

Imagine an AI program that can understand language better than humans can. Imagine building your own personal Siri or Google Search for a customized domain or application.
Google BERT (Bidirectional Encoder Representations from Transformers) provides a game-changing twist to the field of natural language processing (NLP).
BERT runs on supercomputers powered by NVIDIA GPUs to train its huge neural networks and achieve unprecedented NLP accuracy, impinging in the space of known human language understanding. AI like this has been anticipated for many decades. With BERT, it has finally arrived.
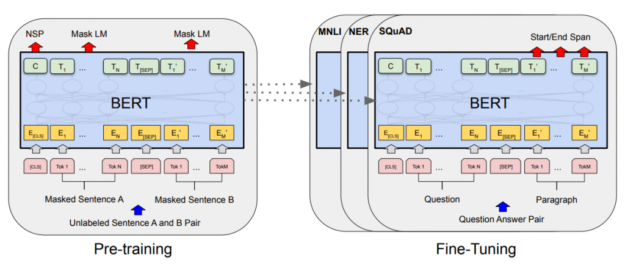
This post discusses more about how to work with BERT, which requires pretraining and fine-tuning phases. In this post, the focus is on pretraining.
What can BERT do?
With research organizations globally having conversational AI as the immediate goal in mind, BERT has made major breakthroughs in the field of NLP. In the past, basic voice interfaces like phone tree algorithms—used when you call your mobile phone company, bank, or internet provider—are transactional and have limited language understanding.
With transactional interfaces, the scope of the computer’s understanding is limited to a question at a time. This gives the computer a limited amount of required intelligence: only that related to the current action, a word or two or, further, possibly a single sentence. For more information, see What is Conversational AI?.
But when people converse in their usual conversations, they refer to words and context introduced earlier in the paragraph. Going beyond single sentences is where conversational AI comes in.
Here’s an example of using BERT to understand a passage and answer the questions. This example is more conversational than transactional. The example shows how well BERT does at language understanding. Take a passage from the American football sports pages and then ask a key question of BERT. This example is taken from The Steelers Look Done Without Ben Roethlisberger. What Will Happen Now?.
Passage: The Pittsburgh Steelers are a professional American football team based in Pittsburgh, Pennsylvania. The Steelers compete in the National Football League (NFL) as a member club of the American Football Conference (AFC) East division. The team plays its home games at Heinz Field. The Steelers earned 439,000,000 dollars last year. Their quarterback is named Ben Roethlisberger. Roethlisberger had already been dealing with an elbow issue. Ben was replaced by backup Mason Rudolph. His first pass bounced off receiver Donte Moncrief’s hands for an interception, but Rudolph rebounded to lead three scoring drives for 16 points in the second half. That wasn’t enough to stop the Steelers from falling to 0-2, and during the past 12 years roughly 90 percent of the teams that started 0-2 have missed the playoffs. Those odds likely already have Steelers fans thinking about next year, and it’s hard not to wonder about Roethlisberger’s future as well. Question: Who replaced Ben? Running Inference… ------------------------ Running inference in 312.076 Sentences/Sec ------------------------ Answer: 'Mason Rudolph' With probability: 86.918
Amazing, right? The sentences are parsed into a knowledge representation. In the challenge question, BERT must identify who the quarterback for the Pittsburgh Steelers is (Ben Rothlisberger). In addition, BERT can figure out that Mason Rudolph replaced Mr. Rothlisberger at quarterback, which is a major point in the passage.
The inference speed using NVIDIA TensorRT is reported earlier at 312.076 sentences per second. If you take the reciprocal of this, you obtain 3.2 milliseconds latency time. This GPU acceleration can make a prediction for the answer, known in the AI field as an inference, quite quickly.
In 2018, BERT became a popular deep learning model as it peaked the GLUE (General Language Understanding Evaluation) score to 80.5% (a 7.7% point absolute improvement). For more information, see A multi-task benchmark and analysis platform for natural understanding.
Question answering is one of the GLUE benchmark metrics. A recent breakthrough is the development of the Stanford Question Answering Dataset or SQuAD, as it is the key to a robust and consistent training and standardizing learning performance observations. For more information, see SQuAD: 100,000+ Questions for Machine Comprehension of Text.
Having enough compute power is equally important. After the development of BERT at Google, it was not long before NVIDIA achieved a world record time using massive parallel processing by training BERT on many GPUs. They used approximately 8.3 billion parameters and trained in 53 minutes, as opposed to days. According to ZDNet in 2019, “GPU maker says its AI platform now has the fastest training record, the fastest inference, and largest training model of its kind to date.”
BERT background
BERT has three concepts embedded in the name.
First, transformers are a neural network layer that learns the human language using self-attention, where a segment of words is compared against itself. The model learns how a given word’s meaning is derived from every other word in the segment.
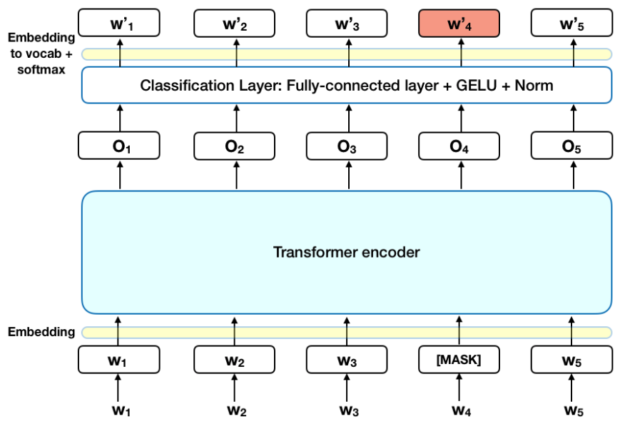
Second, bidirectional means that the recurrent neural networks (RNNs), which treat the words as time-series, look at sentences from both directions. The older algorithms looked at words in a forward direction trying to predict the next word, which ignores the context and information that the words occurring later in the sentence provide. BERT uses self-attention to look at the entire input sentence at one time. Any relationships before or after the word are accounted for.
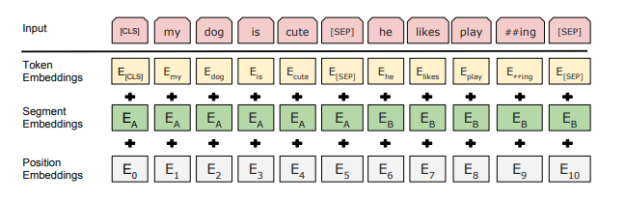
Finally, an encoder is a component of the encoder-decoder structure. You encode the input language into latent space, and then reverse the process with a decoder trained to re-create a different language. This is great for translation, as self-attention helps resolve the many differences that a language has in expressing the same ideas, such as the number of words or sentence structure.
In BERT, you just take the encoding idea to create that latent representation of the input, but then use that as a feature input into several, fully connected layers to learn a particular language task.
How to use BERT
Figure 4 implies that there are two steps to making BERT learn to solve a problem for you. You first need to pretrain the transformer layers to be able to encode a given type of text into representations that contain the full underlying meaning. Then, you need to train the fully connected classifier structure to solve a particular problem, also known as fine-tuning.
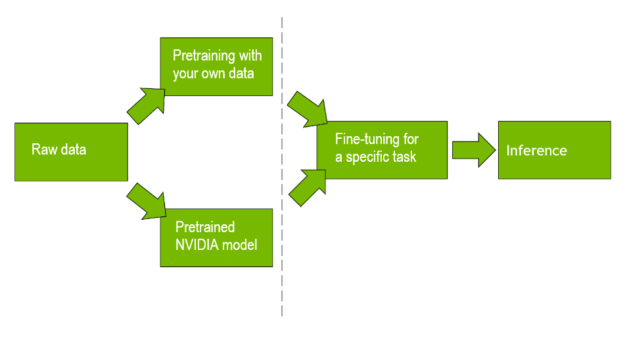
Pretraining is a massive endeavor that can require supercomputer levels of compute time and equivalent amounts of data. The open-source datasets most often used are the articles on Wikipedia, which constitute 2.5 billion words, and BooksCorpus, which provides 11,000 free-use texts. This culminates in a dataset of about 3.3 billion words.
All that data can be fed into the network for the model to scan and extract the structure of language. At the end of this process, you should have a model that, in a sense, knows how to read. This model has a general understanding of the language, meaning of the words, context, and grammar.
To have this model customized for a particular domain, such as finance, more domain-specific data needs to be added on the pretrained model. This allows the model to understand and be more sensitive to domain-specific jargon and terms.
A word has several meanings, depending on the context. For example, a bear to a zoologist is an animal. To someone on Wall Street, it means a bad market. Adding specialized texts makes BERT customized to that domain. It’s a good idea to take the pretrained BERT offered on NGC and customize it by adding your domain-specific data.
Fine-tuning is much more approachable, requiring significantly smaller datasets on the order of tens of thousands of labelled examples. BERT can be trained to do a wide range of language tasks.
Despite the many different fine-tuning runs that you do to create specialized versions of BERT, they can all branch off the same base pretrained model. This makes the BERT approach often referred to as an example of transfer learning, when model weights trained for one problem are then used as a starting point for another. After fine-tuning, this BERT model took the ability to read and learned to solve a problem with it.
What makes BERT special?
The earlier information may be interesting from an educational point of view, but does this approach really improve that much on the previous lines of thought? The answer is a resounding yes! BERT models can achieve higher accuracy than ever before on NLP tasks. One potential source for seeing that is the GLUE benchmark.
GLUE represents 11 example NLP tasks. One common example is named entity recognition or being able to identify each word in an input as a person, location, and so on. Another is sentence sentiment similarity, that is determining if two given sentences both mean the same thing. GLUE provides common datasets to evaluate performance, and model researchers submit their results to an online leaderboard as a general show of model accuracy.
In September 2018, the state-of-the-art NLP models hovered around GLUE scores of 70, averaged across the various tasks. While impressive, human baselines were measured at 87.1 on the same tasks, so it was difficult to make any claims for human-level performance.
BERT was open-sourced by Google researcher Jacob Devlin (specifically the BERT-large variation with the most parameters) in October 2018. While the largest BERT model released still only showed a score of 80.5, it remarkably showed that in at least a few key tasks it could outperform the human baselines for the first time. For more information, see BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
BERT obtained the interest of the entire field with these results, and sparked a wave of new submissions, each taking the BERT transformer-based approach and modifying it. Looking at the GLUE leaderboard at the end of 2019, the original BERT submission was all the way down at spot 17.
Most impressively, the human baseline scores have recently been added to the leaderboard, because model performance was clearly improving to the point that it would be overtaken. Sure enough, in the span of a few months the human baselines had fallen to spot 8, fully surpassed both in average score and in almost all individual task performance by BERT derivative models. Human baselines may be even lower by the time you read this post.
Similar to the advent of convolutional neural networks for image processing in 2012, this impressive and rapid growth in achievable model performance has opened the floodgates to new NLP applications.
Try out BERT
Nowadays, many people want to try out BERT. The question-answering process is quite advanced and entertaining for a user. Get started with our steps contained here.
An earlier post, Real-Time Natural Language Understanding with BERT Using TensorRT, examines how to get up and running on BERT using aNVIDIA NGC website container for TensorRT. We recommend using it. We had access to an NVIDIA V100 GPU running Ubuntu 16.04.6 LTS. If drive space is an issue for you, use the /tmp area by preceding the steps in the post with the following command:
cd /tmp
In addition, we have found another alternative that may help. Make sure that the script accessed by the path python/create_docker_container.sh has the line third from the bottom as follows:
-v ${PWD}/models:/models \
Also, add a line directly afterward that reads as follows:
-v ${HOME}:${HOME} \
After getting to the fifth step in the post successfully, you can run that and then replace the -p "..." -q "What is TensorRT?" passage and question shell command section as in the following command. This duplicates the American football question described earlier in this post.
python python/bert_inference.py -e bert_base_384.engine -p "The Pittsburgh Steelers are a professional American football team based in Pittsburgh, Pennsylvania. The Steelers compete in the National Football League (NFL) as a member club of the American Football Conference (AFC) East division. The team plays its home games at Heinz Field. The Steelers earned 439,000,000 dollars last year. Their quarterback is named Ben Roethlisberger. Roethlisberger had already been dealing with an elbow issue. Ben was replaced by backup Mason Rudolph. His first pass bounced off receiver Donte Moncrief’s hands for an interception, but Rudolph rebounded to lead three scoring drives for 16 points in the second half. That wasn’t enough to stop the Steelers from falling to 0-2, and during the past 12 years roughly 90 percent of the teams that started 0-2 have missed the playoffs. Those odds likely already have Steelers fans thinking about next year, and it’s hard not to wonder about Roethlisberger’s future as well." -q "Who replaced Ben?" -v /workspace/models/fine-tuned/bert_tf_v2_base_fp16_384_v2/vocab.txt -b 1
To try this football passage with other questions, change the -q "Who replaced Ben?" option and value with another, similar question.
For the two-stage approach with pretraining and fine-tuning, for NVIDIA Financial Services customers, there is a BERT GPU Bootcamp available. For information, contact one of the authors listed.
