
Federated learning (FL) has emerged as a promising approach for training machine learning models across distributed data sources while preserving data privacy. However, FL faces significant challenges related to communication overhead and local resource constraints when balancing model requirements and communication capabilities.
Particularly in the current era of large language models (LLMs), FL faces computational challenges when deploying LLMs with billions of parameters. The sheer size of these models exacerbates both communication and memory constraints. Transmitting full model updates in one shot can become infeasible due to bandwidth limitations and local memory constraints can make processing large models for communication challenging. Addressing these issues requires innovative strategies.
NVIDIA FLARE, a domain-agnostic, open-source, and extensible SDK for federated learning, has enhanced the real-world federated learning experience by introducing reliable communication capabilities, support for multiple concurrent training jobs, and robustness against potential job disruptions due to network conditions.
The NVFlare 2.4.0 release introduced the streaming API to facilitate the transfer of objects exceeding the 2-GB size limit imposed by gRPC. It added a new streaming layer designed to handle the transmission of large data messages robustly.
With the streaming API, you’re no longer restricted by the gRPC’s 2-GB size limit. However, with state-of-the-art models growing bigger, two challenges are becoming the bottleneck of a FL pipeline with LLMs:
- Transmission message size under the default fp32 precision
- Local memory allocation for holding the object during transmission
To enable a more efficient and robust federated pipeline, in NVFlare 2.6.0 we introduced two key techniques that facilitate message size reduction and memory-efficient transmission:
- Message quantization: Quantization and dequantization are implemented using NVFlare filters and added to the federated schemes, reducing the message size during transmission.
- Container and file streaming: Streaming capabilities are implemented on top of ObjectStreamer. We support two object types, containers and files, and developed an ObjectRetriever class for easier integration with existing code.
Message quantization: Reducing communication overhead
One of the major bottlenecks in FL is the exchange of model updates among remote participants and servers. The size of these messages can be prohibitively large, leading to increased latency and bandwidth consumption. Given that recent LLMs are trained with reduced precision, the default fp32 message precision under NumPy format can even be artificially inflating the message size.
In this case, we implemented two features: native tensor transfer and message quantization, offering an efficient messaging solution by enabling native training precision, as well as reducing the precision of transmitted updates and compressing the message size.
Figure 1 shows the implementation of quantization and dequantization with this filter mechanism. Quantization is performed over the outgoing model weights before transmission, and dequantization recovers the original precision upon receiving the message at the other end.
There are two benefits of such an implementation:
- No code change is needed from the user’s side. The same training script can be used with and without message quantization with a simple config setting
- Both training and aggregation are performed at the original precision, rather than quantized data, such that the potential impact message quantization can have over the training process is minimized.
We used direct cropping and casting to convert fp32 to fp16 and make use of bitsandbytes to perform 8– and 4-bit quantizations. With these new functionalities, we support both NumPy arrays (the previous default), and PyTorch Tensors directly for training LLMs.
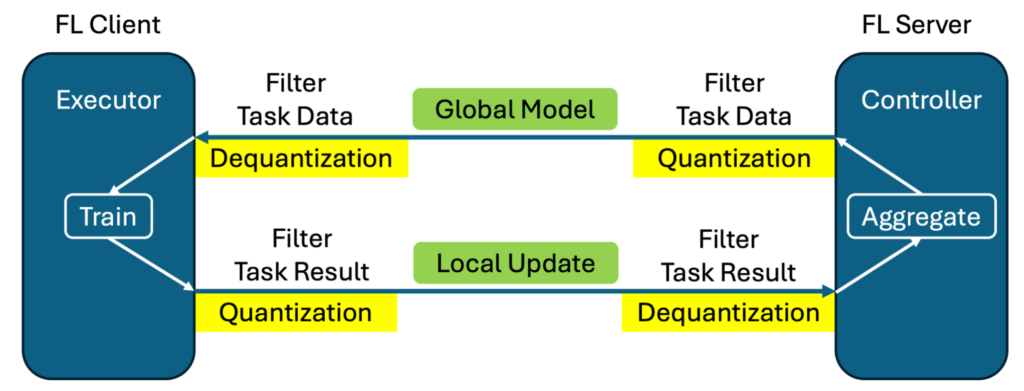
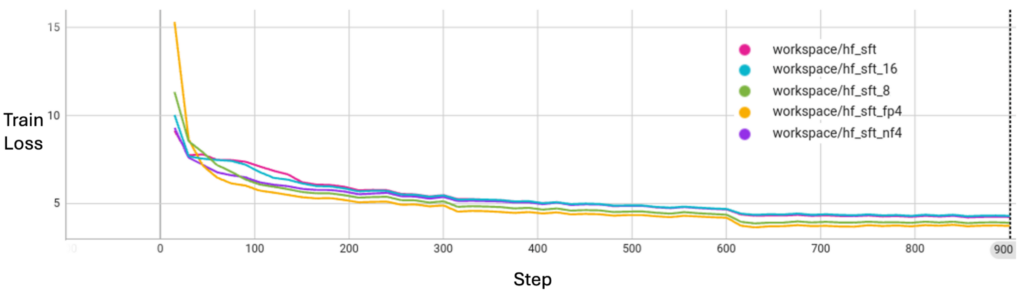
Table 1 shows the message size in MB for a 1B parameter LLM under different precisions. For more information about training loss curve alignments, see the LLM Tuning via HuggingFace SFT/PEFT APIs example.
| Precision | ModelSize (MB) | QuantizationMeta Size (MB) | fp32 SizePercentage |
| 32-bit (fp32) | 5716.26 | 0.00 | 100.00 % |
| 16-bit (fp16, bf16) | 2858.13 | 0.00 | 50.00 % |
| 8-bit | 1429.06 | 1.54 | 25.03 % |
| 4-bit (fp4, nf4) | 714.53 | 89.33 | 14.06 % |
By applying message quantization techniques, FL can achieve significant bandwidth savings and for training LLM with Supervised Fine-Tuning (SFT) in our experiments.
As shown in Figure 2, message quantization does not sacrifice model convergence quality with regard to training loss.
Streaming functionality: Reducing local memory usage
Another critical challenge in FL is the memory overhead for sending and receiving the messages.
Under the default setting, to send the model, you need additional memory to prepare and receive model chunks, that requires the local memory usage to be doubled. Extra memory must be allocated to hold the entire message for re-assembling the object, although the transmission itself is done by 1M chunks streaming.
Such memory overhead can be affordable with decent system capabilities and moderate model size, but when you are considering a 70B or larger parameter model, it can quickly drain the available system memory. A 70B model can have a size of 140 GB. To load and send it, you need 140 + 140 = 280 GB of memory.
Even though the entire LLM parameter dictionary can be huge, when breaking down to individual layers and items, the maximum size of each layer is far smaller, usually around 1 GB. The upgraded streaming functionality addresses the memory usage challenge by two new features:
- Object container streaming: Processing and transmitting model incrementally, rather than requiring the entire object to be stored in memory at one time. Container streaming serializes one item of an object (such as the dictionary holding model weights) at a time. For the earlier example of a 140-GB model with 1 GB item-max, compared with 280 GB if sending it as a whole, ContainerStreamer only needs 140 + 1 = 141 GB memory to load and send it.
- File streaming: Streaming a file rather than a structured object container. File streaming reads the file chunk-by-chunk and only consumes the memory required to hold one chunk of the data. The additional memory needed by FileStreamer is independent of the model size or max item size, and only relies on the file I/O setting, which can reduce the transmission memory usage to minimum and enable unlimited streaming. In this case, loading the model is not required, so you can choose to save on memory usage further, if needed.
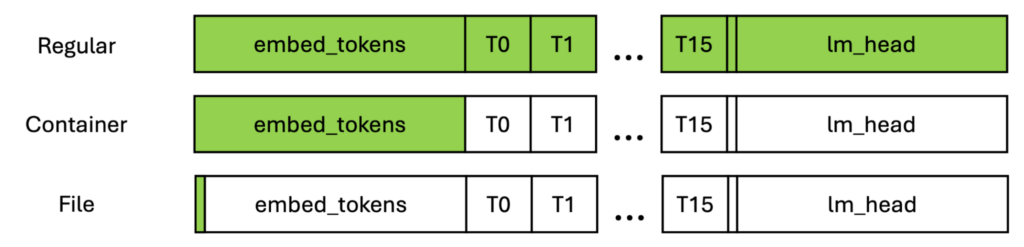
In Figure 3, the green boxes show the maximum local memory that must be allocated for the message transmission. As shown, regular transmission must allocate memory for the entire model, so it can be unlimited as the models grow bigger.
For an object container, the memory is only the same size as the largest layer, which is often bounded by the first and last layers. For files, the memory requirement is independent of the model structure and is configurable for any file.
By adapting streaming in FL, you can achieve memory efficiency by breaking down updates into smaller chunks and processing them sequentially. Streaming reduces the peak memory usage, making FL feasible while optimizing the computational resources.
With this solution, you can even achieve real-time processing, enabling devices to transmit partial updates while continuing computation, improving responsiveness and reducing idle time. On the receiving side, update strategies can also benefit from adaptive transmission where updates can be sent at varying granularity based on network conditions and client availability.
Table 2 shows the memory comparisons with a local simulation of one-time sending a 1B model. We recorded the system memory footprint and compared the peak memory usage of the three settings: regular, container streaming, and file streaming.
You can see that the memory usage is significantly reduced by using streaming, especially for file streaming. However, file streaming can take a longer time to finish the job due to file I/O efficiency.
| Setting | Peak Memory Usage (MB) | Job Finishing Time (sec) |
| Regular Transmission | 42,427 | 47 |
| Container Streaming | 23,265 | 50 |
| File Streaming | 19,176 | 170 |
Streaming enhancements are not yet integrated into the high-level APIs or existing FL algorithm controllers and executors. However, you can build custom controllers or executors following this streaming example to leverage this feature.
Summary
In this post, we demonstrated how to alleviate communication bottlenecks and memory constraints by integrating message quantization and streaming functionality into FL frameworks. With upgraded capabilities, we make federated learning more efficient and scalable. As these techniques continue to evolve, they will play a crucial role in enabling real-world deployment of FL across diverse environments.
For more information, see the following resources:
- /NVFlare tutorials on GitHub
- /NVIDIA/NVFlare quantization examples on GitHub
- /NVIDIA/NVFlare streaming examples on GitHub
- NVIDIA FLARE Developer Portal
- Federated Learning in Medical Imaging: Enhancing Data Privacy and Advancing Healthcare GTC 2025 session
To connect with the NVIDIA FLARE team, contact federatedlearning@nvidia.com.
