Multilingual automatic speech recognition (ASR) models have gained significant interest because of their ability to transcribe speech in more than one language. This is fueled by the growing multilingual communities as well as by the need to reduce complexity. You only need one model to handle multiple languages.
This post explains how to use pretrained multilingual NeMo ASR models from the NGC catalog. We also share best practices for creating your own multilingual datasets and training your own models.
How multilingual ASR models work
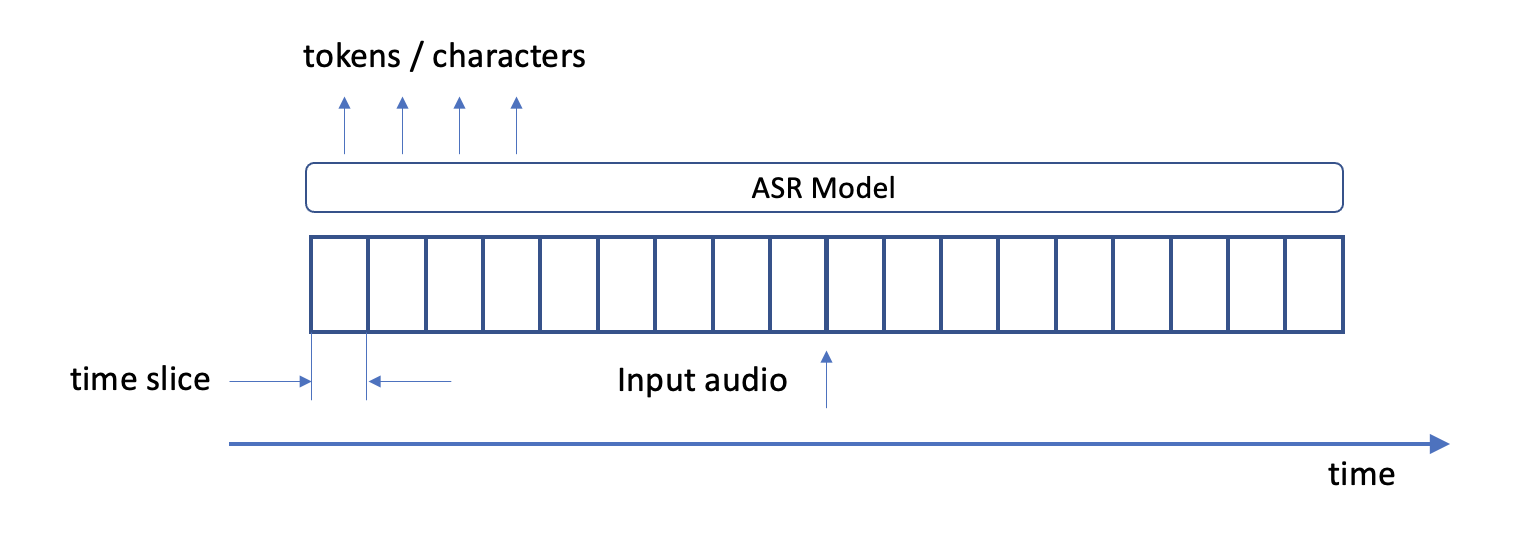
ASR models convert speech to text at a high level. At inference time, they consume audio files as input and generate text tokens or characters as output (Figure 1). More precisely, at each audio sample timestep, the model outputs the log probability for each one of a total of num_classes tokens.
At training time, you supply text transcripts as well as audio files as inputs. As the model trains, it uses the transcripts to compute a training loss. It gradually minimizes this loss and improves its weights and gets its output transcripts as close to the originals as possible.
The multilingual context adds a few aspects to the picture. During inference, you typically don’t know the language or languages that the audio contains. However, if the model knows the language ID (LID) that it encounters in the audio, it may be useful for it to output it.
This could be used to put together language-specific processing pipelines downstream from an ASR model. Similarly, you may need to supply the LID values present in each sample during training.
Code-switching refers to changing between different languages during a conversation. Such models must anticipate that each sample may contain more than one LID value and need to be trained accordingly.
A deeper dive
There are two basic approaches to creating multilingual models.
In the first approach, you can largely ignore the fact that there are multiple languages in the dataset and shuffle the transcripts as-is, letting the model figure everything out. If the model uses text tokenization, you only have to ensure that the tokenizer vocabulary size is sufficient to cover all the languages. You combine the transcripts across the different languages and train the tokenizer.
In the second approach, you tag each text sample in the transcript with the appropriate LID. If the model uses tokenizers, you train them separately on each language and then use the NeMo aggregate tokenizer functionality to combine them.
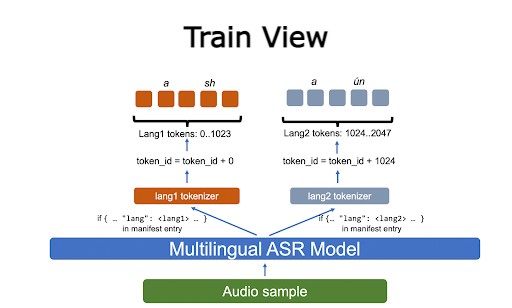
Each language gets an assigned range of token IDs, and the model learns to generate them. During decoding, to determine the LID of a particular token, you look at the range of its ID (Figure 2).

During training, you tokenize the input text using the appropriate monolingual tokenizer. You then shift the token IDs to ensure that there is no overlap, with each language getting its own numerical range (Figure 3).
Code-switching does not present a challenge beyond dataset preparation. In our experience, to be good at code-switching, models must be specifically trained on samples consisting of more than one language. We return to this topic in subsequent sections.
Inference with NeMo multilingual ASR models
Pretrained multilingual NeMo models can be used pretty much the same way as monolingual ones. Start by initializing a pretrained checkpoint from NGC.
