
In the ever-evolving landscape of large language models (LLMs), effective data management is a key challenge. Data is at the heart of model performance. While most advanced machine learning algorithms are data-centric, necessary data can’t always be centralized. This is due to various factors such as privacy, regulation, geopolitics, copyright issues, and the sheer effort required to move vast datasets.
This post explores how federated learning (FL) enabled by NVIDIA FLARE can address these challenges with easy and scalable integration. These capabilities enable both supervised fine-tuning and parameter-efficient fine-tuning of LLMs to enhance their accuracy and robustness.
The data challenge
The need to access data from multiple sources is a common scenario in many LLM tasks. Consider gathering reports from different hospitals for medical research or collecting financial data from diverse institutions for analysis. Centralizing such data may be impractical and hindered by privacy concerns, regulations, and other hurdles. Federated learning offers an elegant solution.
Federated learning
FL has emerged as a technology to address these data challenges. This approach bypasses model training with centralized data by sharing models instead of raw data. Participating clients train models using their private datasets locally, and the updated model parameters are aggregated globally.
This preserves the privacy of the underlying data while enabling the global model to collectively benefit from the knowledge gained during the training process. This results in more robust and generalizable models. For a specific example, see Federated Learning for Predicting Clinical Outcomes in Patients with COVID-19.
FL offers various options for training AI models. In general, FL enables training a global model while preserving data privacy and governance. The training can be further customized for each client, providing personalized models. Beyond training, the FL infrastructure can also be employed for inference and federated evaluation.
Foundation models
Foundation models are pretrained on a vast amount of general text data. However, they may not be specialized for specific domains or downstream tasks. Further fine-tuning enables these models to adapt and specialize for particular domains and tasks, making them more effective and accurate in delivering domain- and task-specific results. This is essential for harnessing their potential and adapting them to the diverse and evolving needs of various applications.
Fine-tuning techniques
Supervised fine-tuning (SFT) and parameter-efficient fine-tuning (PEFT) are two approaches that aim to tailor foundation models to specific domains and tasks efficiently and effectively. Both achieve domain and task-specific adaptation based on foundation models.
SFT fine-tunes all LLM parameters. PEFT attempts to add adaptation parameters or layers while keeping the LLM parameters fixed, making it a cost-effective and resource-efficient option. Both techniques play a pivotal role in harnessing the power of LLMs for a wide range of applications, offering tailored and resource-aware solutions.
FL for LLM adaptations
As with other AI techniques, LLM performance benefits from larger and more diverse datasets. More data usually translates to better accuracy, improved robustness, and generalizability.
As shown in Figure 1, using PEFT, the parameters of the foundation LLMs are frozen and remain fixed during training and evaluation, while additional parameters are injected for customization. Hence, only these parameters are tuned at local clients, and aggregated at a global level. Using SFT, on the other hand, the entire LLM is fine-tuned, and all parameters are used for aggregation.
