようにする概念が導入されています。これによりボトルネックの発生を防ぎます。
Mixtral モデルの実験
実際のところ、各エキスパートは何を学ぶのでしょう? 句読点、動詞、形容詞など、下位の言語構成に特化しているのか? それとも、コーディング、数学、生物学、法律など、より上位の概念やドメインの達人なのでしょうか?
これを確認するため、私たちは、Mixtral 8x7B モデルを利用する実験を設計しました。このモデルには 32 層の Transformer Block があり、各 MLP レイヤーは、エキスパートが 8 つの疎 MoE ブロックに置き換えられます。各トークンに対してそのうちの 2 つだけが活性化されます。セルフアテンション レイヤーや正規化レイヤーなどの残りのレイヤーはすべてのトークンで共有されます。
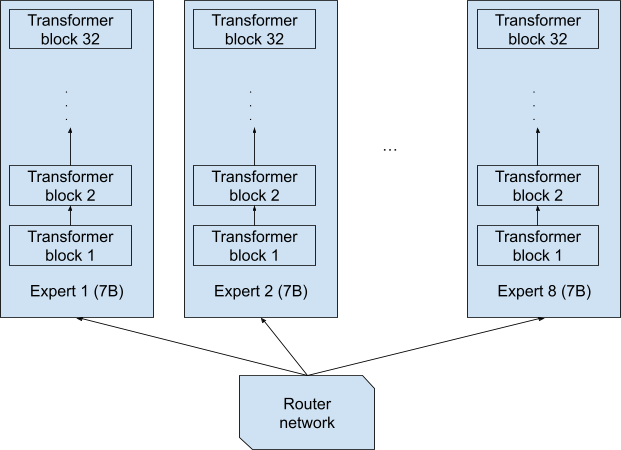
8x7B という名前から、エキスパートは 8 つの完全に個別なネットワークで、それぞれにパラメーターが 70 億あり、8 つの完全に個別なネットワークのひとつにより各トークンが完全にエンドツーエンドで処理されるものと想像されるかもしれません (図 1)。この設計では、8x7B = 56B (560 億) モデルになります。
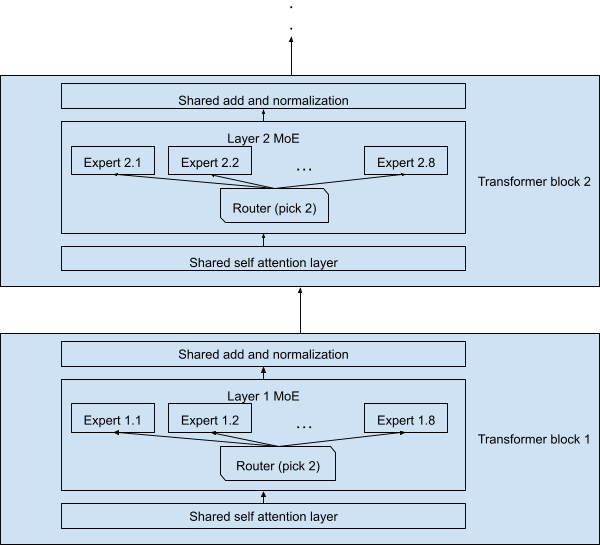
これは確かにもっともらしい設計ですが、Mixtral 8x7B で使用されているものではありません。実際の設計は図 2 です。各トークンは 70 億のパラメーターで処理されます。トークンとそのコピー (各レイヤーで 2 番手に選ばれたエキスパートによって処理される) は合計 129 億個のパラメーターのみで処理されます。2x7B = 14B ではありません。また、共有レイヤーのおかげで、ネットワーク全体は 8x7B = 56B パラメーターではなく、470 億だけになります。
したがって、ネットワークを通過する各トークンは格子状の構造を通過する必要があります。各レイヤーでの 2 つのエキスパートの組み合わせは 通り考えられます。Mixtral 8x7B には 32 個の Transformer Block があるため、ネットワークのインスタンス化は合計
