
NVIDIA is collaborating as a launch partner with Google in delivering Gemma, a newly optimized family of open models built from the same research and technology used to create the Gemini models. An optimized release with TensorRT-LLM enables users to develop with LLMs using only a desktop with an NVIDIA RTX GPU.
Created by Google DeepMind, Gemma 2B and Gemma 7B—the first models in the series—drive high throughput and state-of-the-art performance. Accelerated by TensorRT-LLM, an open-source library for optimizing inference performance, Gemma is compatible across NVIDIA AI platforms—from the data center and cloud to local PCs.
Previously, LLMs have been prohibitively complex to optimize and deploy. Using the TensorRT-LLM simplified Python API makes quantization and kernel compression easy. Python developers can customize model parameters, reduce memory footprint, increase throughput, and improve inference latency, for the most popular LLMs. The Gemma models use a vocabulary size of 256K and support a context length of up to 8K.
Safety is built into the Gemma models through extensive data curation and safety-oriented training methodologies. Personally identifiable information (PII) filtering removes identifiers (such as social security numbers) from the pretraining and instruction-tuning datasets. Additionally, extensive fine-tuning and reinforcement learning from human feedback (RLHF) aligns instruction-tuned models with responsible behaviors.
Trained on over six trillion tokens, developers can confidently build and deploy high-performance, responsible, and advanced AI applications.
TensorRT-LLM makes Gemma models faster
TensorRT-LLM has numerous optimizations and kernels that improve inference throughput and latency. Three features unique to TensorRT-LLM that boost the performance of Gemma are FP8, XQA, and INT4 Activation-aware weight quantization (INT4 AWQ).
FP8 is a natural progression for accelerating deep learning applications beyond 16-bit formats common in modern processors. FP8 enables higher throughput of matrix multiplication and memory transfers without sacrificing accuracy. It helps both small batch sizes in memory bandwidth-limited models and large batch sizes when computing density and memory capacity are crucial.
TensorRT-LLM also offers FP8 quantization for the KV cache. KV cache differs from normal activation occupying non-negligible persistent memory under large batch sizes or long context lengths. Switching to FP8 KV cache enables running 2-3x larger batch sizes with increasing performance.
XQA is a kernel that supports both group query attention and multi-query attention. A new NVIDIA AI-developed kernel, XQA provides optimizations during the generation phases and optimizes beam search. NVIDIA GPUs reduce the data loading and conversion times, providing increased throughput within the same latency budget.
INT4 AWQ is also supported by TensorRT-LLM. AWQ provides superior performance with small (<= 4) batch-size workloads. It reduces a network’s memory footprint and significantly increases performance in memory bandwidth-limited applications. AWQ is a low-bit weight-only quantization method that reduces quantization errors. It protects salient weights by leveraging activations.
By combining the strengths of INT4 and AWQ, the TensorRT-LLM custom kernel for INT4 AWQ compresses the weights of an LLM down to four bits based on their relative importance and performs the computation in FP16. This helps provide higher accuracy than other four-bit methods while reducing memory footprint and providing significant speedups.
Real-time performance with over 79K tokens per second
TensorRT-LLM with NVIDIA H200 Tensor Core GPUs deliver exceptional performance on both the Gemma 2B and Gemma 7B models. A single H200 GPU delivers more than 79,000 tokens per second on the Gemma 2B model, and nearly 19,000 tokens per second on the larger Gemma 7B model.
Putting this performance into context, the Gemma 2B model with TensorRT-LLM, deployed on just one H200 GPU can serve over 3,000 concurrent users, all with real-time latency.
Get started now
Experience Gemma directly from your browser on the NVIDIA AI playground. Coming soon, you can also experience Gemma on the NVIDIA Chat with RTX demo app.