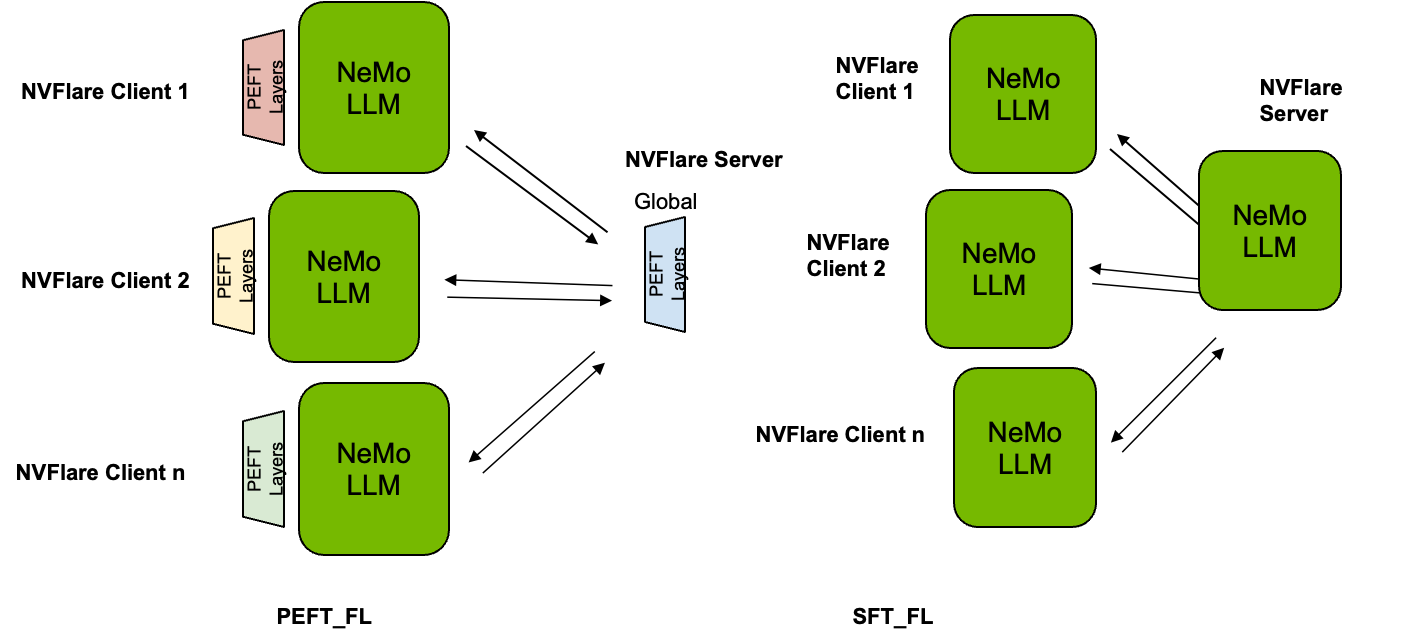
Easy adaptation using Lightning Client API
To showcase the application of PEFT and SFT in this post, we are using the GPT model from NVIDIA NeMo. NeMo leverages PyTorch Lightning for model training. One notable feature of NVIDIA FLARE 2.4 is the Lightning Client API, which significantly simplifies the process of converting local training scripts to run in FL scenarios. With just a few lines of code changes, you can seamlessly integrate methods like PEFT and SFT.
As shown below, the Lightning trainer can be adapted to run FL by calling flare.patch(trainer). Next, an extra while loop (while flare.is_running:) is added to allow reusing the same trainer object each round of FL. Optionally, call trainer.validate(model) to evaluate the global model received from the FL server at the current round on the client’s data. This is useful for enabling global model selection on the server based on validation scores received from each client.
from nemo.core.config import hydra_runner
from nemo.utils import logging
from nemo.utils.exp_manager import exp_manager
mp.set_start_method("spawn", force=True)
# (0): import nvflare lightning api
import nvflare.client.lightning as flare
# (1): flare patch
flare.patch(trainer)
# (2): Add while loop to keep receiving the FLModel in each FL round.
# Note, after flare.patch the trainer.fit/validate will get the
# global model internally at each round.
while flare.is_running():
# (optional): get the FL system info
fl_sys_info = flare.system_info()
print("--- fl_sys_info ---")
print(fl_sys_info)
# (3) evaluate the current global model to allow server-side model selection.
print("--- validate global model ---")
trainer.validate(model)
# (4) Perform local training starting with the received global model.
print("--- train new model ---")
trainer.fit(model)
Scalable model training through streaming
The size of mainstream LLMs can be enormous, ranging from a few billion parameters to tens of billions of parameters, which leads to a significant increase in model sizes. As SFT fine-tunes the entire network, the whole model needs to be transferred and aggregated. To enable SFT with recent LLMs in FL, this transmission challenge needs to be properly addressed.
NVIDIA FLARE 2.4 facilitates the streaming of large files. Leveraging this capacity to communicate large amounts of data enables LLM SFT under an FL setting.
