
Have you ever tried to fine-tune a speech recognition system on your accent only to find that, while it recognizes your voice well, it fails to detect words spoken by others? This is common in speech recognition systems that have trained on hundreds of thousands of hours of speech.
In large-scale automatic speech recognition (ASR), a system may perform well in many but not all scenarios. It may require more accuracy in a noisy environment, for example. Or it may need adjustment for a user with a strong accent or unique dialect.
In such cases, a simple approach is to fine-tune the model on samples of that particular domain. Still, this procedure may severely impair the model’s accuracy on general speech as it overfits the new domain.
This post presents a simple method to select models that can balance the recognition accuracy of general speech and improve recognition on adaptation domains with the help of adapter modules for transducer-based speech recognition systems.
Adapter module and transducer-based speech recognition systems
Neural networks are usually composed of multiple modules; for example, the encoder and decoder modules commonly used in speech recognition or natural language processing (NLP). While it is possible to fine-tune all the millions of parameters in these modules, parameter-efficient training using adapter modules reduces the effect of catastrophic forgetting and still provides strong results.
Figure 1 shows the three main modules of a transducer-based speech recognition system, including the conformer encoder, LSTM decoder (called the transducer decoder) and the multilayer perceptron joint (also called the transducer joint). It also shows how adapters are applied to these components.
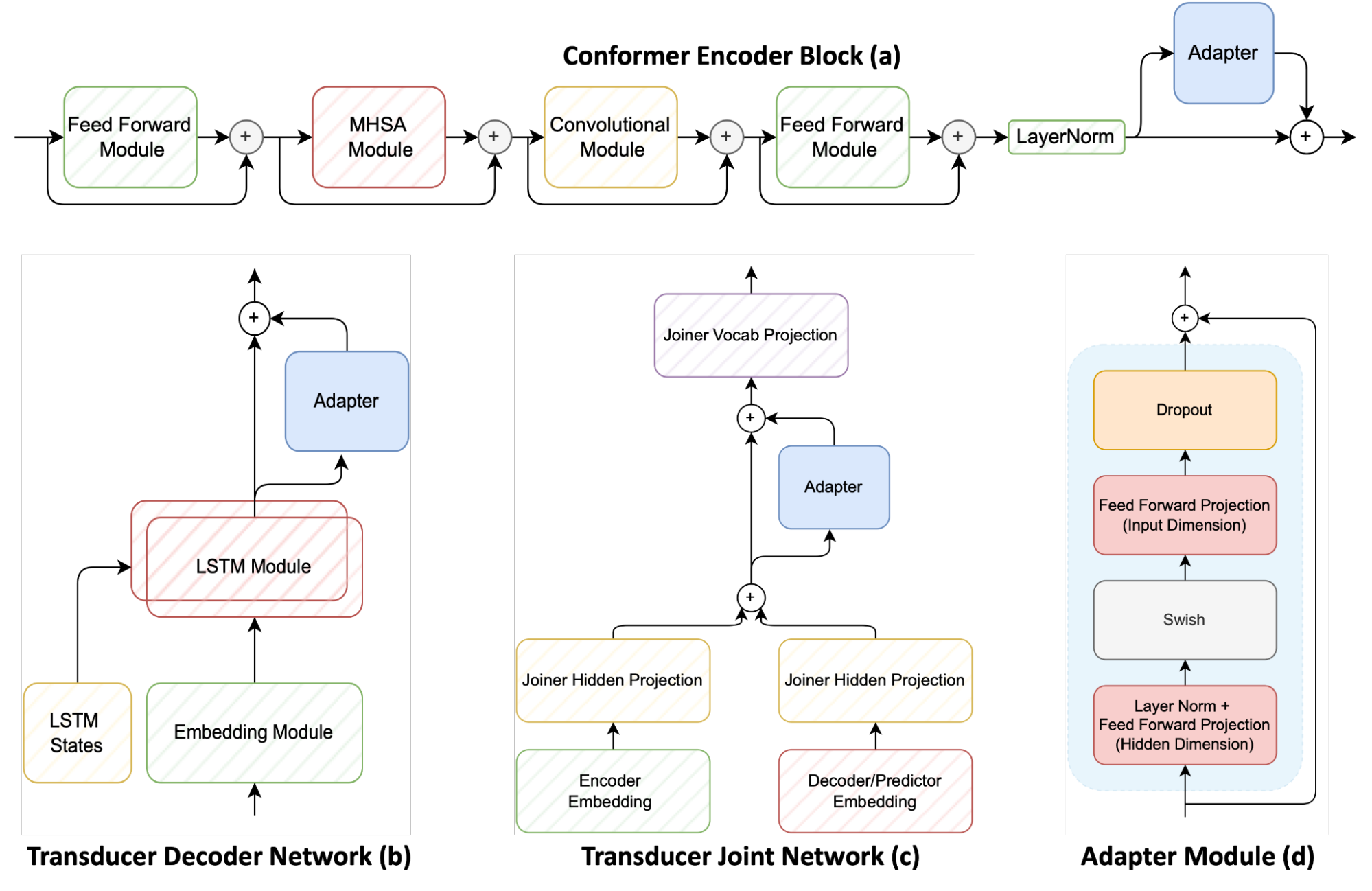
An adapter module (d) can be a simple feed-forward network attached to a pretrained neural network. Doing so adds additional model parameters to the original model. Then freeze the original model parameters and train just the adapter parameters.
