
In the dynamic realm of generative AI, diffusion models stand out as the most powerful architecture for generating high-quality images with text prompts. Models like Stable Diffusion have revolutionized creative applications.
However, the inference process of diffusion models can be computationally intensive due to the iterative denoising steps required. This presents significant challenges for companies and developers striving to achieve optimal end-to-end inference speed.
Starting with NVIDIA TensorRT 9.2.0, we’ve developed a best-in-class quantization toolkit with improved 8-bit (FP8 or INT8) post-training quantization (PTQ) to significantly speed up diffusion deployment on NVIDIA hardware while preserving image quality. The 8-bit quantization feature of TensorRT has become the go-to solution for many generative AI companies, particularly among leading providers of creative video-editing applications.
In this post, we discuss the performance of TensorRT with Stable Diffusion XL. We introduce the technical differentiators that empower TensorRT to be the go-to choice for low-latency Stable Diffusion inference. Finally, we demonstrate how to use TensorRT to speed up models with a few lines of change.
Benchmarking
NVIDIA TensorRT INT8 and FP8 quantization recipes for diffusion models achieve 1.72x and 1.95x speedups on NVIDIA RTX 6000 Ada GPUs compared to native PyTorch’s torch.compile running in FP16. The additional speedup of FP8 over INT8 is primarily attributed to the quantization of multi-head attention (MHA) layers. Using TensorRT 8-bit quantization enables you to enhance the responsiveness of your generative AI applications and reduce inference costs.
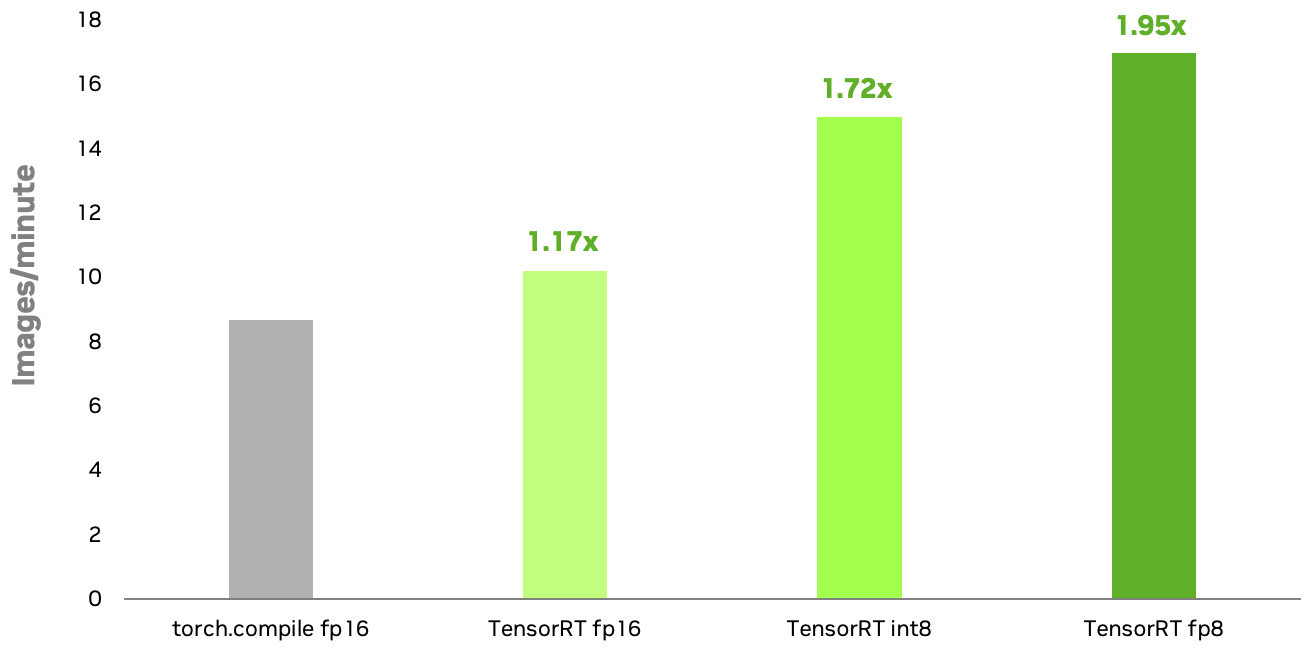
Configuration: Stable Diffusion XL 1.0 base model; images resolution=1024×1024; Batch size=1; Euler scheduler for 50 steps; NVIDIA RTX 6000 Ada GPU. TensorRT INT8 quantization is available now, with FP8 expected soon. The benchmark for TensorRT FP8 may change upon release.
In addition to speeding up inference, TensorRT 8-bit quantization excels at preserving image quality. Through proprietary quantization techniques, it generates images that closely resemble the original FP16 images. We cover these techniques later in this post.

TensorRT Solution: overcoming inference speed challenges
Although PTQ is considered a go-to compression method to reduce memory footprint and speed up inference for many AI tasks, it does not work out-of-the-box on diffusion models. Diffusion models have a unique multi-timestep denoising process and the output distribution of the noise estimation network at each time step can vary significantly. This makes a naive PTQ calibration method not applicable.
In existing techniques, SmoothQuant stands out as a popular PTQ method to enable 8-bit weight, 8-bit activation (W8A8) quantization for LLMs. Its primary innovation lies in its approach to addressing activation outliers by transferring the quantization challenge from activations to weights through a mathematically equivalent transformation.
Despite its effectiveness, users frequently encounter difficulties in manually defining parameters within SmoothQuant. Empirical studies have also revealed that SmoothQuant struggles with adapting to diverse image characteristics, limiting its flexibility and performance in real-world scenarios. Furthermore, other existing diffusion model quantization techniques are only tailored for a single version of the diffusion model, while users are looking for a generic approach that can speed up various versions of models.
To address these challenges, NVIDIA TensorRT developed a sophisticated, fine-grained tuning pipeline to determine the optimal parameter settings for each layer of the model for SmoothQuant. You can develop your own tuning pipeline depending on the specific characteristics of the feature maps. This capability enables TensorRT quantization to result in superior image quality that preserves rich details from original images, compared to existing methods based on customer needs.
The activation distribution can vary significantly across different time steps and the shape and overall style of the images are predominantly determined in the initial stages of the denoising process, based on the findings in Q-Diffusion. Because of that, using the traditional max calibration results in large quantization errors in the initial steps.
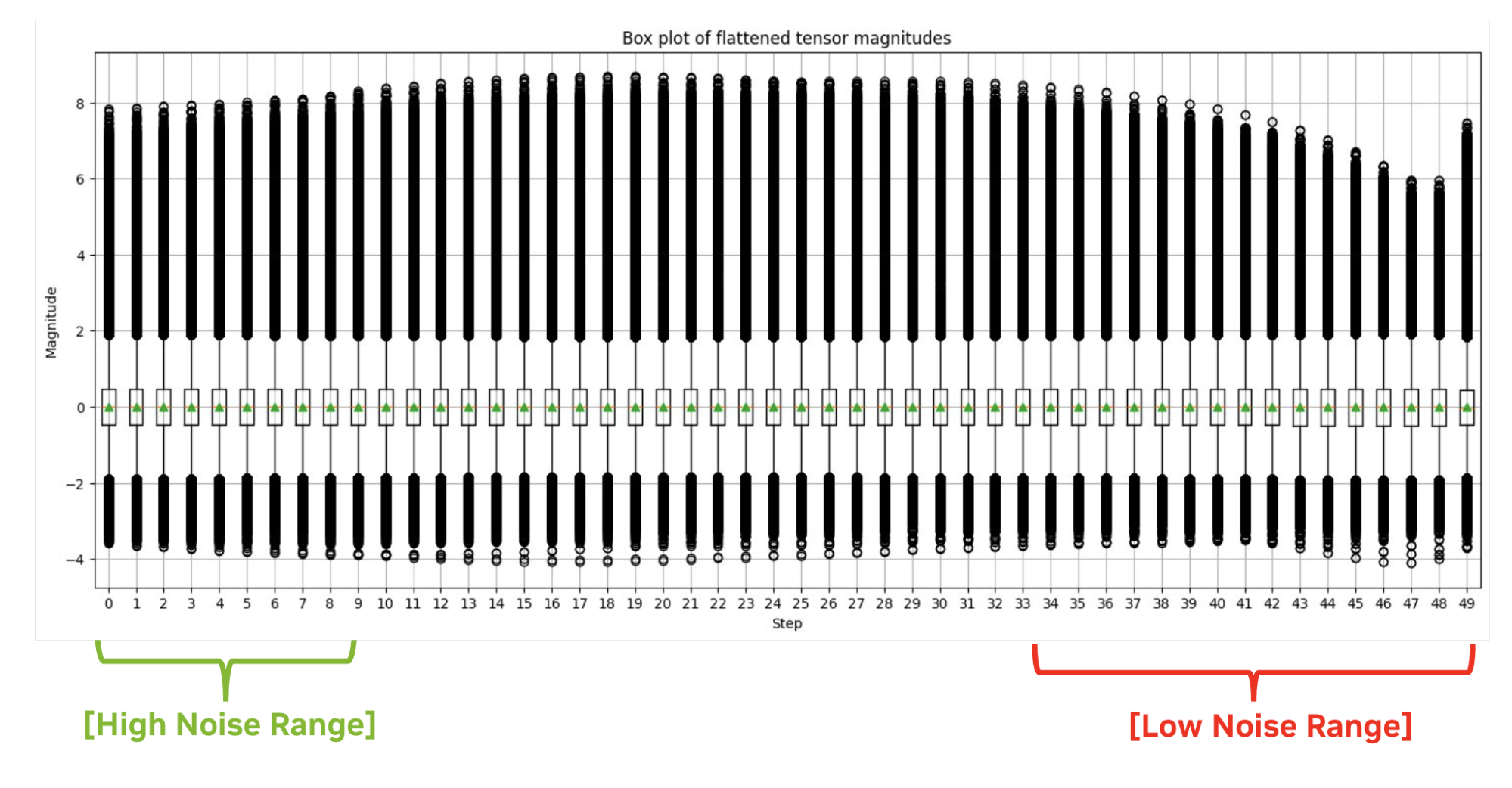
Instead, we selectively used the minimum quantization scaling factors from the selected steps range because we found that outliers in the activation are not that important to the final image quality. This tailored approach, which we named Percentile Quant, focuses on the important percentile of the steps range. It enables TensorRT to generate images that are nearly identical to those produced in the original FP16 precision.

