
The rapid growth in the size, complexity, and diversity of large language models (LLMs) continues to drive an insatiable need for AI training performance. Delivering top performance requires the ability to train models at the scale of an entire data center efficiently. This is achieved through exceptional craftsmanship at every layer of the technology stack, spanning chips, systems, and software.
The NVIDIA NeMo framework, part of the NVIDIA NeMo software suite for managing the AI agent lifecycle, is an end-to-end, cloud-native framework for building, customizing, and deploying generative AI models. It incorporates a full array of advanced parallelism techniques to enable efficient training of LLMs at scale.
In fact, NeMo powered the exceptional GPT-3 175B performance submissions by NVIDIA in the latest MLPerf Training industry-standard benchmarks, achieving up to 797 TFLOPS per H100 GPU. And, in the largest scale submitted by NVIDIA, record performance and near-linear performance scaling were achieved using an unprecedented 10,752 H100 Tensor Core GPUs.
Today, NVIDIA is announcing that the upcoming January release of the NeMo framework incorporates a host of optimizations and new features. These dramatically improve performance on NVIDIA AI Foundation Models, including Llama 2, Nemotron-3, and other LLMs, and expand NeMo model architecture support. It also provides a much-requested parallelism technique, making it even easier to train various models on the NVIDIA AI platform.
Up to 4.2x faster Llama 2 70B pre-training and supervised fine-tuning
Llama 2 is a popular, open-source large language model originally developed by Meta. The upcoming release of NeMo includes many improvements that increase Llama 2 performance. Compared to the prior NeMo release running on A100 GPUs, the upcoming NeMo release running on H200 GPUs delivers up to 4.2x faster Llama 2 pre-training and supervised fine-tuning performance.
The first improvement is the addition of mixed-precision implementations of the model optimizer’s state. This reduces model capacity requirements and improves the effective memory bandwidth for operations that interact with the model state by 1.8x.
The performance of rotary positional embedding (RoPE) operations—state-of-the-art algorithms employed by many recent LLM architectures—has also increased. Additionally, the performance of Swish-Gated Linear Unit (SwiGLU) activation functions is optimized, which commonly substitutes Gaussian Error Linear Unit (GELU) in modern LLMs.
Finally, the communication efficiency for tensor parallelism has been greatly improved, and communication chunk sizes for pipeline parallelism have been tuned.
Collectively, these improvements dramatically increase Tensor Core usage on GPUs based on the NVIDIA Hopper architecture, achieving up to 836 TFLOPS per H200 GPU for Llama 2 70B pre-training and supervised fine-tuning.
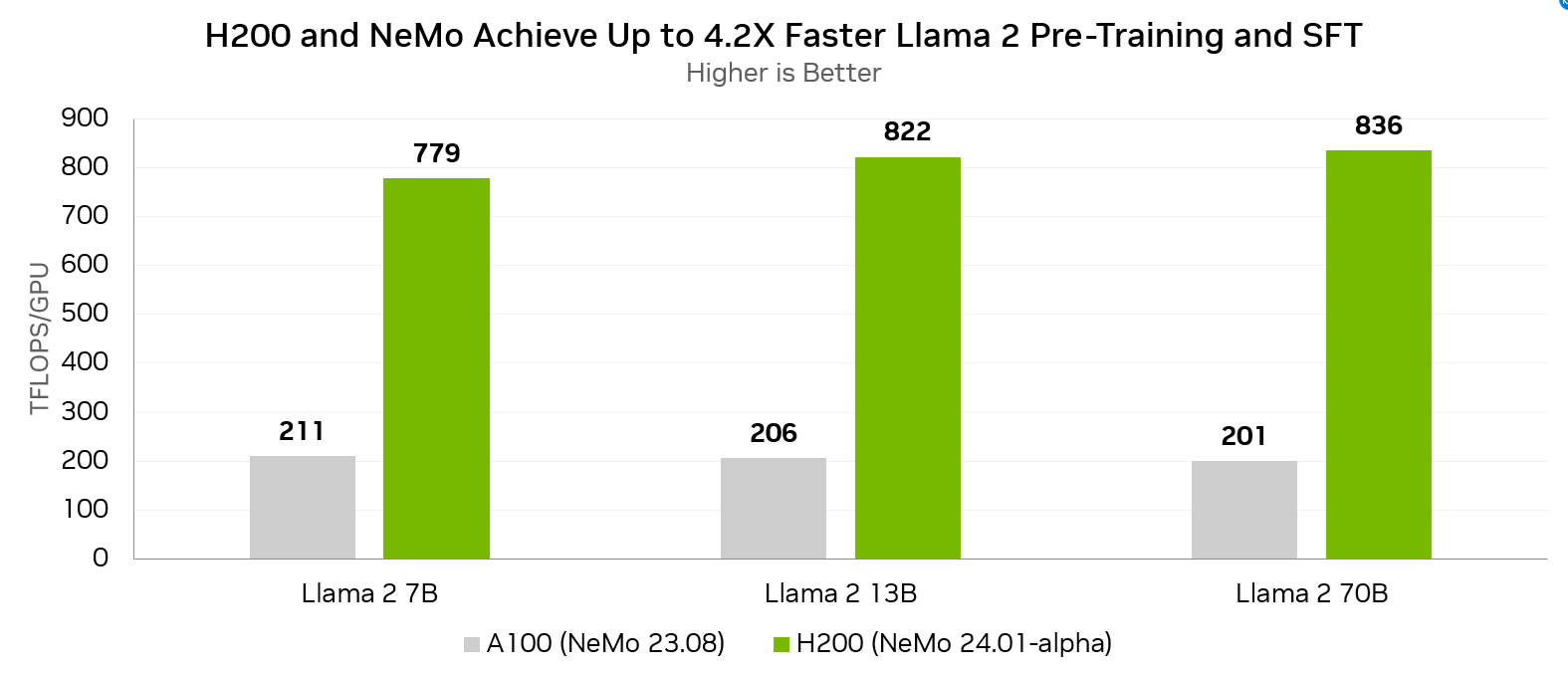
Measured performance per GPU. Global Batch Size = 128.
Llama 2 7B: Sequence Length 4096 | A100 8x GPU, NeMo 23.08 | H200 8x GPU, NeMo 24.01-alpha
Llama 2 13B: Sequence Length 4096 | A100 8x GPU, NeMo 23.08 | H200 8x GPU, NeMo 24.01-alpha
Llama 2 70B: Sequence Length 4096 | A100 32x GPU, NeMo 23.08 | H200 8x GPU, NeMo 24.01-alpha
H200 GPUs, coupled with the upcoming version of NeMo, can achieve exceptional Llama 2 training throughput, delivering up to a 4.2x uplift compared to A100 GPUs running the prior NeMo release.
| Training Tokens/Sec/GPU | Llama 2 7B | Llama 2 13B | Llama 2 70B |
|---|---|---|---|
| H200 (Latest NeMo) | 16,913 | 9,432 | 1,880 |
| A100 (Prior NeMo) | 4,583 | 2,357 | 451 |
| Speedup | 3.7X | 4.0X | 4.2X |
Measured performance per GPU. Global Batch Size = 128.
Llama 2 7B: Sequence Length 4096 | A100 8x GPU, NeMo 23.08 | H200 8x GPU, NeMo 24.01-alpha
Llama 2 13B: Sequence Length 4096 | A100 8x GPU, NeMo 23.08 | H200 8x GPU, NeMo 24.01-alpha
Llama 2 70B: Sequence Length 4096 | A100 32x GPU, NeMo 23.08 | H200 8x GPU, NeMo 24.01-alpha
Putting this performance into context, a single system based on the eight-way NVIDIA HGX H200 can fine-tune Llama 2 with 70B parameters on sequences of length 4096 at a rate of over 15,000 tokens/second. This means that it can complete a supervised fine-tuning task consisting of 1B tokens in just over 18 hours.
Fully Sharded Data Parallelism
Fully Sharded Data Parallelism (FSDP) is a well-known and popular feature within the deep learning community. It is used by deep learning practitioners across major frameworks, including PyTorch, DeepSpeed, and JAX, and is applied to a wide variety of models.
FSDP can be applied to a wide variety of models, and is particularly useful for LLMs, as the compute and memory requirements of modern LLMs are well beyond the scope of even a single, advanced GPU.
Pipelining a model is an effective performance optimization. But it requires that a model has a very regular structure (for example, the same layer repeated 128 times) because different layers are distributed to different GPUs and data flows between them in a pipelined manner.
FSDP provides developers with improved usability and minimal performance loss across various situations. This is because the data and memory of a model are distributed on a per-layer basis, which makes it easier to manage regular or irregular neural network structures.
A natural extension of data parallelism, FSDP can often be used through simple model wrappers, without needing to consider how a model is partitioned (as is the case in pipeline parallelism). This also makes it easier to extend FSDP to new and emerging model architectures, such as multi-modal LLMs.
FSDP can also achieve performance competitive with traditional combinations of tensor parallelism and pipeline parallelism methods when there is sufficient parallelism at scales smaller than the global batch size.
| GPT-20B Training Performance (BF16) | |||||
| # of H100 GPUs | 8 | 16 | 32 | 64 | 128 |
| FSDP | 0.78x | 0.88x | 0.89x | 0.86x | 0.96x |
| 3D Parallelism | 1.0x | 1.0x | 1.0x | 1.0x | 1.0x |
Measured performance. Global Batch Size = 256, Sequence Length = 2048
Mixture of Experts
One proven method of improving the information absorption and generalization capabilities of generative AI models is to increase the number of parameters in the model. However, a challenge that emerges with larger models is that as their capacity increases, the compute required to perform inference also grows, increasing the cost to run the models in production.
Recently, a mechanism called Mixture of Experts (MoE) has gained significant attention. It enables model capacity to be increased without a proportional increase in both the training and inference compute requirements. MoE architectures achieve this through a conditional computation approach where each input token is routed to only one or a few expert neural network layers instead of being routed through all of them. This decouples model capacity from required compute.
The upcoming release of NeMo introduces official support for MoE-based LLM architectures with expert parallelism. This implementation uses an architecture similar to that of Balanced Assignment of Experts (BASE) where each MoE layer routes each token to exactly one expert and uses algorithmic load balancing. NeMo uses Sinkhorn-based routing to balance the token load across the various experts.
MoE models based on NeMo support expert parallelism, which can be used in combination with data parallelism to distribute MoE experts across data parallel ranks. NeMo also provides the ability to configure expert parallelism arbitrarily. Users can map experts to different GPUs in various ways without restricting the number of experts on a single device (all devices, however, must contain the same number of experts). NeMo also supports cases where the expert parallel size is less than the data parallel size.
Developers can use the NeMo expert parallelism method in combination with the many other parallelism dimensions offered by NeMo including tensor, pipeline, and sequence parallelism. This facilitates efficient training of models with more than a trillion parameters on clusters with many NVIDIA GPUs.
RLHF with TensorRT-LLM
NeMo support for reinforcement learning from human feedback (RLHF) has now been enhanced with the ability to use TensorRT-LLM for inference inside of the RLHF loop.
TensorRT-LLM accelerates the inference stage of the actor model, which currently takes most of the end-to-end compute time. The actor model is the model of interest that is being aligned and will be the ultimate output of the RLHF process.
The upcoming NeMo release enables pipeline parallelism for RLHF through TensorRT-LLM, enabling it to achieve better performance with fewer nodes, all while also supporting larger models.
In fact, for the Llama 2 70B parameter model, using TensorRT-LLM in the RLHF loop with H100 GPUs enables up to a 5.6x performance increase compared to RLHF without TensorRT-LLM in the loop on the same H100 GPUs.