Federated PEFT and SFT performance
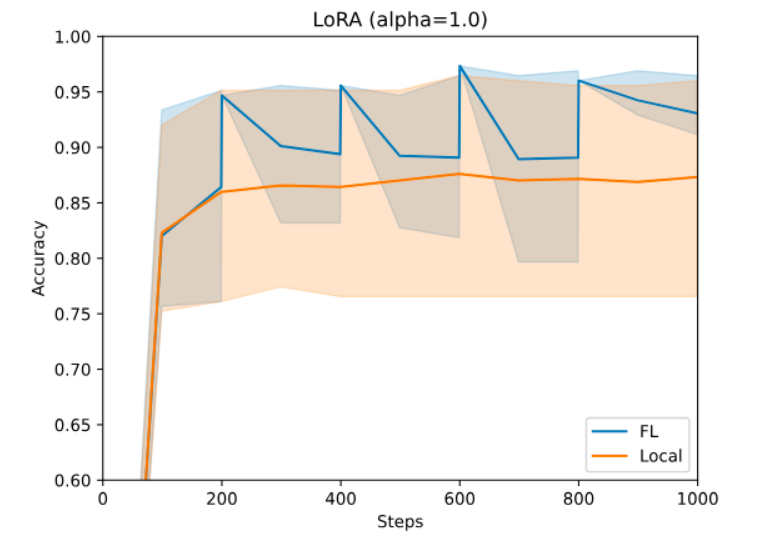
For PEFT, you can use NeMo PEFT methods. With a single line of configuration change, you can experiment with various PEFT techniques, such as p-tuning, adapters, or LoRA, all of which introduce a small number of trainable parameters to the LLM. These parameters condition the model to generate the desired output for the downstream task. Figure 3 illustrates the accuracy as the LoRA runs progress with a NeMo Megatron-GPT2 345M model on a financial sentiment prediction task using LoRA.
Use a Dirichlet sampling strategy for creating a heterogeneous partition, as detailed in Federated Learning with Matched Averaging. Here, none of the sites can achieve the required performance with local data alone. However, they can collaborate using FL and get better-performing models due to effectively using larger datasets but without losing privacy and governance over their data. For more details, visit NVIDIA/NVFlare on GitHub.
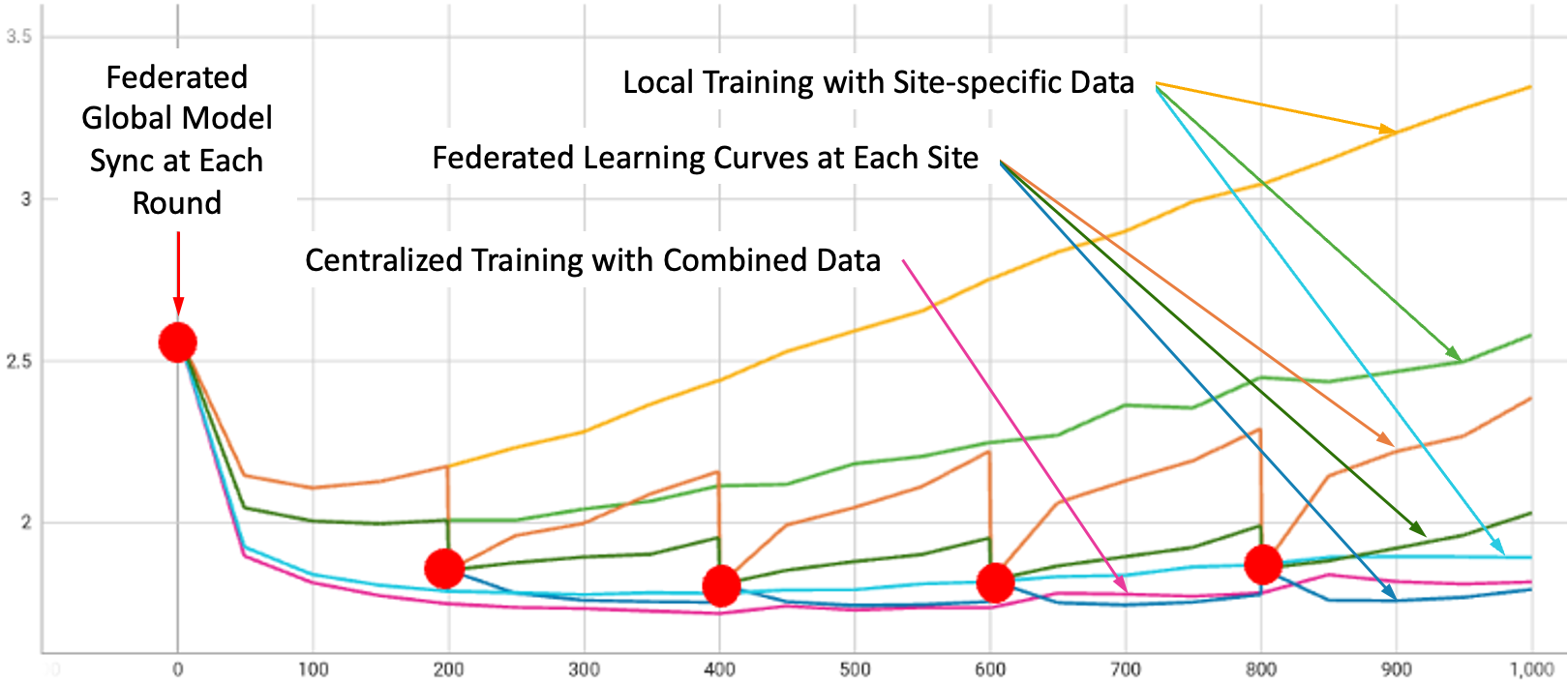
For SFT, we conducted experiments using the NeMo Megatron-GPT 1.3B model for five rounds, training on three open datasets (Alpaca, databricks-dolly-15k, and OpenAssistant Conversations), one for each client.
Figure 3 illustrates the validation curves under all experiment settings: local-only training on each of the three datasets, on a combined dataset, and FL with all three clients training together using the FedAvg algorithm. Smooth curves represent local training, while step curves, identified by red dots, are for FL. The steps are due to global model aggregation and update at the beginning of each FL round.
Evaluating LLMs can be a nontrivial task. Following popular benchmark tasks, we performed three language modeling tasks under zero-shot settings, including HellaSwag (H), PIQA (P), and WinoGrande (W). Table 1 shows the results of each SFT model, with BaseModel representing the model before SFT.
As shown, FL can help achieve the best overall performance as compared with training on individual sites’ data by combining updates from diverse sources.
| H_acc | H_acc _norm | P_acc | P_acc _norm | W_acc | Mean | |
| BaseModel | 0.357 | 0.439 | 0.683 | 0.689 | 0.537 | 0.541 |
| Alpaca | 0.372 | 0.451 | 0.675 | 0.687 | 0.550 | 0.547 |
| Dolly | 0.376 | 0.474 | 0.671 | 0.667 | 0.529 | 0.543 |
| Oasst1 | 0.370 | 0.452 | 0.657 | 0.655 | 0.506 | 0.528 |
| Combined | 0.370 | 0.453 | 0.685 | 0.690 | 0.548 | 0.549 |
| FedAvg | 0.377 | 0.469 | 0.688 | 0.687 | 0.560 | 0.556 |
Conclusion
NVIDIA FLARE and NVIDIA NeMo facilitate the easy, scalable adaptation of LLMs with popular fine-tuning schemes, including PEFT and SFT using FL. Two major features take center stage: the Client API and the capacity for large file streaming. FL offers the potential for collaborative learning to preserve privacy and enhance model performance.
FL presents exciting prospects for adapting foundation LLMs and addressing data challenges in a privacy-conscious world. Fine-tuning techniques, designed to tailor foundation LLMs for various domains and tasks, can be readily applied in FL settings and benefit from the larger availability of more diverse data. NVIDIA FLARE provides communication support to facilitate collaborative LLM training.
These techniques, combined with advancements in model development, pave the way for more versatile and efficient LLMs. For more information, check out these resources:
