
This week’s model release features two new NVIDIA AI Foundation models, Mistral Large and Mixtral 8x22B, both developed by Mistral AI. These cutting-edge text-generation AI models are supported by NVIDIA NIM microservices, which provide prebuilt containers powered by NVIDIA inference software that enable developers to reduce deployment times from weeks to minutes. Both models are available through the NVIDIA API catalog.
Mistral Large
Mistral Large is a large language model (LLM) that excels in complex multilingual reasoning tasks, including text understanding, transformation, and code generation. It stands out for its proficiency in English, French, Spanish, German, and Italian, with a deep understanding of grammar and cultural context.
The model features a 32K token context window for precise information recall from extensive documents. It performs well with instruction-following and function-calling. Mistral Large offers strong performance on various benchmarks and demonstrates powerful reasoning capabilities across coding and mathematical challenges.
Mixtral 8x22B
Mixtral 8x22B is a state-of-the-art LLM characterized by its use of a Sparse Mixture of Experts (MoE) architecture. This model is notable for its large size and advanced capabilities that contribute to its ability to understand and generate complex text. This makes the model suitable for a wide range of natural language processing tasks, including chatbots, content generation, and more complex tasks that require a deeper understanding of language.
The model is reported to outperform other models in various benchmarks, showcasing its effectiveness in text generation and understanding. Its architecture enables fast, low-cost inference, making it an attractive option for applications requiring real-time responses for both research and commercial use.
NVIDIA NIM microservices
Mistral Large now joins more than two dozen popular AI models that are supported by NVIDIA NIM microservices, including Mixtral 8x7B, Llama 70B, Stable Video Diffusion, Code Llama 70B, Kosmos-2, and more. NIM is designed to simplify the deployment of performance-optimized NVIDIA AI Foundation models and custom models, enabling 10x to100x more enterprise application developers to contribute to AI transformations.
NIM makes it easy for developers to:
- Deploy anywhere and maintain control of generative AI applications and data.
- Streamline AI application development with industry-standard APIs and tools tailored for enterprise environments.
- Leverage the latest generative AI models, packaged as prebuilt containers, offering a diverse range of options and flexibility.
- Achieve highest performance with industry-leading latency and throughput for cost-effective scaling.
- Get support for custom models out of the box, so models can be trained on domain-specific data.
- Deploy confidently with dedicated feature branches, rigorous validation processes, and robust support structures.
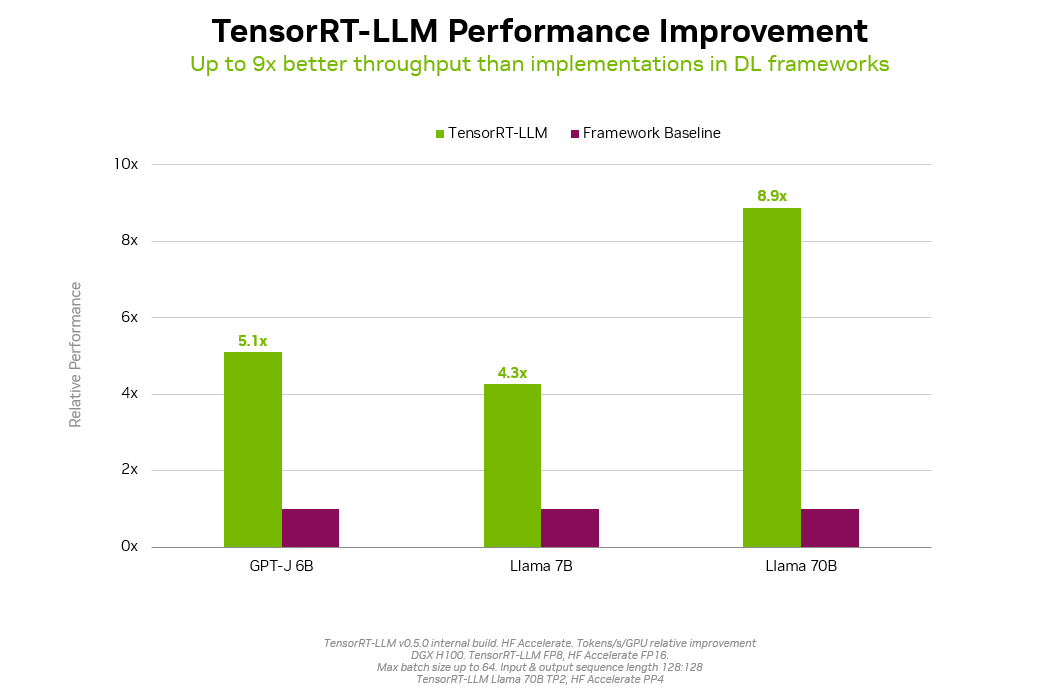
NVIDIA AI Foundation models are optimized by NVIDIA for latency and throughput using NVIDIA TensorRT-LLM. Llama 2 delivers nearly 9x higher inference with TensorRT-LLM, for example.
These models are offered in .nemo format, enabling developers to leverage NVIDIA NeMo to easily take advantage of various customization techniques including SFT, LoRA, RLFH, and SteerLM.
The curated set of foundation models includes LLMs that generate text, code, and language, vision language models (VLMs) that understand visuals and provide grounded information, and models for visual content generation, drug discovery, genomics, climate simulations, and more.
NVIDIA continues to work with foundation model developers to optimize the performance of their models and package them with NIM microservices.
NVIDIA API catalog
NVIDIA API catalog is a collection of performance-optimized API endpoints packaged as enterprise-grade runtime that you can experience from a browser.
With free NVIDIA cloud credits, you can start testing the models at scale. You can also build a proof of concept (POC) by connecting your application on the NVIDIA-hosted API endpoint running on a fully accelerated stack. The APIs are integrated with frameworks like Langchain and LlamaIndex, simplifying enterprise application development.
Deploy the models in minutes with the NIM microservice on-premises, in the cloud, or on your workstation. The flexibility to run anywhere keeps your data secure and private, avoids platform lock-in, and enables you to take advantage of your existing infrastructure investments and cloud commitments.
To get started, visit ai.nvidia.com.
