
Big data, new algorithms, and fast computation are three main factors that make the modern AI revolution possible. However, data poses many challenges for enterprises: difficulty in data labeling, ineffective data governance, limited data availability, data privacy, and so on.
Synthetically generated data is a potential solution to address these challenges because it generates data points by sampling from the model. Continuous sampling can generate an infinite number of data points including labels. This allows for data to be shared across teams or externally.
Generating synthetic data also provides a degree of data privacy without compromising quality or realism. Successful synthetic data generation involves capturing the distribution while maintaining privacy and conditionally generating new data, which can then be used to make more robust models or used for time-series forecasting.
In this post, we explain how synthetic data can be artificially produced with transformer models, using NVIDIA NeMo as an example. We explain how synthetically generated data can be used as a valid substitute for real-life data in machine learning algorithms to protect user privacy while making accurate predictions.
Transformers: the better synthetic data generator
Deep learning generative models are a natural fit to model complicated real-world data. Two popular generative models have achieved some success in the past: Variational Auto-Encoder (VAE) and Generative Adversarial Network (GAN).
However, there are known issues with VAE and GAN models for synthetic data generation:
- The mode collapse problem in the GAN model causes the generated data to miss some modes in the training data distribution.
- The VAE model has difficulty generating sharp data points due to non-autoregressive loss.
Transformer models have recently achieved great success in the natural language processing (NLP) domain. The self-attention encoding and decoding architecture of the transformer model has proven to be accurate in modeling data distribution and is scalable to larger datasets. For example, the NVIDIA Megatron-Turing NLG model obtains excellent results with 530B parameters.
GPT
OpenAI’s GPT3 uses the decoder part of the transformer model and has 175B parameters. GPT3 has been widely used across multiple industries and domains, from productivity and education to creativity and games.
The GPT model turns out to be a superior generative model. As you may know, any joint probability distribution can be factored into the product of a series of conditional probability distributions according to the probability chain rule. The GPT autoregressive loss directly models the data joint probability distribution shown in Figure 1.
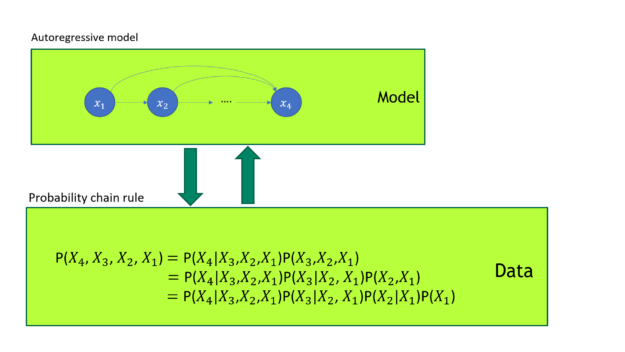
In Figure 1, the GPT model training uses autoregressive loss. It has a one-to-one mapping to the probability chain rule. GPT directly models the data joint probability distribution.
Because tabular data is composed of different types of data as rows or columns, GPT can understand the joint data distribution across multiple table rows and columns, and generate synthetic data as if it were NLP-textual data. Our experiments show that indeed the GPT model generates higher-quality tabular synthetic data.
A higher-quality tabular data tokenizer
Despite its superiority, there are a number of challenges with using GPT to model tabular data: the data inputs to the GPT model are sequences of token IDs. For NLP datasets, you could use a byte-pair encoding (BPE) tokenizer to convert the text data into sequences of token IDs.
It is natural to use the generic GPT BPE tokenizer for tabular datasets; however, there are a few problems with this approach.
First, when the GPT BPE tokenizer splits the tabular data into tokens, the number of tokens is usually not fixed for the same column at different rows, because the number is determined by the occurrence frequencies of the individual subtokens. This means that the columnar information in the table is lost if you use an ordinary NLP tokenizer.
Another problem with the NLP tokenizer is that a long string in a column would consist of a large number of tokens. This is wasteful considering that GPT has a limited capacity for modeling the sequences of tokens. For example, the merchant name Mitsui Engineering & Shipbuilding Co needs 7 tokens to encode it ([44, 896, 9019, 14044, 1222, 16656, 16894, 1766]) with a BPE tokenizer.
As discussed in the TabFormer paper, a viable solution is to build a specialized tokenizer for the tabular data that considers the table’s structural information. The TabFormer tokenizer uses a single token for each of the columns, which can cause either accuracy loss if the number of tokens is small for the column, or weak generalization if the number of tokens is too large.
We improve it by using multiple tokens to code the columns.
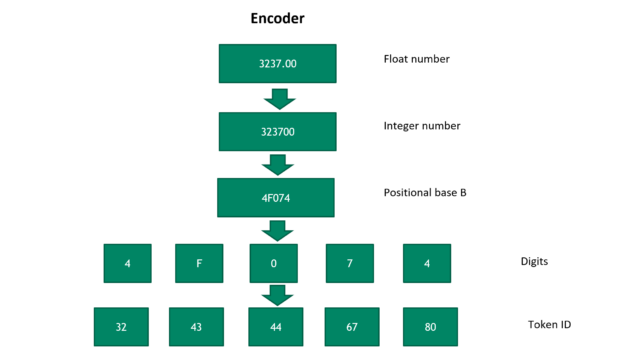
Figure 2 shows the steps of converting a float number into a sequence of token IDs. First, we reversibly convert the float number into a positive integer. Then, it is transformed into a number with positional base B, where B is a hyperparameter. The larger the base B number is, the fewer tokens it needs to represent the number.
However, a larger base B sacrifices the generality for new numbers. In the last step, the digit numbers are mapped to unique token IDs. To convert the token IDs to a float number, run through these steps in reverse order. The float number decoding accuracy is then determined by the number of tokens and the choice of positional base B.
Scaling model training with NeMo framework
NeMo is a framework for training conversational AI models. In the released code inside the NeMo repository, our tabular data tokenizer supports both integer and categorical data, handles NaN values, and supports different scalar transformations to minimize the gaps between the numbers. For more information, see our source code implementation.
You can use the special tabular data tokenizer to train a tabular synthetic data generation GPT model of any size. Large models can be difficult to train due to memory constraints. The NeMo framework is a toolkit for training large language models within NeMo and provides both tensor model parallel and pipeline model parallelism.
This enables the training of transformer models with billions of parameters. On top of the model parallelism, you can apply data parallelism during training to fully use all GPUs in the cluster. According to OpenAI’s scaling law of natural language and theory of over-parameterization of deep learning models, it is recommended to train a large model to get reasonable validation loss given the training data size.
Applying GPT models to real-world applications
In our recent GTC talk, we showed that a trained large GPT model produces high-quality synthetic data. If we continue sampling the trained tabular GPT model, it can produce an infinite number of data points, which all follow the joint distribution as the original data. The generated synthetic data provides the same analytical insights as the original data without revealing the individual’s private information. This makes safe data sharing possible.
Moreover, if you condition the generative model on past data to generate future synthetic data, the model is actually predicting the future. This is attractive to customers in the financial services industry who are dealing with financial time series data. In collaboration with Cohen & Steers, we implemented a tabular GPT model to forecast economic and market indicators including inflation, volatility, and equity markets with quality results.
Bloomberg presented at GTC 2022 how they applied our proposed synthetic data method to analyze the patterns of credit card transaction data while protecting user data privacy.
Apply your knowledge
In this post, we introduced the idea of using NeMo for synthetic tabular data generation and showed how it can be used to solve real-world problems. For more information, see The Data-centric AI Movement.
If you are interested in applying this technique to your own synthetic data generation, use this NeMo framework Synthetic Tabular Data Generation notebook tutorial. For hands-on training on applying this method to generate synthetic data, reach out to us directly.
For more information, see the following GTC sessions:
