
The vast majority of the world’s data remains untapped, and enterprises are looking to generate value from this data by creating the next wave of generative AI applications that will make a transformative business impact. Retrieval-augmented generation (RAG) pipelines are a key part of this, enabling users to have conversations with large corpuses of data and turning manuals, policy documents, and more into interactive generative AI applications.
However, there are some common challenges that enterprises face when implementing RAG pipelines. It’s difficult to handle both structured and unstructured data and it’s computationally intensive to process and retrieve data. It’s also important to build privacy and security into RAG pipelines.
To solve this, NVIDIA and Oracle have worked together to demonstrate how multiple portions of the RAG pipeline can take advantage of the NVIDIA accelerated computing platform on Oracle Cloud Infrastructure (OCI). This approach helps enterprises leverage their structured and unstructured data more effectively, enhancing both the quality and reliability of generative AI outputs.
This post dives into each component of the RAG pipeline recently demonstrated at Oracle CloudWorld 2024:
- NVIDIA GPUs for accelerated bulk generation of vector embeddings from large datasets in Oracle Autonomous Database
- Accelerated generation of vector indexes for Oracle Database 23ai AI Vector Search with NVIDIA cuVS library
- Performant LLM inference using NVIDIA NIM on OCI
We also explain how you can get started using some of these exciting capabilities.
Embedding generation with NVIDIA GPUs and Oracle Autonomous Database
In today’s data-rich enterprise environments, effectively harnessing large amounts of text data for generative AI is key to enhancing efficiency, reducing costs, and ultimately driving productivity.
NVIDIA has partnered with Oracle to demonstrate how customers can get integrated access to NVIDIA GPUs through Oracle Machine Learning (OML) Notebooks in Autonomous Database. This newly announced capability enables OML users to employ Python to load data directly from an Oracle Database table into an OCI NVIDIA GPU-accelerated virtual machine (VM) instance, generate vector embeddings using the GPU, and store those vectors in Oracle Database where they can be efficiently searched using AI Vector Search. Provisioning the GPU instance and transferring data to and from it is done automatically for users, enabling seamless access for Autonomous Database users.
Accelerated vector search indexes and Oracle Database 23ai
NVIDIA cuVS is an open-source library for GPU-accelerated vector search and clustering. One of the key capabilities of cuVS is its ability to dramatically improve index build time, a key component of vector search.
NVIDIA has partnered with Oracle to demonstrate a proof of concept that accelerates vector index builds for the Hierarchical Navigable Small World (HNSW) algorithm. This shows how cuVS constructs a graph-based index which is optimized for speed on the GPU, and then converts the graph to an HNSW-compatible index on the Oracle Database. The end result of pairing GPUs with CPUs results in faster overall index generation than with CPUs alone. The ability to offload index creation to GPUs and deploy to CPU is a key feature of the cuVS library.
The fast creation of vector indexes is essential for supporting high-volume AI vector workloads, especially when large amounts of enterprise data must be processed and refreshed to keep out-of-the-box LLMs updated with the latest information. Building HNSW indexes on GPUs and deploying them to the Oracle database can increase the performance and lower the cost of AI workloads.
Performant LLM inference with NIM on OCI
NVIDIA NIM provides containers to self-host GPU-accelerated inferencing microservices for pretrained and customized AI models across clouds, data centers, and workstations. NIM microservices are especially useful for enterprises to deploy generative AI models efficiently and securely. NIM delivers optimized microservices designed for NVIDIA-accelerated infrastructure, enabling smooth integration with existing tools and applications.
Developers can quickly deploy LLMs with minimal code, whether on-premises or in Kubernetes-managed cloud environments. NIM also offers top-tier performance out of the box, reducing latency and boosting throughput, which simplifies real-time AI deployment while ensuring secure operations.
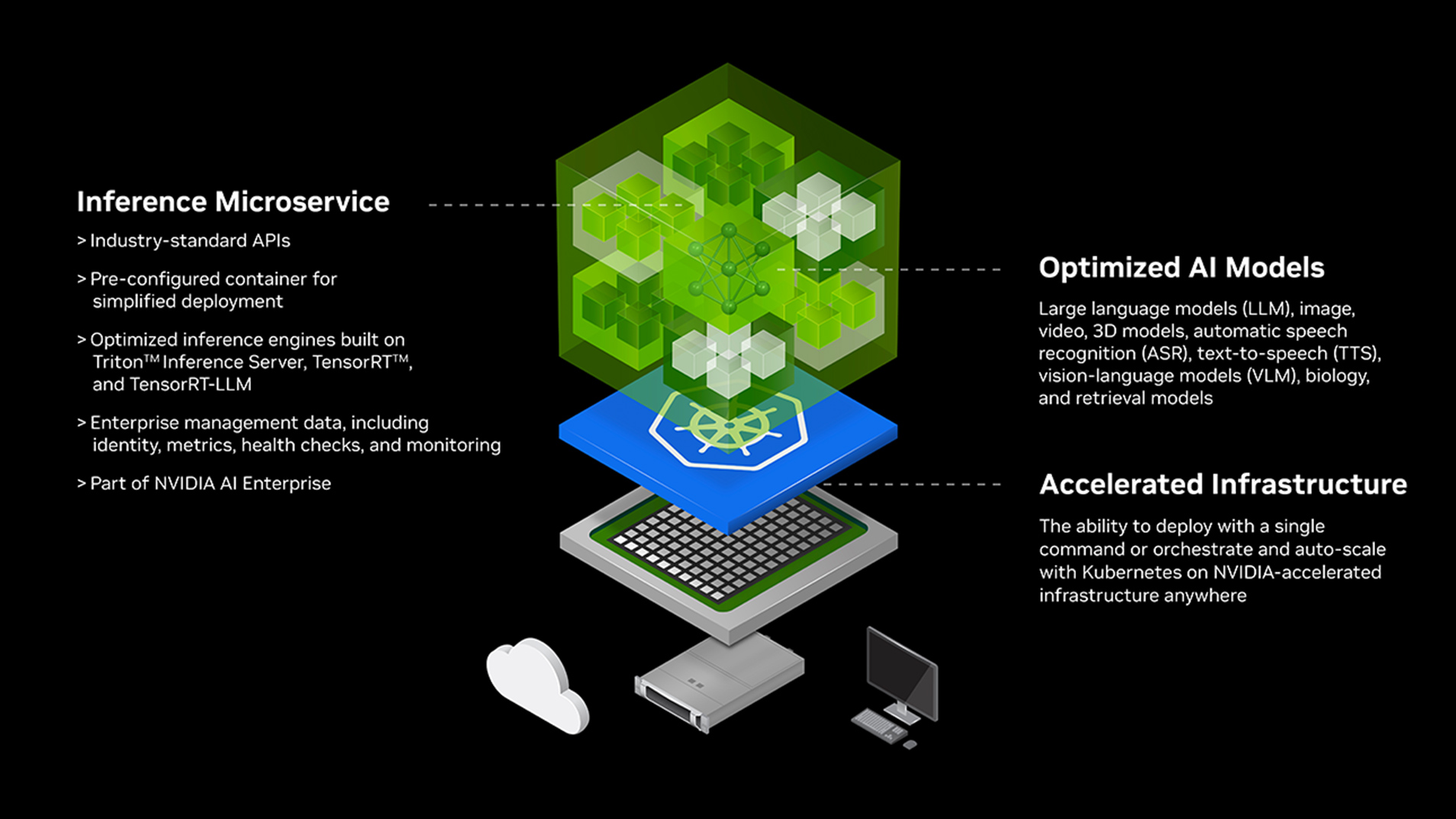
Deploying NVIDIA NIM on Oracle Cloud Infrastructure provides enterprises with several key benefits, including:
- Improving TCO with low-latency, high-throughput inference that scales
- Speeding time to market with prebuilt, cloud-native microservices
- Maintaining security and control of applications and data with self-hosted model deployment
NIM can be deployed on OCI in two ways. The first option uses an NVIDIA GPU-accelerated bare-metal instance or on a VM, which provides dedicated server access for strong isolation and the highest performance. To get started, simply sign in, create an NVIDIA GPU-accelerated instance, and securely connect with SSH. Then download a NIM from the NVIDIA API catalog, launch the Docker container, and call the model directly from your compute instance.
The second option uses the Oracle Container Engine for Kubernetes (OKE), which makes it easy to deploy, manage, and rapidly scale containerized applications, like NIM, on OCI using Helm charts available through NVIDIA/nim-deploy on GitHub.
For the Oracle CloudWorld demonstration, we worked with the OCI team to show how using NIM for LLMs can enable customers to achieve higher throughput compared to off-the-shelf open-source alternatives when using high levels of concurrency (batch size). This performance boost is particularly evident in text generation and translation use cases.
Video 2 shows this holistic approach in a sample end-to-end RAG pipeline querying Oracle CloudWorld 2024 session data stored in Oracle Database 23ai. This is an example of how out-of-the-box LLMs can benefit from a RAG pipeline with the NVIDIA accelerated computing platform hosted on OCI. It brings together NeMo Retriever NIM microservices with embedding and reranking model types, the Llama 3.1 405B NIM microservice, and NVIDIA H100 Tensor Core GPUs.
Get started
There are many elements involved in implementing an end-to-end RAG pipeline. NVIDIA has partnered with the OCI and Oracle Database teams to demonstrate how bulk generation of vector embeddings, HNSW index creation, and inferencing elements can be accelerated using NVIDIA GPUs and software. By focusing on some of the most computationally intensive portions of the RAG pipeline, we’ve shown how organizations using Oracle Database 23ai and OCI can increasingly leverage the performance gains available from the NVIDIA accelerated computing platform. This holistic approach will help customers use AI to leverage the immense amount of data stored in Oracle databases.
Learn more about cuVS. To try NVIDIA NIM, visit ai.nvidia.com and sign up for the NVIDIA Developer Program to gain instant access to the microservices. You can also start using NVIDIA GPU-enabled notebooks on Autonomous Database, the Oracle Database 23ai AI Vector Search with Oracle Database 23ai Free.
