
Generative AI is unlocking new computing applications that greatly augment human capability, enabled by continued model innovation. Generative AI models—including large language models (LLMs)—are used for crafting marketing copy, writing computer code, rendering detailed images, composing music, generating videos, and more. The amount of compute required by the latest models is immense and continues to grow as new models are invented.
The computational intensity of generative AI inference demands excellence across chips, systems, and software. MLPerf Inference is a benchmark suite that measures inference performance across several popular deep-learning use cases. The latest version of the benchmark suite–MLPerf Inference v4.0–adds two new workloads that represent popular and modern generative AI use cases. The first is an LLM benchmark based on the largest of the Meta Llama 2 family of large language models (LLMs), Llama 2 70B. The second is a text-to-image test based on Stable Diffusion XL.
The NVIDIA accelerated computing platform set performance records on both the new workloads using the NVIDIA H200 Tensor Core GPU. And, using NVIDIA TensorRT-LLM software, the NVIDIA H100 Tensor Core GPU nearly tripled performance on the GPT-J LLM test. NVIDIA Hopper architecture GPUs continue to deliver the highest performance per accelerator across all MLPerf Inference workloads in the data center category. Additionally, NVIDIA also made several submissions in the open division of MLPerf Inference, showcasing its model and algorithm innovations.
In this post, we provide a look at some of the many full-stack technologies behind these record-setting generative AI inference performance achievements.
TensorRT-LLM nearly triples LLM inference performance
LLM-based services, such as chatbots, must deliver fast responses to user queries and be cost-effective, which requires high inference throughput. Production inference solutions must be able to serve cutting-edge LLMs with both low latency and high throughput, simultaneously.
TensorRT-LLM is a high-performance, open-source software library providing state-of-the-art performance when running the latest LLMs on NVIDIA GPUs.
MLPerf Inference v4.0 includes two LLM tests. The first is GPT-J, which was introduced in the prior round of MLPerf, and the second is the newly added Llama 2 70B benchmark. H100 Tensor Core GPUs using TensorRT-LLM achieved speedups on GPT-J of 2.4x and 2.9x in the offline and server scenarios, respectively. Compared to submissions in the prior round. TensorRT-LLM was also central to the NVIDIA platform’s exceptional performance on the Llama 2 70B test.
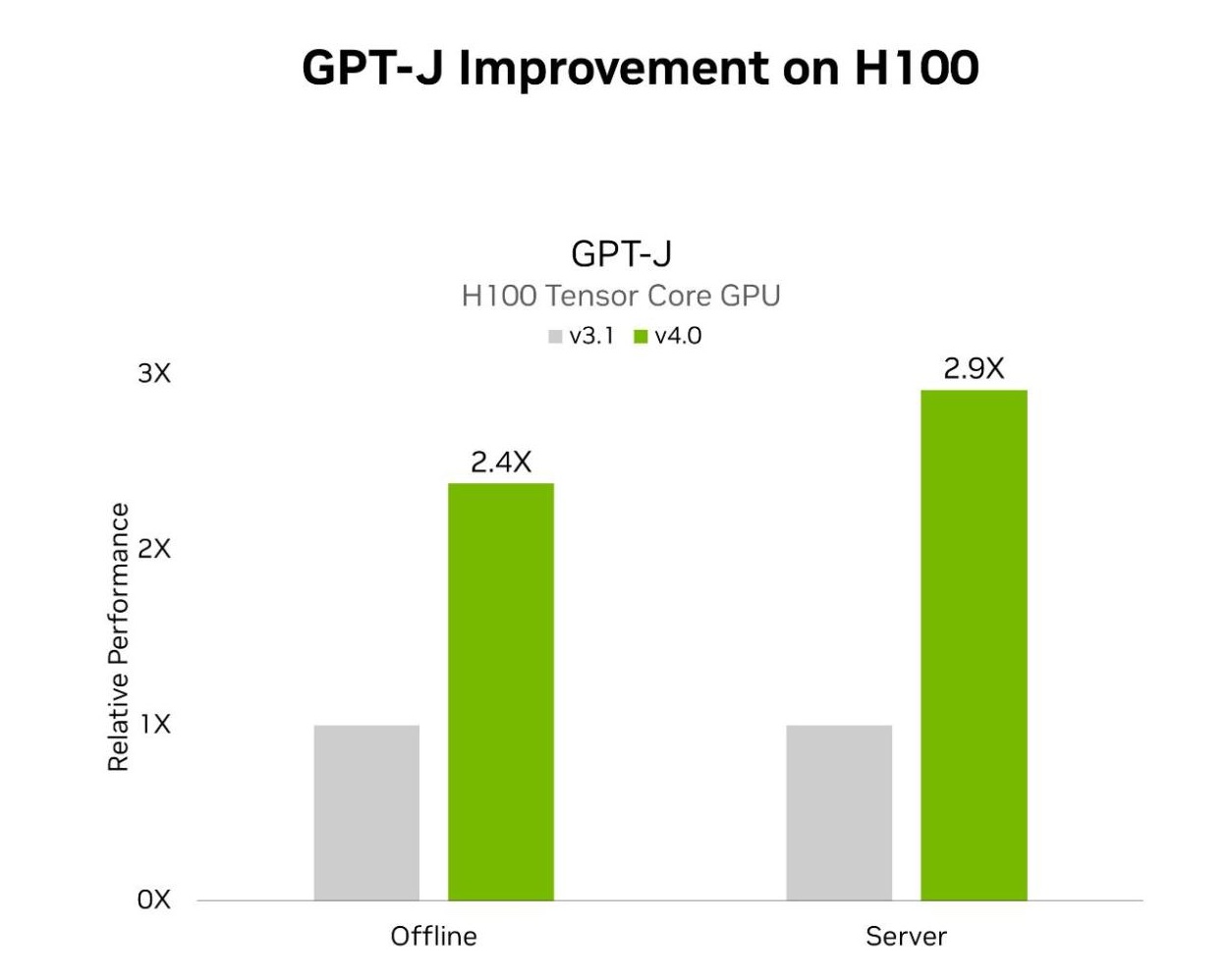
MLPerf Inference v3.1 and v4.0 data center results were retrieved from www.mlperf.org on March 27, 2024 from entries 3.1-0107 and 4.0-0060, respectively. The MLPerf name and logo are registered and unregistered trademarks of the MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
The following are some of the key features of TensorRT-LLM that enabled these great performance results:
- Inflight sequence batching increases GPU use during LLM inference by better interleaving inference requests and evicting requests in a batch as soon as they’ve completed processing and inserting new requests in their place.
- Paged KV cache improves memory consumption and usage by partitioning and storing the KV cache into non-contiguous memory blocks, allocating and evicting blocks on demand, and accessing the blocks dynamically during attention computation.
- Tensor parallelism supports splitting weights across GPUs and nodes using NCCL for communication, enabling efficient inference at scale.
- Quantization supports FP8 quantization, which uses the fourth-generation Tensor Cores in the NVIDIA Hopper architecture to reduce model size and increase performance.
- XQA kernel high-performance implementation of attention that supports MHA, MQA, and GQA, along with beam search, significantly increasing throughput within a given latency budget.
For more details about TensorRT-LLM features, see this post that dives into how TensorRT-LLM boosts LLM inference.
H200 Tensor Core GPUs supercharge LLM inference
The H200, based on Hopper architecture, is the world’s first GPU to use the industry’s most advanced HBM3e memory. H200 incorporates 141 GB of HBM3e with 4.8 TB/s of memory bandwidth, representing nearly 1.8x more GPU memory and 1.4x higher GPU memory bandwidth compared to the H100.
The combination of larger, faster memory, and a new custom thermal solution enabled H200 GPUs to demonstrate large performance improvements on the Llama 2 70B benchmark, compared to H100 submissions this round.
HBM3e enables more performance
The upgraded GPU memory of H200 helps unlock more performance compared to H100 on the Llama 2 70B workload in two important ways.
It removes the need for tensor parallel or pipeline parallel execution for optimal performance in the MLPerf Llama 2 70B benchmark. This reduces communication overhead and improves inference throughput.
Second, the H200 GPU features greater memory bandwidth compared to H100, relieving bottlenecks in memory bandwidth-bound portions of the workload, and enabling improved Tensor Core usage. This yielded greater inference throughput.
Custom cooling designs further boost performance
The extensive optimizations in TensorRT-LLM coupled with upgraded memory of the H200, mean that the Llama 2 70B execution on H200 is compute performance bound rather than limited by memory bandwidth or communication bottlenecks.
As the NVIDIA HGX H200 is drop-in compatible with the NVIDIA HGX H100, it provides system makers with the ability to qualify systems for faster time to market. And, as demonstrated by NVIDIA MLPerf submissions this round, H200 at the same 700 W thermal design power (TDP) as H100 delivers up to 28% better Llama 2 70B inference performance.
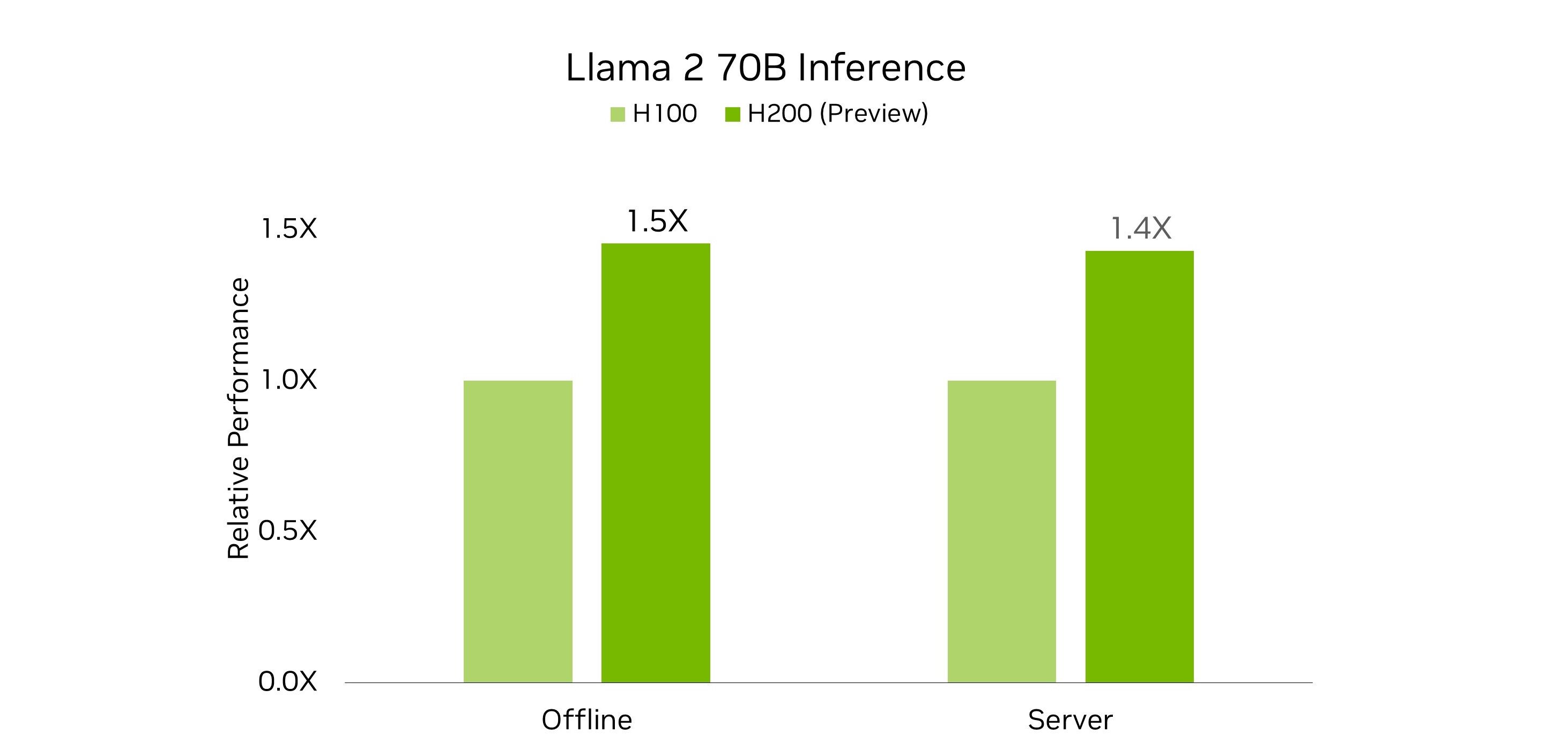
MLPerf Inference v4.0 data center results retrieved from www.mlperf.org on March 27, 2024 from entries 4.0-0062 and 4.0-0068. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org. For more information.
With NVIDIA MGX system builders can deliver more value to their customers through custom cooling designs that enable higher GPU thermals. In this round, NVIDIA also made submissions using H200 with a custom thermal design, enabling the GPUs to run at a higher 1,000 W TDP. This unlocked 11% and 14% more performance in the server and offline scenarios, respectively, when running the Llama 2 70B benchmark, enabling total speedups of 43% and 45% compared to H100, respectively.
Setting the bar for Stable Diffusion XL performance
Stable Diffusion XL is a text-to-image generation AI model composed of the following:
- Two CLIP models for converting prompt texts to embeddings.
- A UNet model composed of residual blocks (ResBlocks) and transformers that iteratively denoise the image in lower resolution latent space.
- A variational autoencoder (VAE) that decodes the latent space image to a 1024×1024 resolution RGB image output.
In MLPerf Inference v4.0, Stable Diffusion XL is used for the text-to-image test, generating images based on supplied text prompts.
The NVIDIA GPUs with TensorRT software delivered the highest performance in the MLPerf Inference v4.0 text-to-image test. An 8-GPU NVIDIA HGX H200 system with GPUs configured to a 700W TDP, achieved performance of 13.8 queries/second and 13.7 samples/second in the server and offline scenarios, respectively.
L40S is the highest-performance universal NVIDIA GPU, designed for breakthrough multi-workload performance across AI compute, graphics, and media acceleration. The Stable Diffusion XL submission, using a system equipped with eight L40S GPUs also demonstrated performance of 4.9 queries/second and 5 samples/second in the server and offline scenarios, respectively.

At the heart of NVIDIA submissions was an innovative recipe that partially quantized the ResBlocks and transformers in the UNet to INT8 precision. In the ResBlocks, convolution layers were quantized to INT8 while in the transformers, query key value blocks, and feedforward network linear layers were quantized to INT8. The INT8 absolute max was collected only from the first eight denoising steps (out of a total of 20). SmoothQuant was applied to the activations of the quantized linear layers, overcoming the challenge of quantizing activations to INT8, all while maintaining original accuracy.
Compared to the FP16 baseline–which wasn’t part of NVIDIA MLPerf submissions–this work boosted performance by 20% on H100 GPUs.
Additionally, support for FP8 quantization in TensorRT for diffusion models, which will improve performance and image quality, is coming soon.
Open division innovations
In addition to submitting world-class performance in the closed division of MLPerf Inference, NVIDIA made several submissions in the open division. The open division according to MLCommons is “intended to foster innovation and allows using a different model or retraining.”
In this round, NVIDIA submitted open division results that made use of various model optimization capabilities in TensorRT, such as sparsification, pruning, and caching. These were used on the Llama 2 70B, GPT-J, and Stable Diffusion XL workloads, showcasing great performance while maintaining high accuracy. The following subsections provide an overview of the innovations powering those submissions.
Llama 2 70B with structured sparsity
The NVIDIA open division submission on H100 GPUs showcased inference on a sparsified Llama 2 70B model using the structured sparsity capability of Hopper Tensor Cores. Structured sparsity to all attention and MLP blocks of the model, and the process was done post-training, without requiring any fine-tuning of the model.
This sparse model provides two main benefits. First, the model itself is 37% smaller. The reduction in size enables both the model and the KVCache to fit entirely in the GPU memory of H100, negating the need of tensor parallelism.
Next, using 2:4 sparse GEMM kernels improved compute throughput and made more efficient use of memory bandwidth. Overall throughput in the offline scenario was 33% higher on the same H100 system compared to the NVIDIA closed-division submission. With these speedups, the sparsified model still met the stringent 99.9% accuracy target, set by the MLPerf closed division. The sparsified model generates fewer tokens per sample than the model used in the closed division, leading to shorter responses to queries.
GPT-J with pruning and distillation
In the open division GPT-J submission, a pruned GPT-J model was used. This technique greatly reduced the number of heads and layers in the model, translating into a nearly 40% increase in inference throughput compared to closed division submission when running the model on H100 GPUs. Performance has improved further since NVIDIA results were submitted in this round of MLPerf.
The pruned model was then fine-tuned using knowledge distillation, enabling excellent accuracy of 98.5%.
Stable Diffusion XL with DeepCache
Roughly 90% of the end-to-end processing of the Stable Diffusion XL workload is spent running iterative denoising steps using the UNet. This has a U topology of layers where the latents are first downconverted and then upconverted back to the original resolution.
DeepCache, a technique described in this paper, proposes using two distinct UNet structures. The first is the original UNet–called Deep UNet in our submission implementation. The second is a single-layer UNet, called Shallow UNet or the Shallow UNet, which reuses (or bypasses) intermediate tensors from the most recent Deep UNet, significantly reducing computation.
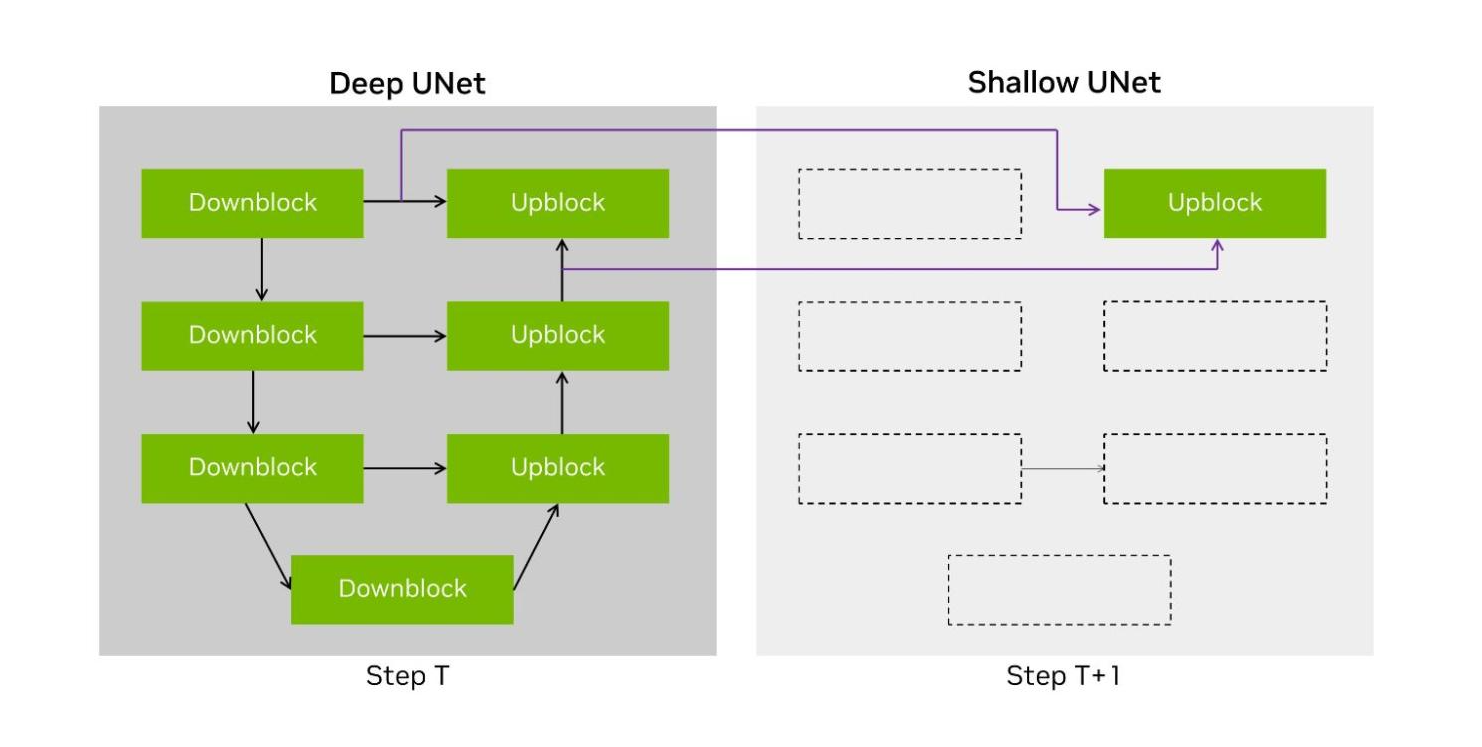
Figure 4. An illustration of the DeepCache technique with both the Deep UNet and Shallow UNet
The NVIDIA open division submission implements a variation of DeepCache where we cache both inputs to the last upconversion layer and alternate between the Deep UNet and the Shallow UNet across denoising steps. This halved the compute required for running the UNet portions of the model, accelerating end-to-end performance by 74% on H100.
Unmatched inference performance
The NVIDIA platform demonstrated exceptional inference performance across the full breadth of MLPerf Inference v4.0 benchmarks, with the Hopper architecture enabling the highest performance per GPU on every workload.
Using TensorRT-LLM software enabled outstanding performance gains for H100 on the GPT-J workload, nearly tripling performance in just 6 months. And H200, the world’s first HBM3e GPU, with TensorRT-LLM software delivered record-setting inference performance on the Llama 2 70B workload in both offline and server scenarios. And, in the debut Stable Diffusion XL test for text-to-image generative AI, the NVIDIA platform delivered the highest performance.
To reproduce the incredible performance demonstrated in NVIDIA MLPerf Inference v4.0 submissions, see the MLPerf repository.