と通り考えられます。
このインスタンス化のそれぞれを「フルスタックのエキスパート (トークンをエンドツーエンドで処理する) 」と見なす場合、どのような専門知識を提供するのか分かるのでしょうか? 残念ながら、28^{32} は非常に大きな数であり (~2×10^{46})、LLM のトレーニングに使用されるデータよりも桁違いに大きいため (ほとんどの LLM で 3T ~ 10T 個のトークン)、2 つのトークンが同じインスタンス化によって処理されることはめったにありません。したがって、完全な各エキスパートの組み合わせではなく、各レイヤーのエキスパートが何に特化しているのかを調べます。
実験結果
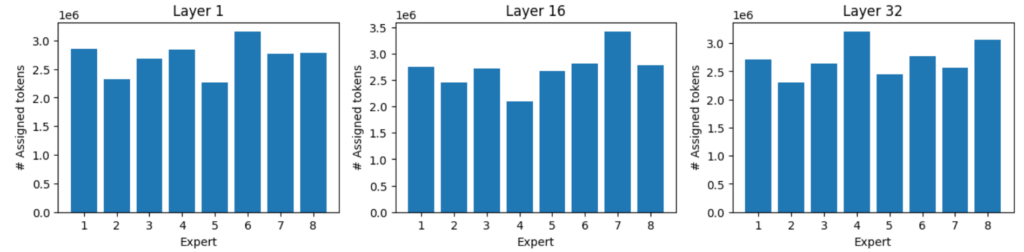
このモデルを利用し、Massive Multitask Language Understanding (MMLU) ベンチマークの全サンプルを実行しました。これには、抽象代数学、世界の宗教、専門的な法律、解剖学、天文学、ビジネス倫理など、57 のトピックに関する多肢選択問題が含まれます。レイヤー 1、16、32 の 8 つのエキスパートそれぞれについて、トークンエキスパートの割り当てを記録しました。
データを解析してみると、注目すべき点がいくつかあります。
負荷分散
負荷分散のおかげで、エキスパートには均等な負荷が与えられますが、最も忙しいエキスパートは最も忙しくないエキスパートに比べ、受け取るトークンが最大 40–60% 多くなります。
ドメイン エキスパートの割り当て
ドメインによっては、一部のエキスパートが他のエキスパートよりも活性化されます。
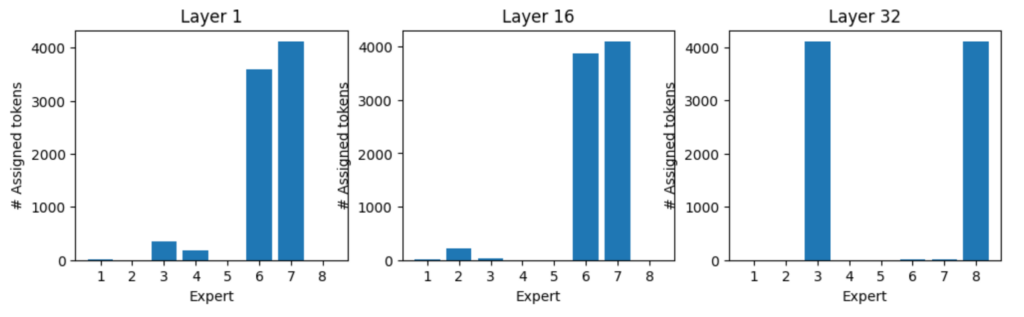
レイヤー 32 では、そのような例のひとつが抽象代数です。エキスパート 3 と 8 が他のエキスパートより使用されています。
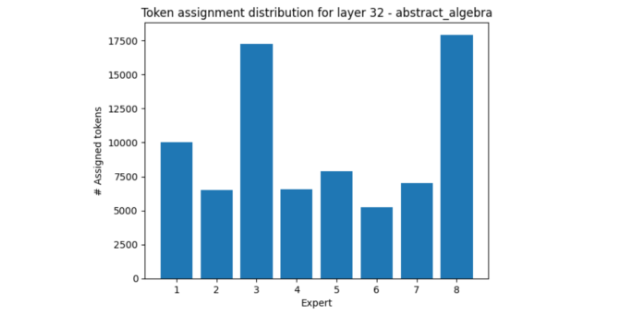