Using TensorRT 8-bit quantization to accelerate diffusion models
The /NVIDIA/TensorRT GitHub repo now hosts an end-to-end, SDXL, 8-bit inference pipeline, providing a ready-to-use solution to achieve optimized inference speed on NVIDIA GPUs.
Run a single command to generate images with Percentile Quant and measure latency with demoDiffusion. In this section, we use INT8 as an example, but the workflow for FP8 is largely identical.
python demo_txt2img_xl.py "enchanted winter forest with soft diffuse light on a snow-filled day" --version xl-1.0 --onnx-dir onnx-sdxl --engine-dir engine-sdxl --int8 --quantization-level 3
Here’s an overview of the main steps involved in this command:
- Calibrating
- Exporting ONNX
- Building the TensorRT engine
Calibrating
Calibration is the step during quantization where the ranges of the target precision are computed. Currently, quantization functionalities in TensorRT are packaged in nvidia-ammo, a dependency that has been included in TensorRT 8-bit quantization examples.
# Load the SDXL-1.0 base model from HuggingFace
import torch
from diffusers import DiffusionPipeline
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
)
base.to("cuda")
# Load calibration prompts:
from utils import load_calib_prompts
cali_prompts = load_calib_prompts(batch_size=2,prompts="./calib_prompts.txt")
# Create the int8 quantization recipe
from utils import get_percentilequant_config
quant_config = get_percentilequant_config(base.unet, quant_level=3.0, percentile=1.0, alpha=0.8)
# Apply the quantization recipe and run calibration
import ammo.torch.quantization as atq
quantized_model = atq.quantize(base.unet, quant_config, forward_loop)
# Save the quantized model
import ammo.torch.opt as ato
ato.save(quantized_model, 'base.unet.int8.pt')
Exporting ONNX
After getting the quantized model checkpoint, you can export the ONNX model.
# Prepare the onnx export
from utils import filter_func, quantize_lvl
base.unet = ato.restore(base.unet, 'base.unet.int8.pt')
quantize_lvl(base.unet, quant_level=3.0)
atq.disable_quantizer(base.unet, filter_func) # `filter_func` is used to exclude layers you don't quantize
# Export the ONNX model
from onnx_utils import ammo_export_sd
base.unet.to(torch.float32).to("cpu")
ammo_export_sd(base, 'onnx_dir', 'stabilityai/stable-diffusion-xl-base-1.0')
Build the TensorRT engine
With the INT8 UNet ONNX model, you can then build the TensorRT engine.
trtexec --onnx=./onnx_dir/unet.onnx --shapes=sample:2x4x128x128,timestep:1,encoder_hidden_states:2x77x2048,text_embeds:2x1280,time_ids:2x6 --fp16 --int8 --builderOptimizationLevel=4 --saveEngine=unetxl.trt.plan
Conclusion
In the era of generative AI, having an inference solution that prioritizes ease of use is paramount. With NVIDIA TensorRT, you can seamlessly achieve up to a 2x acceleration in inference speed through its proprietary 8-bit quantization technique, while ensuring image quality remains uncompromised for exceptional user experiences.
The TensorRT commitment to balancing speed and quality underscores its position as a leading choice for accelerating AI applications, empowering you to deliver cutting-edge solutions with ease.
Register to attend the GTC session on quantization to learn more about optimizing the inference speed of generative AI models as well as model compression from our panel of experts. If your applications are based on LLMs, we encourage you to explore how to speed up inference with SOTA quantization techniques with TensorRT-LLM.
For more information, see the following resources:
