
Large language models (LLMs) have impressed the world with their unprecedented capabilities to comprehend and generate human-like responses. Their chat functionality provides a fast and natural interaction between humans and large corpora of data. For example, they can summarize and extract highlights from data or replace complex queries such as SQL queries with natural language.
It is tempting to assume that business value can be generated by these models with no extra effort, but this is unfortunately not often the case. Luckily, all that enterprises must do to extract value out of using LLMs is to augment the LLM with their own data. This can be done with retrieval augmented generation (RAG), which is showcased in the NVIDIA Generative AI Examples GitHub repo for developers
By augmenting an LLM with business data, enterprises can make their AI applications agile and responsive to new developments. For instance:
- Chatbots: Many enterprises already use AI chatbots to power basic customer interactions on their websites. With RAG, companies can build a chat experience that’s highly specific to their product. For example, questions about product specifications could easily be answered.
- Customer service: Companies can empower live service representatives to easily answer customer questions with precise, up-to-date information.
- Enterprise search: Businesses have a wealth of knowledge across the organization, including technical documentation, company policies, IT support articles, and code repositories. Employees could query an internal search engine to retrieve information faster and more efficiently.
This post explains the benefits of using the RAG technique when building an LLM application, along with the components of a RAG pipeline. For more information after you finish this post, see RAG 101: Retrieval-Augmented Generation Questions Answered.
Benefits of RAG
There are several advantages of using RAG:
- Empowering LLM solutions with real-time data access
- Preserving data privacy
- Mitigating LLM hallucinations
Empowering LLM solutions with real-time data access
Data is constantly changing in an enterprise. AI solutions that use LLMs can remain up-to-date and current with RAG, which facilitates direct access to additional data resources. These resources can consist of real-time and personalized data.
Preserving data privacy
Ensuring data privacy is crucial for enterprises. With a self-hosted LLM (demonstrated in the RAG workflow), sensitive data can be kept on-premises just like the stored data.
Mitigating LLM hallucinations
When LLMs are not supplied with factual actual information, they often provide faulty, but convincing responses. This is known as hallucination, and RAG reduces the likelihood of hallucinations by providing the LLM with relevant and factional information.
Building and deploying your first RAG pipeline
A typical RAG pipeline consists of several phases. The process of document ingestion occurs offline, and when an online query comes in, the retrieval of relevant documents and the generation of a response occurs.
Figure 1 shows an accelerated RAG pipeline that can be built and deployed in the /NVIDIA/GenerativeAIExamples GitHub repo.
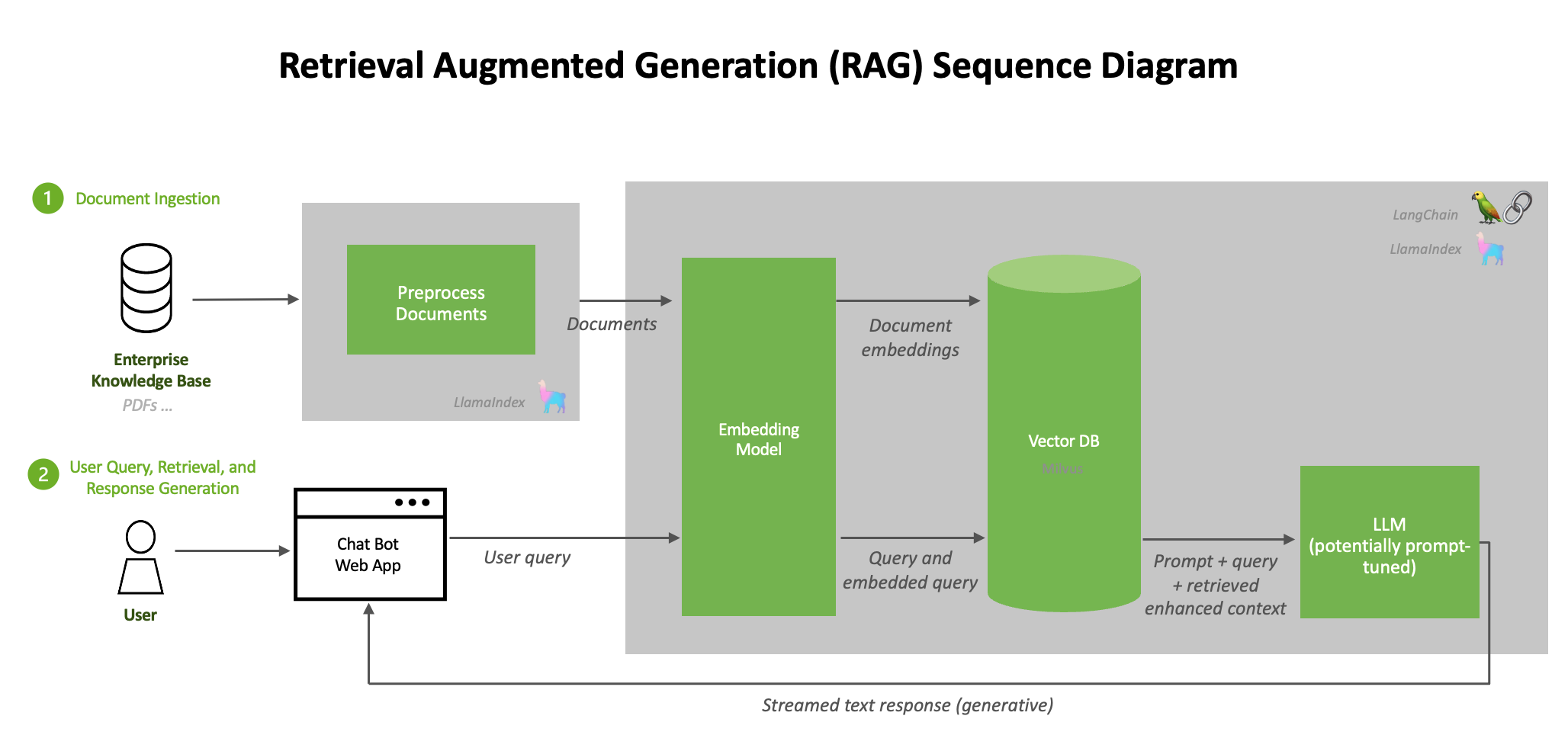
