Posts by Shankar Chandrasekaran
Data Science
Jun 28, 2023
How to Deploy an AI Model in Python with PyTriton
AI models are everywhere, in the form of chatbots, classification and summarization tools, image models for segmentation and detection, recommendation models,...
6 MIN READ
Simulation / Modeling / Design
Mar 23, 2023
Power Your AI Inference with New NVIDIA Triton and NVIDIA TensorRT Features
NVIDIA AI inference software consists of NVIDIA Triton Inference Server, open-source inference serving software, and NVIDIA TensorRT, an SDK for...
5 MIN READ

Data Science
Nov 30, 2022
Designing an Optimal AI Inference Pipeline for Autonomous Driving
Self-driving cars must be able to detect objects quickly and accurately to ensure the safety of their drivers and other drivers on the road. Due to this need...
8 MIN READ
Data Science
Oct 25, 2022
Run Multiple AI Models on the Same GPU with Amazon SageMaker Multi-Model Endpoints Powered by NVIDIA Triton Inference Server
Last November, AWS integrated open-source inference serving software, NVIDIA Triton Inference Server, in Amazon SageMaker. Machine learning (ML) teams can use...
2 MIN READ
Simulation / Modeling / Design
Sep 21, 2022
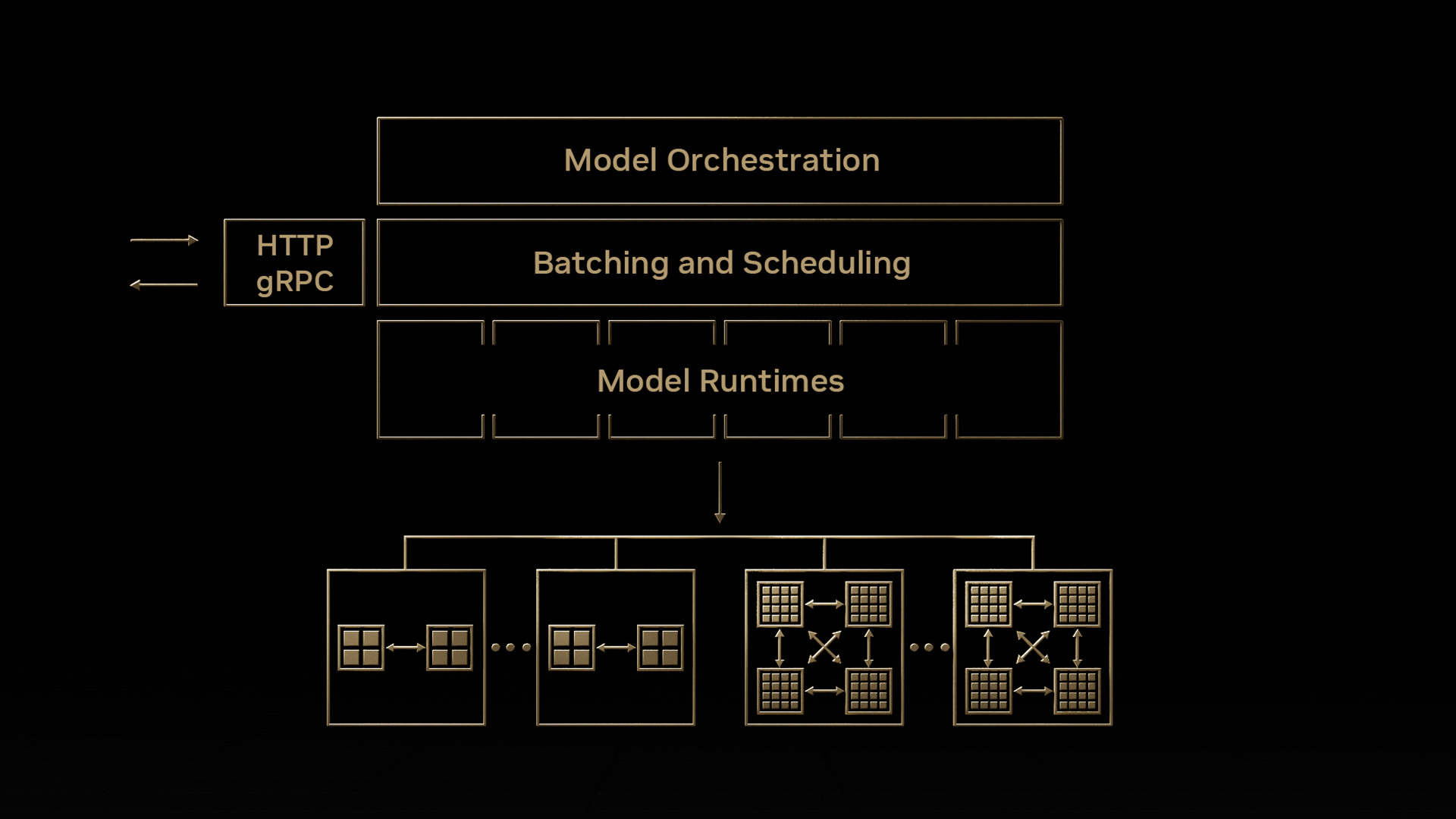
Solving AI Inference Challenges with NVIDIA Triton
Deploying AI models in production to meet the performance and scalability requirements of the AI-driven application while keeping the infrastructure costs low...
12 MIN READ

Robotics
May 23, 2022
Implementing Industrial Inference Pipelines for Smart Manufacturing
Implementing quality control and assurance methodology in manufacturing processes and quality management systems ensures that end products meet customer...
3 MIN READ