
In the era of big data and distributed computing, traditional approaches to machine learning (ML) face a significant challenge: how to train models collaboratively when data is decentralized across multiple devices or silos. This is where federated learning comes into play, offering a promising solution that decouples model training from direct access to raw training data.
One of the key advantages of federated learning, which was initially designed to enable collaborative deep learning on decentralized data, is its communication efficiency. This same paradigm can be applied to traditional ML methods such as linear regression, SVM, k-means clustering, and tree-based methods like random forest and boosting.
Developing a federated-learning variant of traditional ML methods requires careful considerations that must be made at several levels:
- Algorithm level: You must answer crucial questions such as what information clients should share with the server, how the server should aggregate the collected information, and what clients should do with the global aggregated model updates received from the server.
- Implementation level: It’s essential to explore available APIs and harness them to create a federated pipeline that aligns with the algorithm formulation.
It’s worth noting that the line between federated and distributed machine learning can be less distinct for traditional methods compared to deep learning. For some algorithms and implementations, these terms can be equivalent.
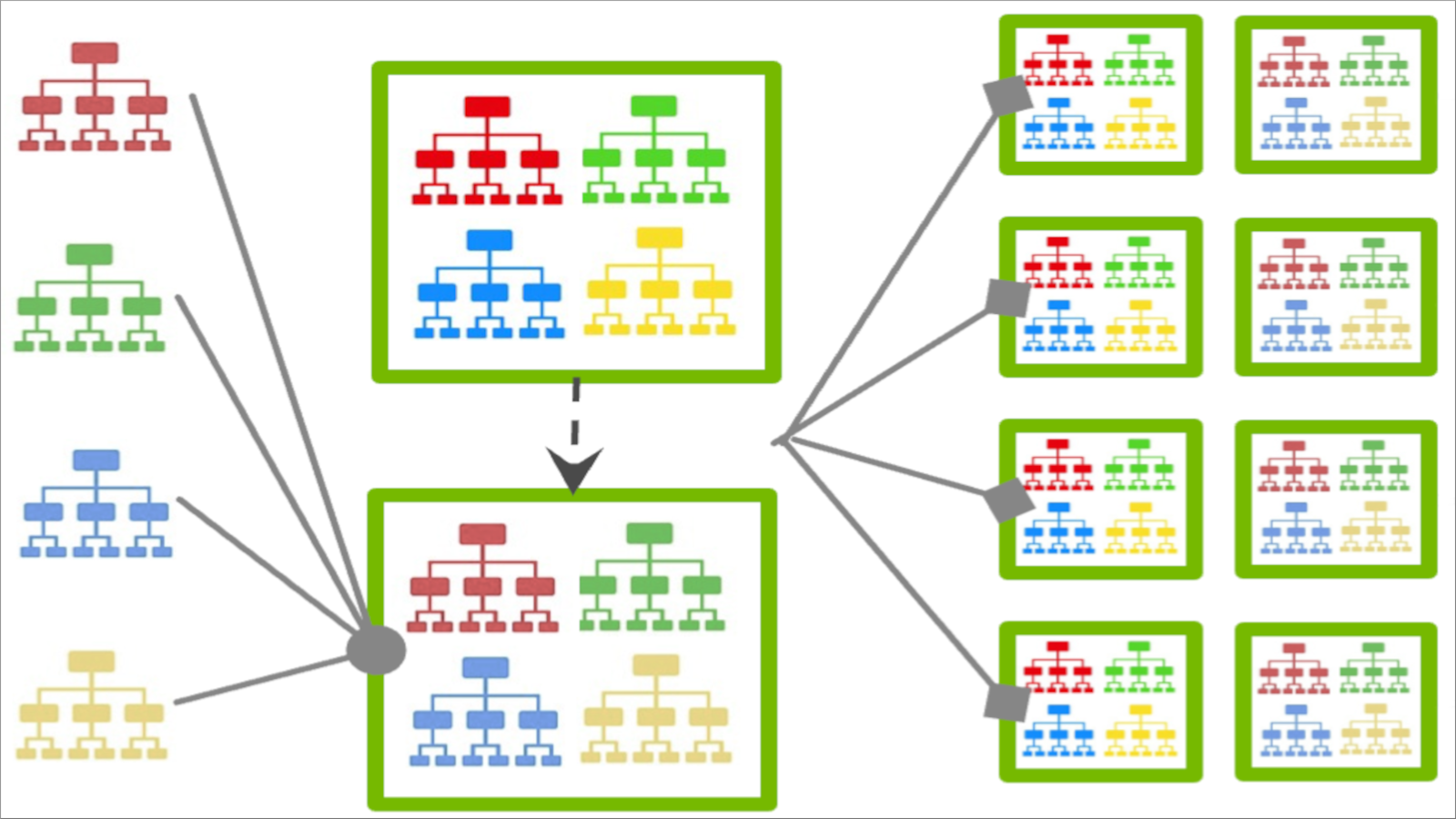
In Figure 1, each client builds a unique boosted tree that is aggregated by the server as a collection of trees and then redistributed to clients for further training.
To get started with a specific example that shows this approach, consider the k-means clustering example. Here we followed the scheme defined in Mini-Batch K-Means clustering and formulated each round of federated learning as follows:
- Local training: Starting from global centers, each client trains a local MiniBatchKMeans model with their own data.
- Global aggregation: The server collects the cluster center, counts information from all clients, aggregates them by considering each client’s results as a mini-batch, and updates the global center and per-center counts.
For center initialization, at the first round, each client generates its initial centers with the k-means++ method. Then, the server collects all initial centers and performs one round of k-means to generate the initial global center.
From formulation to implementation
Applying a federated paradigm to traditional machine learning methods is easier said than done. The new NVIDIA whitepaper, Federated Traditional Machine Learning Algorithms, provides numerous detailed examples to show how to formulate and implement these algorithms.
Employing popular libraries like scikit-learn and XGBoost, we showcase how federated linear models, k-means clustering, non-linear SVM, random forest, and XGBoost can be adapted for collaborative learning.
In conclusion, federated machine learning offers a compelling approach to training models collaboratively on decentralized data. While communication costs may no longer be the principal constraint for traditional machine learning algorithms, careful formulation and implementation are still necessary to fully leverage the benefits of federated learning.
To get started with your own federated machine learning workflows, see the Federated Traditional Machine Learning Algorithms whitepaper and the NVIDIA FLARE GitHub repo.