Each logical microservice is separated into containers available in the NGC public catalog. On a high level, the architecture of a RAG system can be distilled down to the pipelines shown in Figure 1:
- A recurring pipeline of document pre-processing, ingestion, and embedding generation
- An inference pipeline with a user query and response generation
Document ingestion
First, raw data from diverse sources, such as databases, documents, or live feeds, is ingested into the RAG system. To pre-process this data, LangChain provides a variety of document loaders that load data of many forms from many different sources.
The term document loader is used loosely. Source documents do not necessarily need to be what you might think of as standard documents (PDFs, text files, and so on). For example, LangChain supports loading data from Confluence, CSV files, Outlook emails, and more. LlamaIndex also provides a variety of loaders, which can be viewed in LlamaHub.
Document pre-processing
After documents have been loaded, they are often transformed. One transformation method is text-splitting, which breaks down long text into smaller segments. This is necessary for fitting the text into the embedding model, e5-large-v2, which has a maximum token length of 512. While splitting the text sounds simple, this can be a nuanced process.
Generating embeddings
When data is ingested, it must be transformed into a format that the system can efficiently process. Generating embeddings involves converting data into high-dimensional vectors, which represent text in a numerical format.
Storing embeddings in vector databases
The processed data and generated embeddings are stored in specialized databases known as vector databases. These databases are optimized to handle vectorized data, enabling rapid search and retrieval operations. Storing the data in RAPIDS RAFT accelerated vector databases like Milvus guarantees that information remains accessible and can be quickly retrieved during real-time interactions.
LLMs
LLMs form the foundational generative component of the RAG pipeline. These advanced, generalized language models are trained on vast datasets, enabling them to understand and generate human-like text. In the context of RAG, LLMs are used to generate fully formed responses based on the user query and contextual information retrieved from the vector DBs during user queries.
Querying
When a user submits a query, the RAG system uses the indexed data and vectors to perform efficient searches. The system identifies relevant information by comparing the query vector with the stored vectors in the vector DBs. The LLMs then use the retrieved data to craft appropriate responses.
Fast-track your deployment of this system by testing out this example workflow in the /NVIDIA/GenerativeAIExamples GitHub repo.
Get started building RAG in your enterprise
By using RAG, you can provide up-to-date and proprietary information with ease to LLMs and build a system that increases user trust, improves user experiences, and reduces hallucinations.
Explore the NVIDIA AI chatbot RAG workflow to get started building a chatbot that can accurately answer domain-specific questions in natural language using up-to-date information.