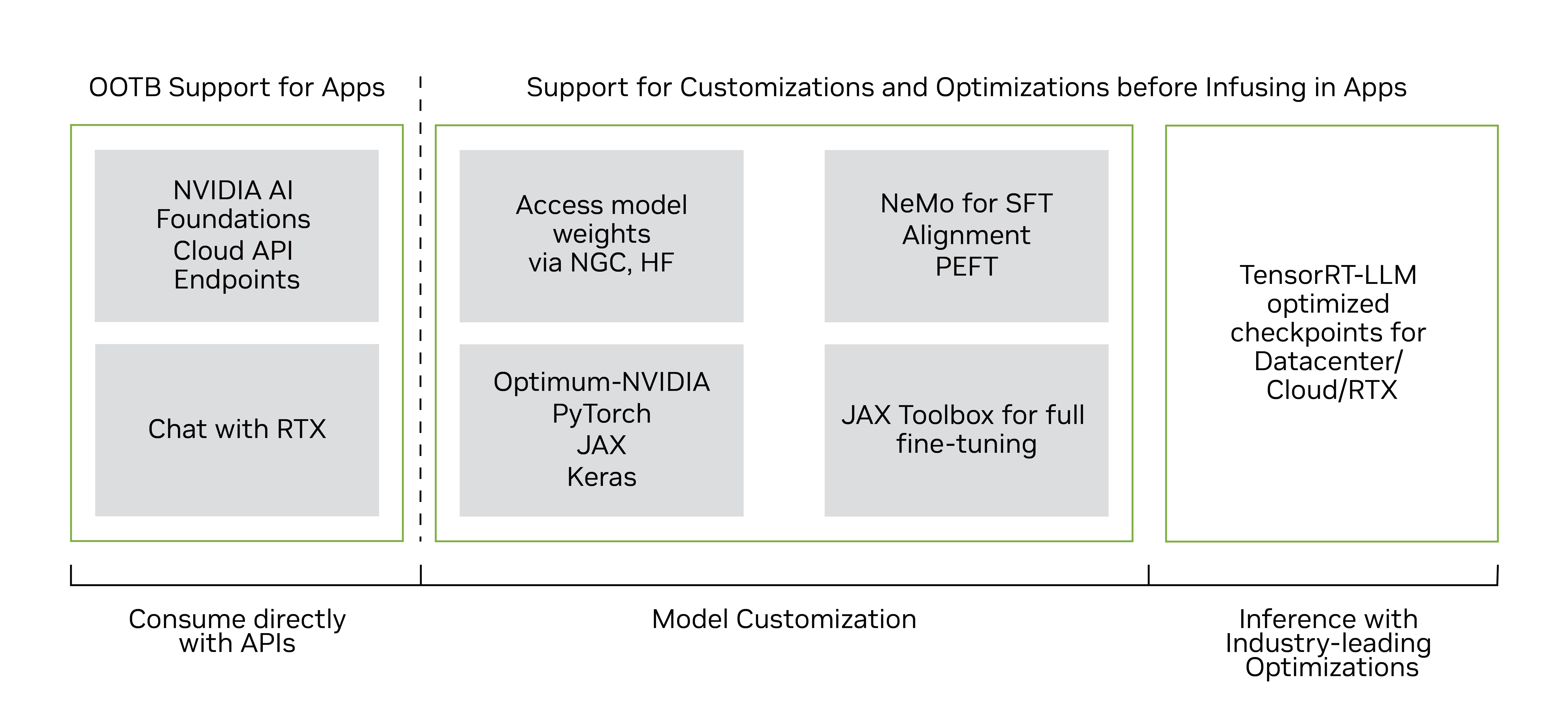
Several TensorRT-LLM optimized Gemma-2B and Gemma-7B model checkpoints, including pre-trained and instruction-tuned versions, are now available on NGC for running the optimized model on NVIDIA GPUs, including consumer-grade RTX systems.
Coming soon, you can experience the TensorRT-LLM optimized FP8 quantized version of the model in the Optimum-NVIDIA library on Hugging Face. Integrate fast LLM inference with just one line of code.
Developers can use the NVIDIA NeMo framework to customize and deploy Gemma in production environments. The NeMo framework includes popular customization techniques like supervised fine-tuning, parameter-efficient fine-tuning with LoRA, and RLHF. It also supports 3D parallelism for training. Review the notebook to start coding with Gemma and NeMo.
Get started customizing Gemma with the NeMo framework today.