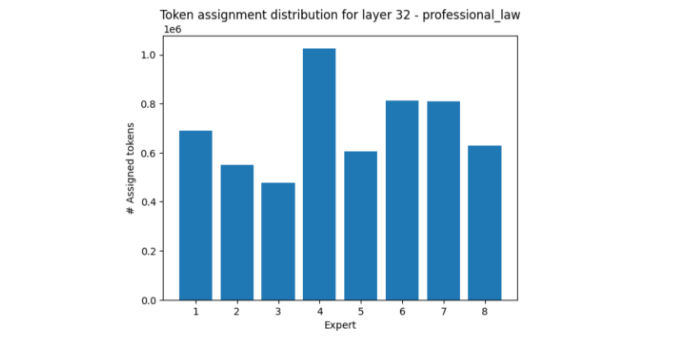
一方、専門的な法律の分野では、ほとんどの場合、エキスパート 4 が活性化され、エキスパート 3 と 8 は比較的おとなしくなっています。
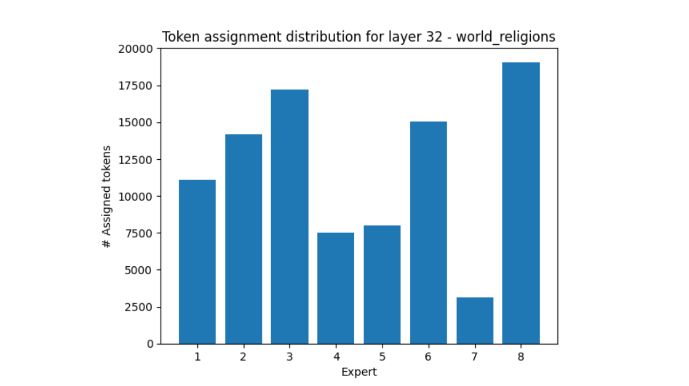
世界の宗教も興味深い例となっています。エキスパート 7 が受け取るトークンの数はエキスパート 8 の 5 分の 1 です。
以上の実験の結果から、エキスパートの負荷分散は、さまざまなトピックを経て均一化に向かう傾向があることがわかります。ただし、特定のトピックの下にすべてのサンプルが属するとき、分散が大きく偏る可能性があります。
エキスパートが最も好むトークン
図 7 のワード クラウドは、各エキスパートが最も頻繁に処理したトークンを示しています。

トークンが最も好むエキスパート
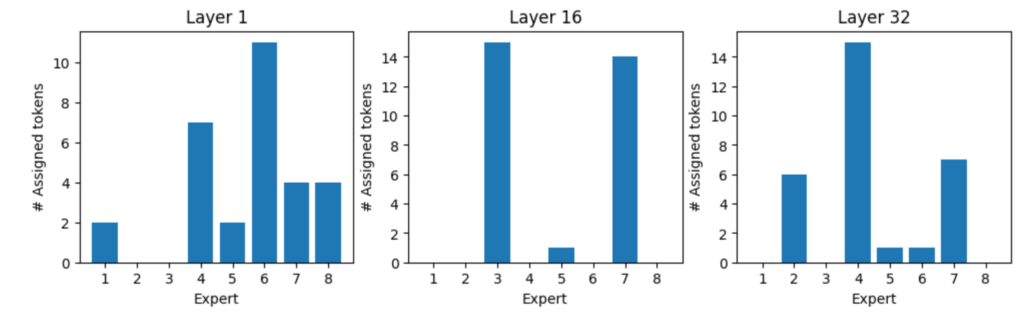
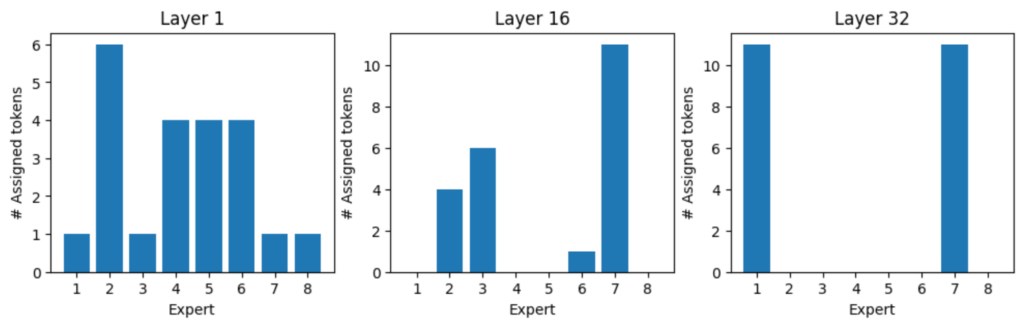
各トークンには優先的なエキスパートがいるのでしょうか? 以下の例に示すように、トークンにはそれぞれ、最も好まれるエキスパートのセットがあるようです。
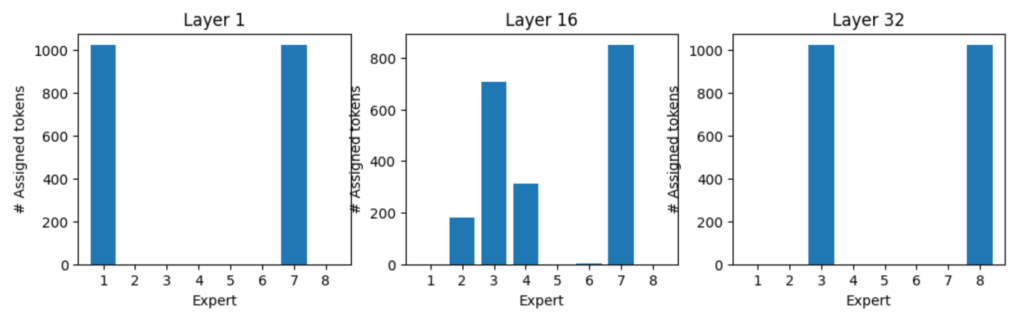
トークン「:」のエキスパート割り当て、トークン「:」はすべて、レイヤー 1 では、エキスパート 1 と 7 によって処理され、レイヤー 32 ではエキスパート 3 と 8 によって処理されます (図 8)。図 9、10、11 は、さまざまなトークンのエキスパート割り当てを示しています。
まとめ
MoE モデルが事前トレーニングのスループットに与える恩恵は実証されており、表現力に優れた疎 MoE モデルを密モデルと同じ演算量でトレーニングできるようにします。これにより、同じコンピューティング予算でより競争力のあるモデルを実現できます。MoE モデルは、ネットワーク全体を対象にすることも、既存のネットワーク内の特定のレイヤーを対象にすることもできます。一般的に、ルーティングをともなう疎 MoE は、一部のエキスパートのみが使用されるように適用されます。
今回の実験では、トークンが割り当てられる仕組みと、エキスパート間の相対的な負荷分散を調べました。こうした実験からは、負荷分散アルゴリズムにもかかわらず、分散に大きな偏りが生じ、一部のエキスパートが仕事をすぐに終えている一方で、他のエキスパートへ過剰に仕事が割り当てられているなど、推論が非効率になる可能性を示しています。これは活発に研究されている興味深い分野です。
Mixtral 8x7B Instruct やその他の AI 基盤モデルを NVIDIA NGC カタログで試すことができます。もっと詳しく知りたいですか? NVIDIA GTC 2024 のパネル セッション「Mistral AI: Frontier AI in Your Hands」をお見逃しなく。
関連情報
- GTC セッション: Designing End-to-End Solutions for Building LLM Infrastructures, Accelerating Training Speeds, and Advancing Generative AI Innovation (Presented by Aivres)
- GTC セッション: Techniques for Improving the Effectiveness of RAG Systems
- GTC セッション: Architecting for the New Language Model Stack
- NGC コンテナー: genai-llm-playground
- ウェビナー: Implementing Large Language Models
- ウェビナー: Harness the Power of Cloud-Ready AI Inference Solutions and Experience a Step-By-Step Demo of LLM Inference Deployment in the Cloud