Adapter networks are generally placed on each encoder conformer layer (a). However, this approach proposes to add adapters to the transducer decoder (b) and transducer joint network (c) to offer fine control between adaptation to the new domain compared to general speech.
After training multiple candidate models, it is necessary to determine which model has the best tradeoff in recognition accuracy on the new domain (with a new dialect, accent, or noise environment, for example) and accuracy on general speech.
A simple method that measures the accuracy of the model before and after adaptation on evaluation datasets of both the original domain and the new domain is as follows:
\(WERDeg_{o}=max(0, WER_{o^{*}}-WER_{o})\)
- o*, a* represents evaluation on the original and adapted domain after the adaptation process
- o, a represents the same before the adaptation process
First, define WERDeg as the difference between the word error rate (WER) after and before adaptation. Also ensure that the model must improve the WER after adaptation. Otherwise, this value should be 0.
\(O_{scale}=\frac{1}{N}\sum_{i=1}^{N}\frac{max(0, K_{i}-WERDeg_{o,i})}{K_{i}}\)
- N is the number of evaluation datasets from the original domain
- K is the maximum tolerable absolute degradation of word error rate on the original domain
Next, compute the effective relative degradation of the model on the original dataset. First choose a value for K, the maximum tolerable degradation that will be accepted. For this example, 3% is the maximum tolerable degradation.
Then compute the relative difference between K and the WERDeg on the original dataset (o). Finally, sum all these scores over N number of evaluation datasets from the original domain. If, on any dataset, the model exceeds the degradation limit K, then set the score for that dataset to 0.
\(A_{werr}=max(0,\frac{WER_{a}-WER_{a^{*}}}{WER_{a}})\)
- Relative improvement in WER on new domain
- The underscript refers to whether the metric was calculated on the adaptation dataset before (a) or after (a*) the model has been trained to the adaptation dataset
Next, compute the relative improvement of the model on the adaptation dataset. For this example, a relative weight was chosen since, in some cases, even a small improvement can be significant in production systems that have been optimized.
\(Score=O_{SCALE}*A_{WERR}\)
The scoring metric is then calculated as a simple multiplication of the two metrics. Scoring the metric when maximized yields a candidate that obtains the greatest improvement on the new domain, with the least degradation on the old domain.
Adapter effectiveness on dialect adaptation
To evaluate the effectiveness of adapters in this setting of constrained domain adaptation, adapt a 120 million parameter conformer transducer model on the UK and Ireland English Dialect dataset. The results are shown in Figure 2.
While simple fine-tuning rapidly damages the recognition accuracy of general speech, adapters can offer similar results to full fine-tuning of the model, without significant worsening on general speech.
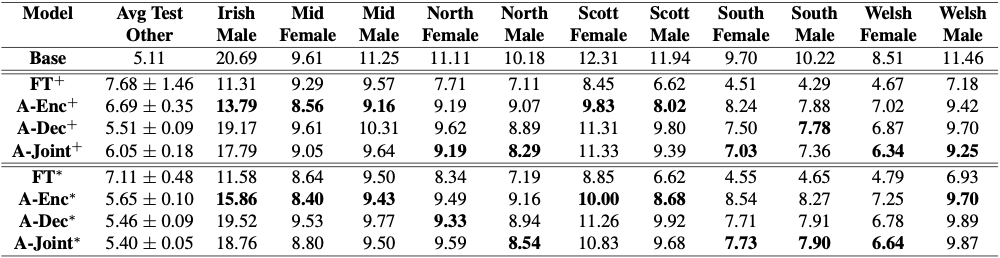
In Figure 2, + indicates models unconstrained adaptation (fine-tuning without limitations), and * indicates constrained domain adaptation. Full fine-tuning obtains the best results in the new domain but harshly impairs general speech recognition.
