
Transfer learning is an important machine learning technique that uses a model’s knowledge of one task to make it perform better on another. Fine-tuning is one of the techniques to perform transfer learning. It is an essential part of the recipe for many state-of-the-art results where a base model is first pretrained on a task with abundant training data and then fine-tuned on different tasks of interest where the training data is less abundant or even scarce. It is particularly successful in computer vision and natural language processing (NLP).
In this post, I show how the NVIDIA NeMo toolkit can be used for automatic speech recognition (ASR) transfer learning for multiple languages. Specifically, you use the QuartzNet model, pretrained on thousands of hours of English data, for ASR models in other languages (Spanish and Russian), where much less training data is available. This model can help you achieve absolute improvements of -27.3% and -4.8% in word error rate (WER), using only 16 and 96 hours of training data for Russian and Spanish, respectively.
NeMo
NeMo is an open-source toolkit to build state-of-the-art conversational AI models. It comes with extensive collections of modules for ASR, NLP, and text-to-speech (TTS). You can easily build models by chaining them together while ensuring semantic compatibility.
NeMo comes with high-quality, pretrained checkpoints available from NVIDIA NGC. This feature, together with its modular design, allows NeMo to easily fine tune models for your use cases. NeMo is available on GitHub and pip. For more information and collaboration, see the NVIDIA/NeMo repo. If you are new to NeMo or ASR, I recommend that you start with the End-To-End Automatic Speech Recognition interactive notebook, which you can run on Google Colaboratory (Colab).
Prerequisites
For this post, use the NeMo ASR collection. To install, use the following command:
pip install nemo_toolkit[asr]==0.10.1
The script used to run the experiments is available: quartznet.py. To track and visualize these experiments, I used Weights & Biases integration. You can install their library with the following command:
pip install --upgrade wandb
QuartzNet
To perform this fine-tuning experiment, use QuartzNet, a high-quality, lightweight ASR model. The model is composed of multiple blocks with residual connections between them. Each block consists of one or more modules with 1D time-channel separable convolutional layers, batch normalization, and ReLU layers. The model is trained with CTC loss. For more information, see QuartzNet: Deep Automatic Speech Recognition with 1D Time-Channel Separable Convolutions.
Figure 1 shows the QuartzNet consists of two main neural modules in QuartzNet: encoder and decoder.
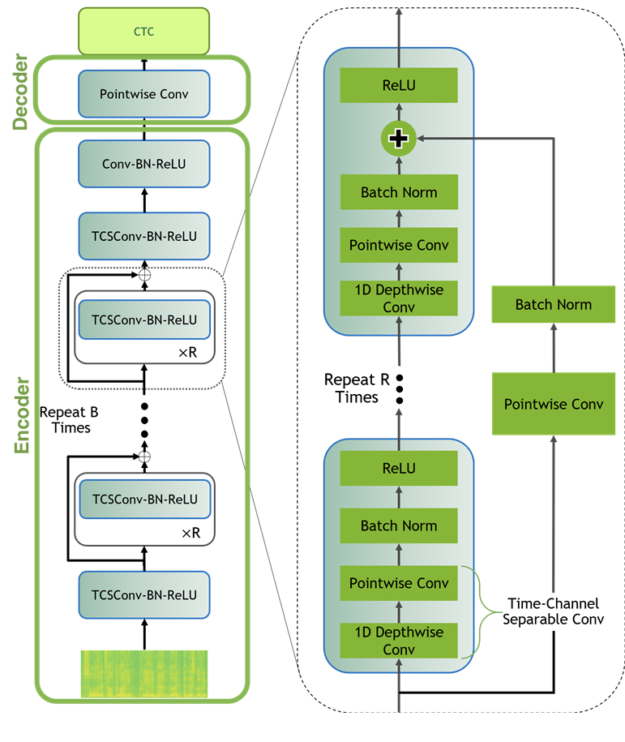
For this post, I used a QuartzNet-15×5 (B=15, R=5) configuration trained on LibriSpeech, Mozilla Common Voice, WSJ, Fisher, and Switchboard datasets combined. In total, the training data used to pretrain this model consists of ~3,300 hours of transcribed English speech.
This model achieves a WER of 3.91% on LibriSpeech dev-clean, and a WER of 10.58% on dev-other sets, while having only 19M parameters. These WER numbers were obtained with “greedy” decoding, without using any external language models.
Data download and pre-processing
For this post, download a pretrained English checkpoint and network configuration file, Multidataset-QuartzNet15x5 from NVIDIA NGC.
Next, use this model as the initial point to train Russian and Spanish ASR models using the corresponding portions of the Mozilla Common Voice dataset. In all steps, use the “train” portion of the data for training and the “dev” portion of the data for evaluation.
Compared to the English part of the data, the Russian and Spanish subsets of Mozilla’s Common Voice dataset are much smaller: about 16 and 96 hours, respectively.
This is much smaller than the combined English speech dataset with 3,300 hours, on which the pretrained English QuartzNet model was trained.
After the data is downloaded, pre-process it and create manifest files to be used by QuartzNet data layers. First, convert MP3 files into WAV files with a 16kHz sampling rate, matching the sampling rate of the QuartzNet model training data.
Second, define the alphabet: the set of characters to be the model output. To reproduce these results, see the Python scripts used for pre-processing data as well as the pre-processed data and model configs for the Spanish and Russian languages.
Walkthrough
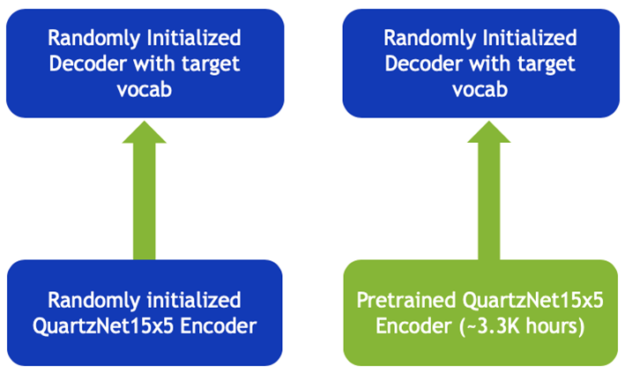
If you are following along with this post, you start with a model pretrained on 3,300 hours of English data and turn it into Russian and Spanish ASR models using orders of magnitude less Russian and Spanish data.
You might ask how this is even possible. After all, English, Russian, and Spanish are dissimilar languages. They have different alphabets, vocabulary, sounds, and grammar. Moreover, because QuartzNet is a CTC-model that outputs words character-by-character, the fact that these languages all have different alphabets means that there is no way you can reuse an English ASR network as-is.
This is where the NeMo modular paradigm comes to play. The NeMo QuartzNet implementation consists of two neural modules: encoder and decoder (shown in Figure 1). The encoder module contains most of the network’s weights. It can be thought of as a module that handles acoustics and produces a hidden representation for spoken language (encoding). The decoder takes that representation and generates letters from the target language’s alphabet. You don’t re-use the decoder because the alphabets are different. However, you can still reuse the encoder.
As a control for these experiments, I trained the same QuartzNet model from scratch.
Hyperparameters
For both Russian and Spanish language experiments, I used the NovoGrad optimizer with beta1=0.95, beta2=0.25, and batch_size of 32 per GPU, and used a single DGX with eight V100 GPUs for training. The total batch size is 32*8=256.
I varied the learning rate from 0.01 to 0.02 and from 0.001 to 0.002 for both kinds of experiments. For weight decay, I tried two values, 0.001 and 0.002. For fine-tuning, I found that as a rule of thumb, the learning rate should be at least 10x smaller than for a from-scratch experiment. I used a CosineAnnealing learning rate policy with a warmup ratio of 12%.
All experiments were conducted using mixed-precision optimization level O1 to take advantage of NVIDIA Tensor Cores available on Volta and Turing GPUs.
Transfer learning from English to Russian
For Russian language, perform the following language-specific preprocessing steps:
- Lowercase all letters.
- Remove everything that is not a Russian letter or space. The target vocabulary consists of 33 Russian letters and the space character.
Make the following modifications to the configuration file (quartznet15x5-ru.yaml):
- Turn off default transcript normalization because it was designed for the English language. Set normalize_transcripts: false in the AudioToTextDataLayer section of the config file.
- Change the labels to the array of 33 Russian characters and the space character.
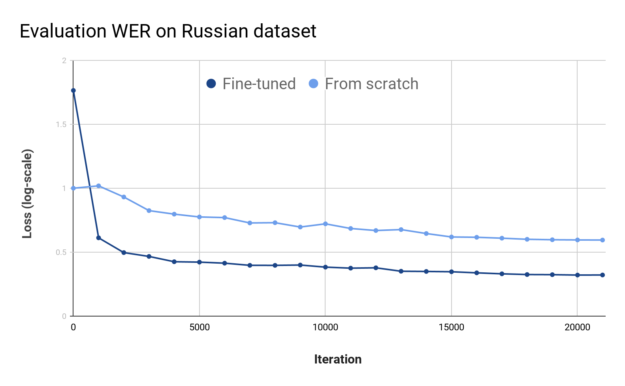
For the Russian language, both fine-tuning and from-scratch experiments were trained for 512 epochs. Figures 3 and 4 show the training loss and evaluation WER values of the best runs that I had while doing fine-tuning and training from scratch.
You can draw two conclusions from these plots. First, the model had no problem fitting the data. The training loss is relatively low at the end. When inspecting training logs, you can see that the training batch WER was under 2%. Second, the from-scratch experiments failed to generalize. The final evaluation WER was 59.5%. You could suspect overfitting after looking at these plots.
From there, there are many ways to proceed, with no guarantee of success. Try training a smaller model, various regularization techniques such as dropout or weight decay, or various data augmentation techniques.
I did use weight decay and spec augmentation technique in all experiments. I also trained a much smaller, 5×3 variant of QuartzNet. However, the best result that I got with it was a WER value over 42%. Instead of diving deeper into the training of other models, with various regularization and data augmentations tricks, I trained the same model, but with an encoder pretrained from English data.

Figures 3 and 4 shows the fine-tuned model at the end reaches similar training loss, though it gets there faster. Its Evaluation WER value, which is important, is much lower.
To summarize, I successfully used a pretrained English encoder to significantly drop the evaluation WER value on Russian from around 59.5% to 32.2%, which is a significant improvement.
Transfer learning English to Spanish
I observed similar results when experimenting with the Spanish portion of the Mozilla Common Voice dataset. The training data for Spanish is much larger than for Russian language (96 hours vs. 16) but is still many times smaller than the size of the English corpus used to pre-train the English model.
To train and fine-tune the Spanish dataset, make the following modifications:
- Preprocess all transcripts by turning all letters into lowercase
- Remove anything that isn’t a Spanish letter or space.
- As with the Russian experiments, turn off automatic transcript normalization and set labels in the config file to lowercase alphabet letters plus the space character.
- Because the Spanish dataset is larger than the Russian one, train all models for 256 epochs.
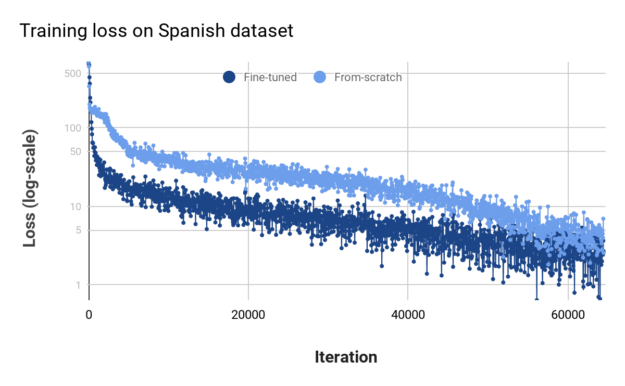
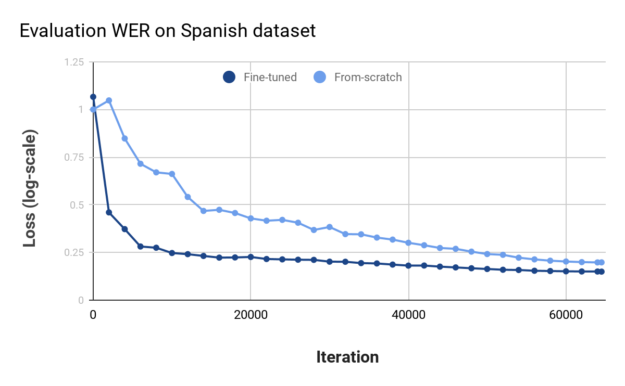
Figures 5 and 6 show the training loss and evaluation WER values for the best runs of the fine-tuned model and the model trained from scratch. Like the previous example, the model initialized with English checkpoints trains faster (training loss goes down faster) and achieves much better generalization performance.
At the end, you can achieve WER values of 14.96% and 19.82% for fine-tuned and from-scratch models, respectively. While not as dramatic an improvement as with the Russian dataset, an absolute difference of almost 5% in the WER metric is significant.
To further improve the quality of these models, seek more training data in these languages. Also, the reported WER numbers were all obtained using “greedy” decoding. You could significantly improve them, especially for domain-specific applications, using a beam search with the language model.
Conclusion
In this post, I demonstrated how starting with a good English ASR model pretrained on thousands of hours of public data can help you kick start your ASR models in other languages.
Fine-tuning from a pretrained English encoder improved the model’s generalization, measured by WER, for Russian from 59.5% to 32.2% and from 19.82% to 14.96% for Spanish. This is only using 16 and 96 hours of training data, respectively. This shows that it’s possible to improve results in one language by starting from a model in another language where more training data is available.
NeMo is a toolkit particularly well-suited for transfer learning. Its modular structure enables experiments where parts of the pretrained networks, such as encoders, can be reused. It also comes with high-quality ASR, NLP, and TTS modules trained on publicly available data, to help you get started with your transfer learning experiments.
For more experiments and in-depth discussion on transfer learning for ASR with NeMo, see the Cross-Language Transfer Learning, Continuous Learning, and Domain Adaptation for End-to-End Automatic Speech Recognition whitepaper.
For additional information on NeMo, join the upcoming webinar, Training and Deploying Conversational AI Applications.
