NVIDIA BioNeMo Framework has been released and is now generally available to download on NGC, enabling researchers to build and deploy generative AI, large language models (LLMs), and foundation models in drug discovery applications.
The BioNeMo platform includes managed services, API endpoints, and training frameworks to simplify, accelerate, and scale generative AI for drug discovery. BioNeMo provides the capability to pre-train or fine-tune state-of-the-art models with end-to-end acceleration at scale. It is available as a fully managed service on NVIDIA DGX Cloud with NVIDIA Base Command platform and also as a downloadable framework for deployment with on-premises infrastructure and a variety of cloud platforms.
This provides drug discovery researchers and developers with a fast and easy way to build and integrate state-of-the-art AI applications across the entire drug discovery pipeline, from target identification to lead optimization.
BioNeMo Framework v1.0 features
- Easy data loading with automatic downloaders, pre-processed data, and support for common biomolecular data formats.
- SOTA domain-specific models, including out-of-the-box architectures and validated checkpoints for training on protein and small molecule data.
- Optimized scaling recipes for seamless accelerated training on 1,000s of GPUs, optimized to maximize throughput and reduce cost.
- Flexible training workflows to enable easy large-scale pre-training from scratch, fine-tuning from reliable checkpoints, and downstream task training at speed.
- Validation-in-the-loop, with periodic supervised task training to measure the quality of embeddings as the model trains. Fully automated and integrated with Weights and Biases.
Optimized training for protein and small molecule models
NVIDIA BioNeMo provides optimizations for generative AI models across multiple domains. BioNeMo Framework v1.0 delivers optimized model architectures and tooling for training protein and small molecule LLMs:
- BioNeMo ESM1 and ESM2
- BioNeMo MegaMolBART
- BioNeMo ProtT5
BioNeMo ESM1 and ESM2
The ESM model family is a collection of transformer-based, protein language models built on the BERT architecture and produced by the Meta Fundamental AI Research Protein Team (FAIR).
The general-purpose ESM-like architectures are optimized and available now in BioNeMo Framework and can be leveraged for custom training of protein LLMs. These models are trained on massive datasets of protein sequences to learn the underlying patterns and relationships between amino acids that govern protein structure and function.
Importantly, trained ESM models can be harnessed for a variety of downstream tasks through transfer learning. For instance, you can use the embeddings from its encoder to train a smaller model with a supervised learning objective to infer the properties of proteins. This has been shown to produce highly accurate models for a variety of tasks such as 3D structure prediction, variant effect prediction, or designing de novo proteins.
BioNeMo Framework includes validated training checkpoints for ESM-2 650 million– and 3B-parameter models, enabling a zero-shot start to create custom, domain-specific applications. A number of example downstream tasks, including secondary structure prediction, subcellular localization prediction, and thermal stability prediction are also provided.
BioNeMo MegaMolBART
The MegaMolBART model is a generative chemistry model built using the seq2seq transformer BART architecture, and inspired by the Chemformer model developed by AstraZeneca. MegaMolBART was trained on the ZINC-15 database of small molecule SMILES strings, using 1.5B molecules for training in total.
The embeddings from its encoder can be used for downstream predictive models, much in the same way as ESM or the encoder and decoder can be used together for novel molecule generation by sampling the embedding space. This means MegaMolBART can be used for a variety of cheminformatics drug discovery tasks, such as reaction prediction, molecular optimization, and de novo molecular generation.
MegaMolBART was developed using BioNeMo Framework, which includes a trained and validated checkpoint for a 45M parameter model. Downstream task workflows are also provided for the prediction of retrosynthetic reactions and physicochemical properties, such as lipophilicity, aqueous solubility (ESOL), and hydration-free energy (FreeSolv).
BioNeMo ProtT5
ProtT5 is a protein language model built on an encoder/decoder LLM, developed by the Rost Lab using the T5 architecture. Like the ESM models, ProtT5 can produce embeddings from its encoder for representation learning but it can also use the entire encoder/decoder architecture for sequence translation tasks.
As with others, the base model can be extended for downstream tasks such as generating protein sequences. A recent example of this was the extension of the model by startup Evozyne to create two proteins. The proteins have significant potential in healthcare (aiming to cure a congenital disease) and also in clean energy (designed to consume carbon dioxide to reduce global warming).
Optimized as part of BioNeMo Framework, the ProtT5 model includes a trained and validated checkpoint for a 192M parameter model and a sample downstream task workflow for secondary structure prediction.
Speed and scale with BioNeMo Framework
BioNeMo Framework uses a variety of techniques to achieve higher throughput and improved scalability, including parallelism:
- Model pipeline parallelism: The layers of a model are distributed for parallel training.
- Model tensor parallelism: The layers are themselves sliced and distributed.
Specifying optimizations like precision can also confer huge performance benefits, often with little to no effect on model accuracy.
BioNeMo Framework includes best practices for selecting and tuning hyperparameters of the models, with the ability to easily configure many of these options for maximum performance. One example would be applying techniques such as model tensor parallelism to models over 1B parameters in size and model pipeline parallelism for models over 5B parameters.
Scaling ESM2 training across H100 GPUs with BioNeMo Framework
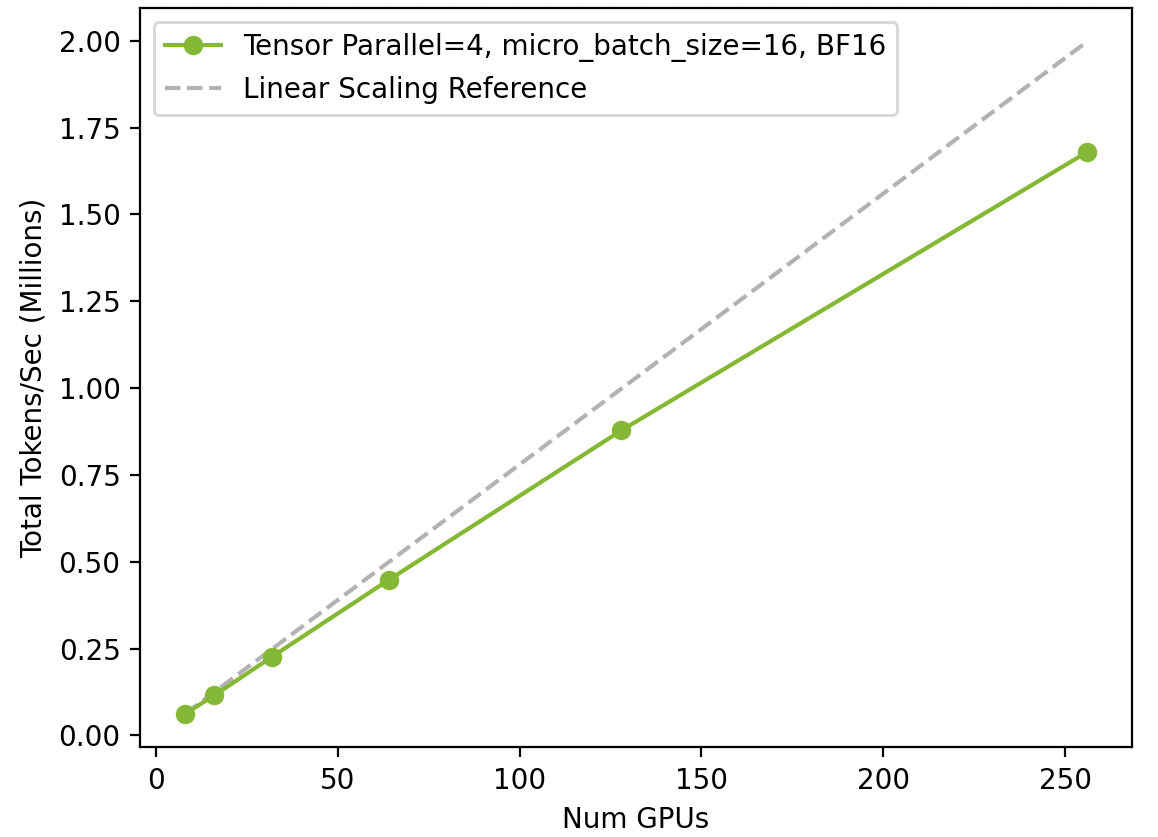
Figure 1 shows scaling from a single DGX node (eight H100 GPUs) to 32 DGX nodes (256 H100 GPUs), and the resultant increase in throughput (tokens per second).
The full-stack optimizations afforded by BioNeMo Framework and the latest NVIDIA GPUs enable training state-of-the-art models at a much-improved speed and efficiency.
As an example, ESM2 was trained as part of its original publication in 8 days for a 650M parameter model, and 30 days for a 3B parameter model, on 512 V100 GPUs. Training these same models with BioNeMo Framework and on 512 H100 GPUs (trained on 1T tokens, or 1.19B protein sequences) can now be achieved in just 1.2 days and 3.5 days respectively.
This provides the opportunity to train even larger models in shorter time frames. For example, an ESM2 model of 20B parameters can be trained on 1T tokens in just 18.6 days with BioNeMo Framework and 512 H100 GPUs.
Training larger ESM2 models in less time
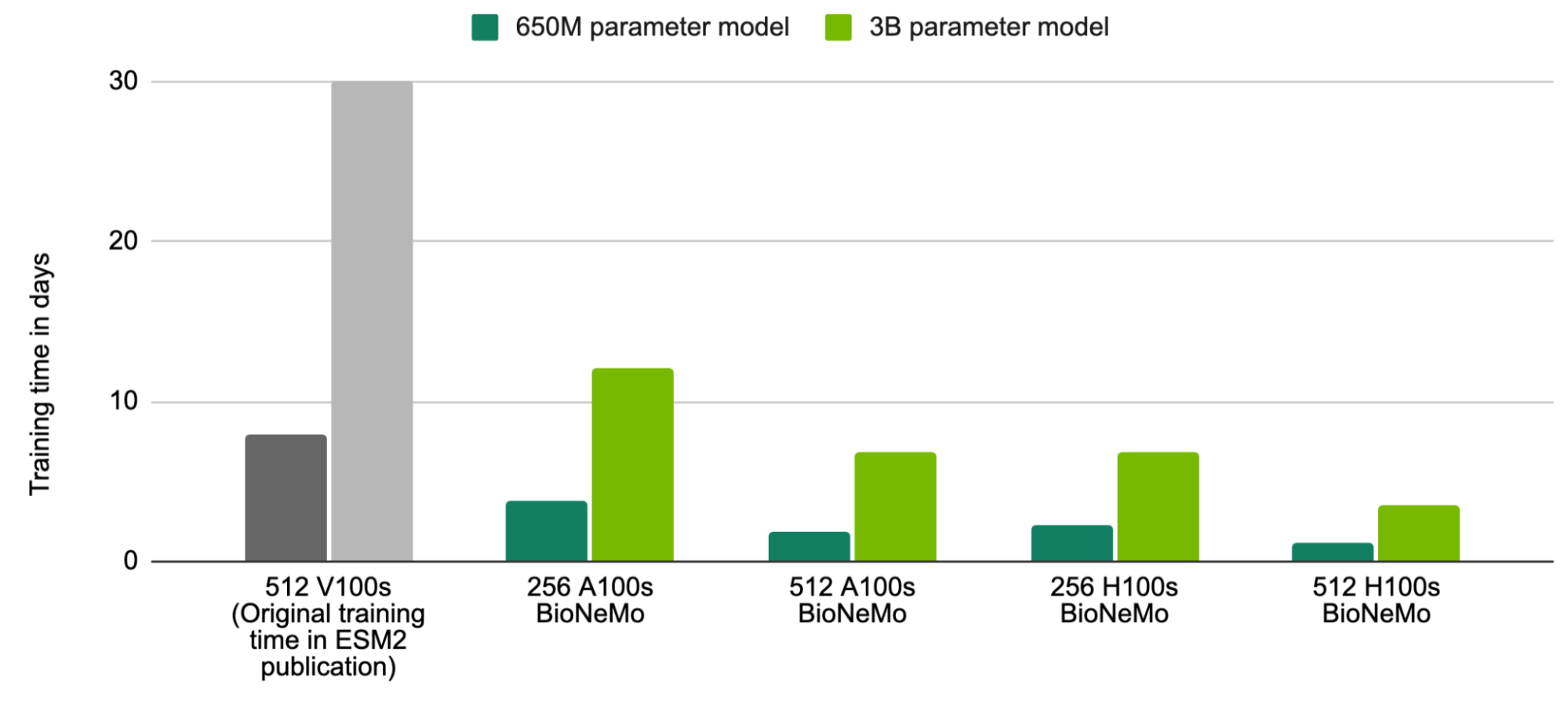
The original published model training time (512 V100s) is shown for reference in gray in the first column. Models trained with BioNeMo were trained on 1T tokens, equivalent to 1.19B protein sequences.
BioNeMo workflow
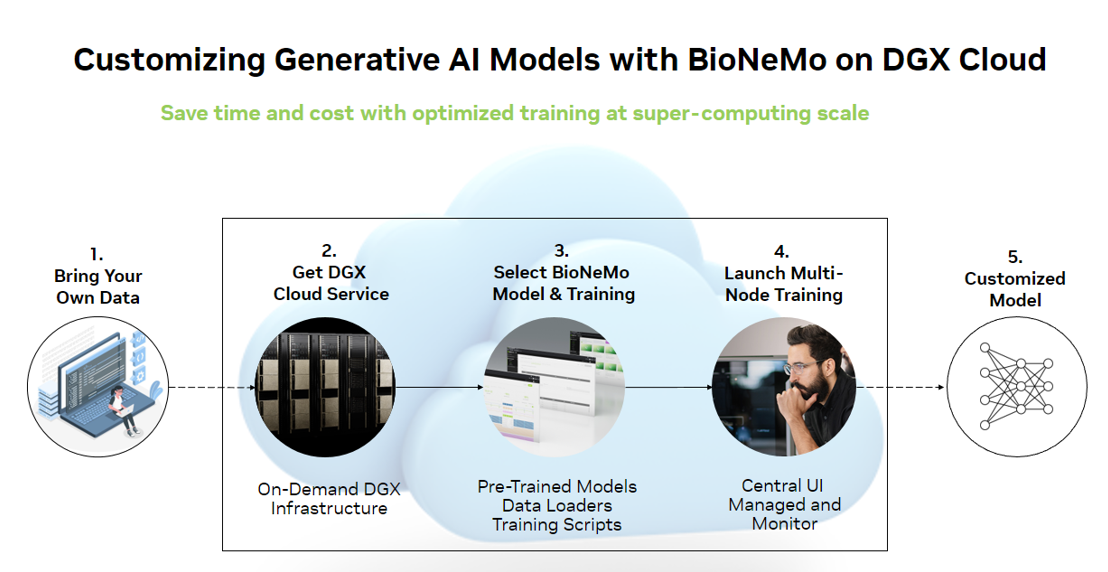
Getting started with BioNeMo Framework
BioNeMo Framework v1.0 is available now on NGC. For more information about access, the latest technical posts, and talks on AI for drug discovery, see the BioNeMo Get Started and Resources pages.
BioNeMo Framework is best deployed on NVIDIA DGX Cloud, which provides on-demand DGX infrastructure for optimal throughput performance. This provides a full-stack AI-training-as-a-service solution for enterprise-grade AI computing in the cloud and direct access to NVIDIA AI experts. For more information, see the DGX Cloud page.