The bolded cells indicate candidates that maximize the scoring metric defined previously, thereby getting strong results on new domains while minimizing damage for general speech recognition. The effect of constrained domain adaptation is even more pronounced on the challenging task of open vocabulary voice command recognition.
Speech command recognition
Next, the speech recognition model is adapted to the 35 command words in the Google Speech Commands dataset. These 35 commands are common everyday words for performing an action, such as ‘go,’ ‘stop,’ ‘start,’ and left.’ These command words are all part of the Librispeech training dataset, so a highly robust ASR model should easily classify these words. However, the model’s accuracy is roughly just 60%, compared to the state-of-the-art speech classification models that can attain close to 97%.
One would think that speech recognition limited to just 35 words would be easier than learning to transcribe thousands of hours of speech. Indeed, this could be extended to ‘open vocabulary speech command recognition,’ a task in which any word of the language can become a command recognized by the model.
For example, suppose you want a model to recognize a user and activate when that user says, “open sesame.” It is quite difficult to gather data for this case, but the words may be common enough in large ASR datasets, so ASR models should recognize those words with high accuracy. However, it is far more challenging than expected.
Adapting a speech recognition model for open vocabulary keyword detection
The reason for this challenge is the vast difference in the accuracy of transcribing general speech compared to a specific command. This is due to the difference between how the models were trained compared to how they were evaluated.
Training the speech recognition models involved using samples 15-20 seconds long containing several dozen words. However, when performing speech command recognition, these models are trained and evaluated with just 1 second of audio. This massive shift in the training and evaluation regiment severely impacts the model, causing catastrophic degradation of recognition on general speech recognition.
If you attempt to make an unconstrained adaptation, the model nearly forgets how to transcribe general speech. However, when training under a constrained scenario with adapters, you can rapidly improve recognition accuracy on the commands while maintaining strong recognition capabilities on general speech.
Constrained adaptation for open vocabulary command recognition
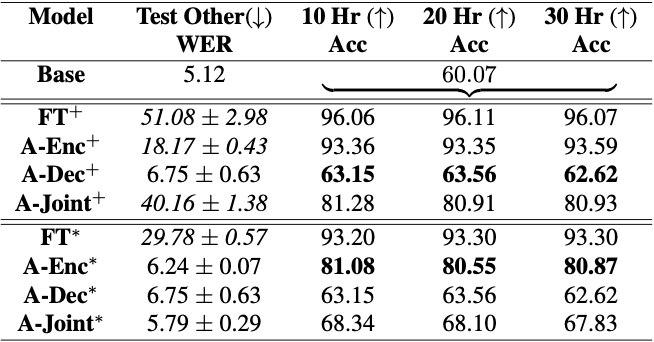
Figure 3 shows the difficulty in adapting speech recognition systems to open vocabulary command recognition data. Simply fine-tuning the entire model increases the WER from 5% to nearly 30-50%, making the model completely unusable. Still, its accuracy on the dataset improves significantly from 60% to 96%. Then impose constrained adaptation and obtain candidates that balance their prior knowledge of general speech recognition with accurately detecting speech commands.
Conclusion
With constrained domain adaptation, it is feasible to adapt any pretrained model with only a small amount of data. Using adapters for parameter-efficient training reduces the effects of catastrophic forgetting of general speech recognition. This is shown by adapting to a large number of UK and Irish Dialects for English speech. Further, accuracy on open vocabulary speech command recognition can be improved with these techniques.
Adaptation of speech recognition systems to the custom requirements of their deployments is an important endeavor. Obtaining more efficient ways to adapt large models on the fly will enable highly effective speech recognition. One day soon, it may be possible to personalize speech recognition systems for each user with just a few minutes of adaptation data while retaining their general accuracy without significant degradation.
For more information about this work, see Damage Control During Domain Adaptation for Transducer-Based Automatic Speech Recognition.
To learn more about how to adapt ASR models to new domains using adapters, visit the ASR_with_Adapters.ipynb NVIDIA NeMo tutorial on GitHub.