The model has an enes prefix, indicating that it was trained on both languages:
asr_model = nemo_asr.models.EncDecRNNTBPEModel.from_pretrained(model_name="stt_enes_contextnet_large")
Compile a list of input audio files:
en_files = ["./datasets/mini/LibriSpeech/dev-clean-2-processed/7976-110523-0000.wav", "./datasets/mini/LibriSpeech/dev-clean-2-processed/7976-110523-0001.wav"]
Transcribe them:
transcripts = asr_model.transcribe(paths2audio_files = en_files) [0]
To output the LID, make a small change to the decoding strategy of the model:
decoding_cfg = OmegaConf.create({})
with open_dict(decoding_cfg):
decoding_cfg.compute_langs = True
asr_model.change_decoding_strategy(decoding_cfg)
You can now perform inference:
hyp, _ = asr_model.transcribe(paths2audio_files = es_files, return_hypotheses=True)
The Hyp[0].langs variable contains the best estimate for the LID for sample 0 in batch (es) c. The hyp[0].langs_chars variable contains the LID for each:
[{'char': 'a', 'lang': 'es'}]
Code-switched checkpoints work the same way. They are marked with the codesw string in the NGC model checkpoint name. For more information, see Multilingual ASR models with Subword Tokenization in NeMo.
How to train a multilingual model?
As we already mentioned, the simplest way to build a multilingual model is to directly mix monolingual datasets and train the model on the mixture. This method does not preserve the LID information but it works quite well, yielding highly accurate models.
If code-switching functionality is desired, the ideal scenario would involve the use of a real code-switched training set. In the absence of that, you create a synthetic one (Figure 4).
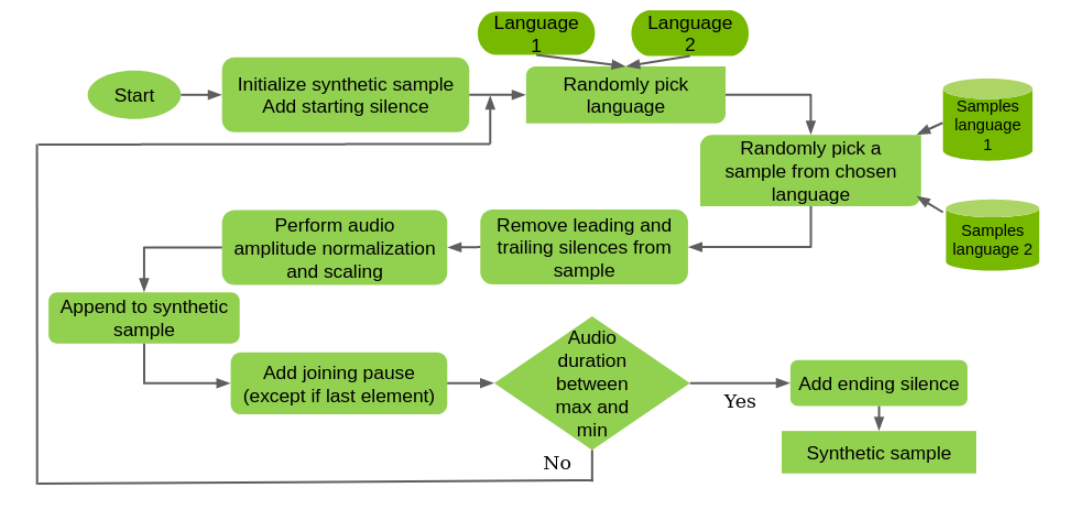
In this example, you randomly combine monolingual samples from different languages, trimming silences, normalizing audio by volume, and introducing random pauses. You just have to not exceed a certain maximum audio length for a synthetic sample, typically set to 20 seconds.
This is not perfect either, as the context between the samples is lost. However, the model can switch between the languages within a sample.
If retaining the LID is important, you can use the sample-wide lang field in the NeMo manifest:
{"audio_filepath": "data1.wav", "duration": 7.04, "text": "by the time we had placed the cold fresh-smelling little tree in a corner of the sitting room it was already Christmas eve", "lang": "en"}
Code-switched datasets have more than one LID per sample, so you can also use the following code:
{"audio_filepath": "/data2.wav", "duration": 17.32425, "text": [{"lang": "en", "str": "the mentality is that of a slave-owning community with a mutilated multitude of men tied to its commercial and political treadmill "}, {"lang": "es", "str": "y este "}]}
Next, train the model using an aggregate tokenizer consisting of monolingual tokenizers. In the model config file, it looks like the following code example:
tokenizer:
type:agg
langs:
en:
type: bpe
dir: english_tokenizer_dir
es:
type: bpe
dir: spanish_tokenizer_dir
In the example, we used English (LID en) and Spanish (LID es). Pretrained tokenizers are placed into their respective directories, and we referred to these directories.
A few notes on model training:
- The datasets must be well-mixed, ideally, before the creation of tarred or bucketed datasets.
- The datasets must be balanced. For example, they should contain about the same number of hours in each language. If one of the monolingual datasets is significantly larger than the other, it is likely a good idea to oversample the smaller dataset to prevent the model from learning the larger language preferentially.
- It is possible to start training the model from one of the monolingual checkpoints. This generally speeds up convergence. However, in that case, it’s a good idea to oversample the incremental language.
Summary
In this post, we covered the use of multilingual NeMo ASR models:
- How to use them for inference
- How to train them
- The difference between the usual multilingual models and code-switched models
- How to preserve and output the LID information
We are working on adding many more languages to our models and will share these results soon.
All the code referenced in this post is publicly available in the NeMo GitHub repo and the models are available in NGC: