
Predicting 3D protein structures from amino acid sequences has been an important long-standing question in bioinformatics. In recent years, deep learning–based computational methods have been emerging and have shown promising results.
Among these lines of work, AlphaFold2 is the first method that has achieved results comparable to slower physics-based computational methods. It was named Method of the Year 2021 by Nature. The model was built on a variant of the sequence attention mechanism widely adopted by other contemporary deep-learning models.
OpenFold is the first trainable public reimplementation of AlphaFold2 and reproduces the AlphaFold2 results. As an open-source project, OpenFold’s release enables researchers worldwide to apply and build on this technology.
Unfortunately, AlphaFold2’s time required to train remains a significant bottleneck.
AlphaFold2 training was performed using 10M samples with 128 TPUs and took over 11 days to converge (7 days of initial training and 4 days for fine-tuning). Such a long training time slows the iterative speed of research.
Comparatively, the training process of OpenFold using 128 NVIDIA A100 GPUs takes over 8 days, 27% faster than AlphaFold2 but with plenty of room for improvement.
OpenFold’s initial training phase was chosen for addition to the MLCommons MLPerf HPC v3.0 AI benchmark suite in early 2023. The choice of OpenFold in this benchmark suite highlights its potential as a powerful tool for protein structure prediction and underscores its importance to the high-performance computing (HPC) community.
Identifying bottlenecks for OpenFold training
Generally, large models use multiple nodes and multiple GPUs per node for data-parallel (DP) training. This technique can speed up training, while also presenting challenges in terms of achieving optimal GPU utilization and scalability.
The scalability of distributed parallel training is limited by global batch size, as larger batch sizes lead to reduced accuracy. To address this challenge, FastFold introduced dynamic axial parallelism (DAP) as a solution to improve scalability through model parallelism. DAP splits intermediate activations and associated computations of a single training sample along a non-reductive axis.
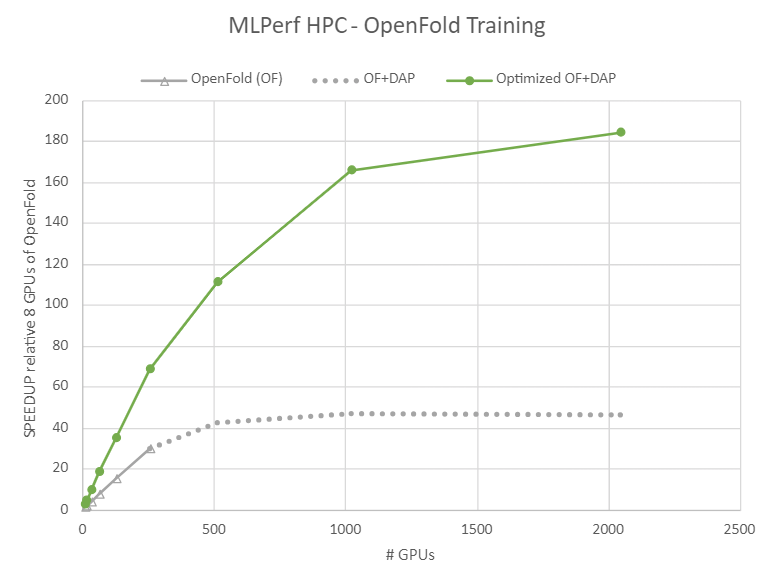
Top rightmost point on “Optimized OF+DAP” data derived from ID 3.0-8009 by dividing the time-to-train by the 8 GPU time-to-train for OpenFold (OF). The MLPerf name and logo are trademarks of the MLCommons Association in the US and other countries. All rights reserved. Unauthorized use is strictly prohibited. For more information, see MLCommons.
In the NVIDIA submission for MLPerf HPC, DAP was re-implemented into OpenFold. The NVIDIA MLPerf HPC Benchmarking team also conducted a comprehensive analysis of the OpenFold training procedure. The analysis showed the major factors that prevented the training from scaling to more compute resources:
- Communication overhead: Communications during the distributed training were intensive yet inefficient, largely due to communication overheads. DAP introduces extra all-gather and all-to-all overhead. On the other hand, during the training process, there is some communication involving small amounts of data, which cannot fully utilize the communication bandwidth.
- Imbalance: Stragglers are a common issue in distributed training. Slow workers that fall behind the rest in completing their assigned tasks slow down the overall training processing. The batch preparation time of OpenFold depends on the original residue sequence length, which introduces imbalance. Background processes occupying training processes’ CPU cores also cause a compute load, which introduces more imbalance.
- Non-parallelizable workloads: Amdahl’s law helps quantify potential parallel speedup gains according to the proportion of a system that can be run in parallel. The dataload stage and structure module stage cannot be processed in parallel by DAP and therefore reduce the parallelizable computational load, further limiting scalability.
- Poor kernel scalability: DAP reduces kernel workload by up to 8x. Small workloads are dominated by starting and finishing tasks and therefore do not saturate GPU bandwidth, which makes kernel scalability worse.
- CPU overhead: There are over 150K operations in OpenFold. Numerous small sequential kernels result in significant PyTorch operation launch overhead.
In Figure 1, the grey data shows OpenFold alone, and a DAP-augmented OpenFold (dotted grey). The maximum number of GPUs providing additional speed is 512 at about 40x the speed of one node with eight GPUs.
Optimizing OpenFold training with NVIDIA GPUs
To address these challenges, the NVIDIA MLPerf HPC Benchmarking team included a collection of systematic optimizations:
- Introduced a novel non-blocking data pipeline to solve the slow-worker issue
- Identified critical computation patterns, such as multi-head attention, layernorm, Stochastic Weight Averaging (SWA), and gradient clipping in OpenFold training. The team then designed dedicated kernels for each of these patterns, fusing fragmented computations throughout the OpenFold model and carefully tuning the kernel configurations for every workload size and target hardware architecture.
- Added full bfloat16 support and applied CUDA Graph as it minimizes the overhead of launching operations by eliminating the need to interact with the CPU.
Training process for OpenFold
The batch size was set to 128 to train the first 5K steps on 1,056 NVIDIA H100 GPUs with DAP8, with 1,024 GPUs used for training and 32 GPUs for evaluation. In every case, the training metric must exceed 0.8 lDDT-Cα before the first 5K training steps.
The global batch size was switched to 256 (NVIDIA Triton mha kernel disabled) to train the remaining steps on 1,056 NVIDIA H100 GPUs with DAP4 (1,024 GPUs used for training and 32 GPUs for evaluation). The total initial training process took 12 hours.
Alternatively, you could use 2,080 NVIDIA H100 GPUs with DAP8 (2,048 GPUs for training and 32 GPUs for evaluation) to train the remaining steps and the initial training time can be reduced to 10 hours.
Faster protein structures with OpenFold
By combining this with a series of fine-grained optimizations, the overall communication efficiency was largely improved. The scalability issue was successfully addressed and scaled OpenFold training to 2,080 NVIDIA H100 GPUs, whereas prior works only scaled up to 512 NVIDIA A100 GPUs. In the MLPerf HPC v3.0 benchmark, the NVIDIA-optimized OpenFold finished the partial training task in 7.51 minutes, over 6x faster than the benchmark baseline.
In Figure 1, the green data shows the same training using DAP with these optimizations to achieve a 4x increase in scalability out to 2048 GPUs, and a 4.5x increase in speed to just over 180x the speed of one 8-GPU server running generic OpenFold.
Training-optimized OpenFold required 50–60K steps to reach 0.9 lDDT-Cα, which took 12.4 hours with 1,056 NVIDIA H100 GPUs or 10 hours with 2,080 NVIDIA H100 GPUs. This is a significant improvement over the 7 days required by the original AlphaFold2 and a new record compared to prior works.
A generative AI toolkit for life science
We hope this work can benefit the HPC and bioinformatics research community at large, by providing an effective regime to scale the deep learning-based computational methods to solve the protein folding problems.
We also hope the workload profiling and optimization methodologies used in this work can shed light on machine learning system designs and implementations. The optimizations in this work could be applied to other AlphaFold2-like models.
A version of the OpenFold model and the software NVIDIA used to train it will be available soon in NVIDIA BioNeMo and the associated framework, a generative AI platform for drug discovery.
For more information, see the following resources:
- The code associated with the NVIDIA MLCommons submission to MLPerf HPC v3.0