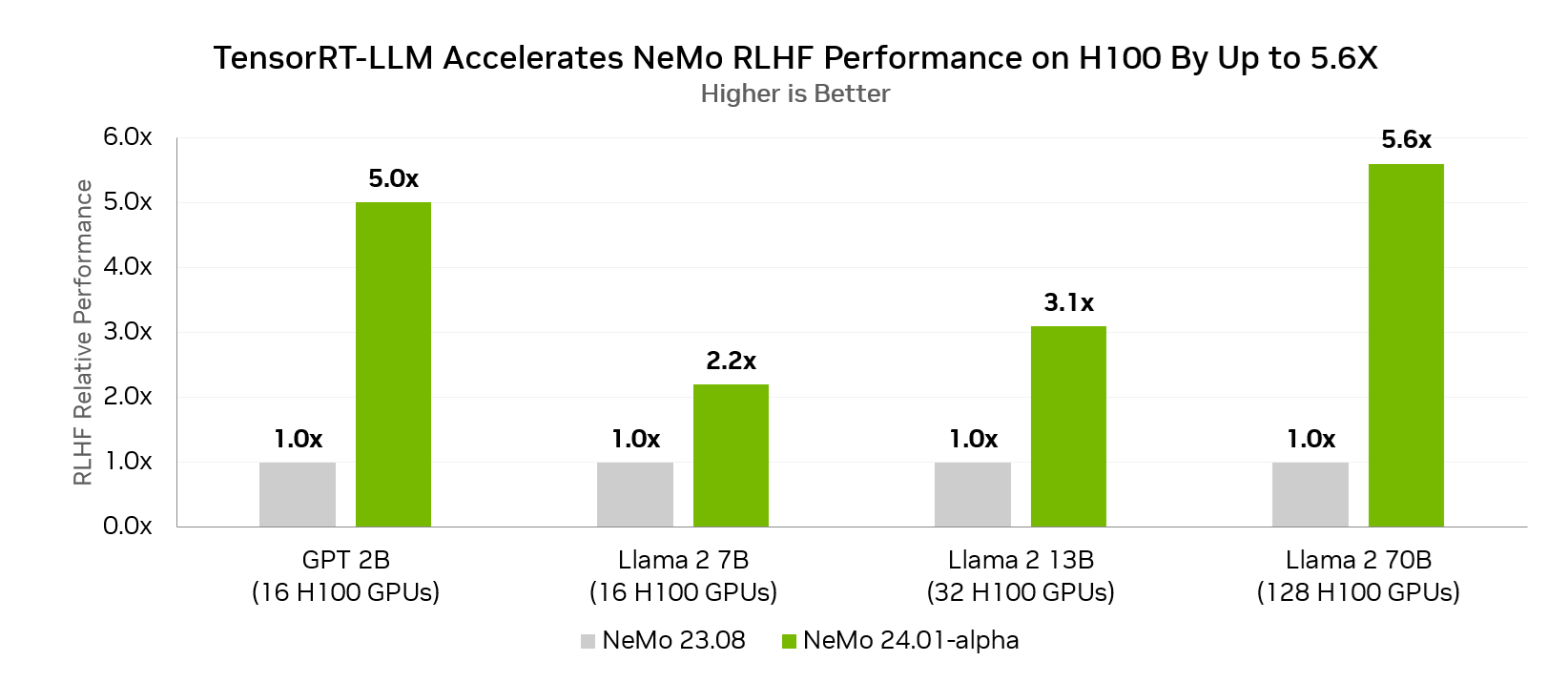
Measured performance. Global Batch Size = 64, Rollout Size = 512, Maximum Generation Length = 1024.
Half of the nodes for each result run the actor and the other half run the critic in the RLHF algorithm implemented.
Pushing the boundaries of generative AI
AI training requires a full-stack approach. NVIDIA NeMo is regularly updated to provide optimal performance for training advanced generative AI models. It incorporates the most recent training methods to improve performance and provide more flexibility for NVIDIA platform users.
The NVIDIA platform is also incredibly versatile and accelerates the entire AI workflow end-to-end, from data prep to model training to deploying inference. Following the introduction of TensorRT-LLM in October, NVIDIA recently demonstrated the ability to run the latest Falcon-180B model on a single H200 GPU, leveraging TensorRT-LLM’s advanced 4-bit quantization feature, while maintaining 99% accuracy. Read more about this implementation in the latest post about TensorRT-LLM.
The NVIDIA AI platform continues to advance performance, versatility, and features at the speed of light. That’s why it is the platform of choice for developing and deploying today’s generative AI applications and inventing the models and techniques that are powering what comes next.
Get started with NeMo framework
The NVIDIA NeMo framework is available as an open-source library on GitHub, a container on NGC, and as part of NVIDIA AI Enterprise, an enterprise-grade AI software platform with security, stability, manageability, and support.
