Federated learning (FL) is experiencing accelerated adoption due to its decentralized, privacy-preserving nature. In sectors such as healthcare and financial services, FL, as a privacy-enhanced technology, has become a critical component of the technical stack.
In this post, we discuss FL and its advantages, delving into why federated learning is gaining traction. We also introduce three key features introduced in NVIDIA FLARE 2.4.0 release that facilitate a seamless transition from centralized machine learning to federated learning. These features also enhance large language model (LLM) support through a streaming API and demonstrate various parameter tuning tasks.
The latest version of FLARE has expanded FL workflow patterns, providing researchers with more options for workflow customization. We share different use cases in healthcare and banking, financial services, and insurance (BFSI) to show FL applications in production or through examples.
Federated learning in the age of decentralized data
FL is a machine-learning approach that enables model training and data analysis across decentralized devices while keeping local data private. In contrast to traditional centralized training, FL enables model training locally and only shares model updates rather than raw data. This approach enables collaborative learning without compromising data governance and privacy.
While FL introduces challenges like communication overhead and ensuring model consistency, it offers significant benefits in terms of privacy preservation, efficiency, and security.
NVIDIA FLARE (NVIDIA Federated Learning Application Runtime Environment) is an open-source federated learning framework widely adopted across various industrial sectors. It offers diverse examples covering machine learning and deep learning algorithms. FLARE has robust security features, advanced privacy protection techniques, and provides a flexible model-agnostic architecture.
FLARE offers several advantages across various dimensions, making it a powerful approach in scenarios where data is distributed and privacy is a primary concern.
With increased concerns about data privacy regulation and the need for more data to train a better machine learning model, the interest and investments in privacy enhancement technology (PET), including FL and confidential computing, have increased dramatically in recent years.
Here are some key advantages:
- Privacy preservation
- Data diversity
- Regulatory compliance
- Security
Privacy preservation
Models are trained locally. In FLARE, only model updates or model differences are shared, while the private data is kept on the client. Aggregation happens securely to protect against information leakage during model updates.
Data diversity
Data diversity among clients is critical for robust model development. This diversity, especially including data from rare events, prevents bias and enables the model to learn effectively with FLARE.
Regulatory compliance
Increasingly, organizations and governments issue regulations to protect data privacy. Examples include the European Union’s General Data Privacy Regulation (GDPR) and China’s Personal Information Protection Law (PIPL). These regulations restrict data transfers from one region to another.
In addition, there are also industry-specific laws and regulations, such as HIPAA (Health Insurance Portability and Accountability Act) for healthcare, that avoid revealing users’ personal data. As FLARE brings the computation to the data without moving data, it becomes the key to enable AI initiatives to avoid violating these regulations.
Security
FLARE offers decentralized security enforcement. Local institutions (banks, hospitals, and so on) can elect to add additional organization-specific security checks or policies
Federated learning made easy with NVIDIA FLARE
How to quickly leverage FL and build multi-modal foundation models with LLM has become a hot topic in many governments, financial institutions, healthcare, and drug-discovery industries.
In the FLARE 2.4.0 release, we introduce new features that make developing FL super easy, including a client API. With a few lines of code changes, you can easily transform pre-existing, centralized deep-learning code into FL code, in minutes instead of days.
The following code example shows a common pattern when using the client API for a client trainer:
# import nvflare client API
import nvflare.client as flare
# initialize NVFlare client API
flare.init()
# run continuously when launching once
while flare.is_running():
# receive FLModel from NVFlare
input_model = flare.receive()
# loads model from NVFlare
net.load_state_dict(input_model.params)
# perform local training and evaluation on received model
{existing centralized deep learning code} ...
# construct output FLModel
output_model = flare.FLModel(
params=net.cpu().state_dict(),
metrics={"accuracy": accuracy},
meta={"NUM_STEPS_CURRENT_ROUND": steps},
)
# send model back to NVFlare
flare.send(output_model)
The key to understanding these easy-to-use APIs is that almost all FL algorithms essentially involve the following steps:
- Receive the global model from the aggregator or a peer client.
- (Optional) Evaluate the model.
- Update the local model, and perform local model training with many epochs.
- Send the newly updated local model back to the aggregator or other peer clients.
The FLARE client API easily implements these actions:
flare.init: Initialization.flare.receive: Receive the model.flare.send: Send the model back.flare.is_running: Check whether the overall training is finished.
With these APIs, you don’t have to restructure the existing code or write new classes. The code conversion can be done in minutes by inserting the API commands in the relevant sections of your existing code.
For PyTorch Lightning, the change is even simpler. Apply a patch to the trainer instances:
flare.patch(trainer): Adds callbacks to the trainer to perform theflare.receiveandflare.sendfunctions.
The model can be captured in the data structure, FLModel.
class FLModel:
def __init__(
self,
params_type: Union[None, str, ParamsType] = None,
params: Any = None,
optimizer_params: Any = None,
metrics: Optional[Dict] = None,
start_round: Optional[int] = 0,
current_round: Optional[int] = None,
total_rounds: Optional[int] = None,
meta: Optional[Dict] = None,
):
The data structure is carefully designed and general purpose. It does not introduce any FLARE-specific concepts or structures but only contains concepts that data scientists already know:
params: Weight parametersoptimizer_params: Optimizer parametersmeta: Metadata.
This new client API, simplifying the transition to FL, is a game changer for end users.
For more information about the client API and its use, see the ML to FL examples and read the client API documentation. For more examples, see the step-by-step series that uses client API to write the train script.
Federated learning in the age of LLMs
The defining feature of LLMs is their sheer size, often comprising billions of parameters. Federated learning requires that users to transmit their local model parameters to a model aggregator, potentially situated in a different region or country, to construct a global model. Efficiently transferring such a massive model over a network demands a robust framework. To address this challenge, FLARE has developed a stream API tailored for such tasks.
Streaming API
LLMs can be large in size. For example, a 7B-parameter model can be approximately 14 GB. To transfer such large objects over the network, you must overcome some limitations imposed by different communication protocols.
To support LLMs, the FLARE 2.4.0 release introduces the streaming API to facilitate the transfer of objects exceeding the 2-GB size limit imposed by gRPC. The addition of a new streaming layer designed to handle large objects enables you to divide the large model into 1M chunks and stream them to the target.
With this streaming API, you can transfer models of varying sizes across regions (such as US to India) and diverse cloud providers (such as Azure to AWS). We used a 128-GB object to perform a load test.
For more information, see nvflare.fuel.f3.stream_cell module and Large Models.
Federated LLM parameter tuning
The FLARE 2.4.0 release showcases several LLM examples using NVIDIA NeMo, demonstrating how to perform prompt-tuning, supervised fine-tuning, and parameter-efficient fine-tuning in a federated setting.
Prompt-tuning
Prompt tuning is a technique used in training language models, particularly in fine-tuning them for specific tasks or domains. Instead of training the entire model from scratch, prompt tuning focuses on adjusting the prompts or instructions given to the model during inference or generation.
Federated prompt-tuning enables users to conduct prompt-tuning of the model on a local level and then aggregate the parameters globally.
In this example, we used the NeMo prompt learning feature to showcase how to adapt an LLM to a downstream task, such as financial sentiment predictions. The prompt learning technique shown in the example is p-tuning, which adds a small prompt encoder network to the LLM to produce virtual tokens that guide the model toward the desired output of the downstream task.
For more information, see Prompt Learning with NeMo.
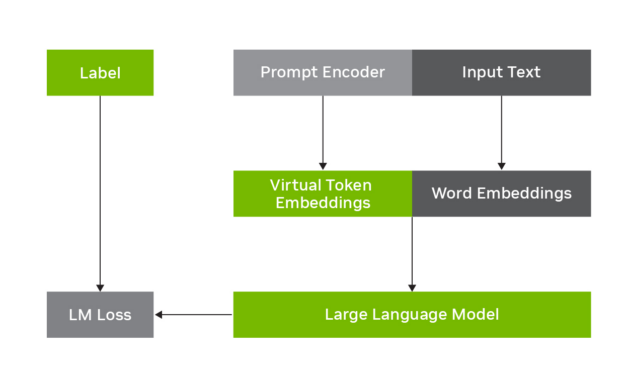
Figure 1 shows how the p-tuning works for adaptation of LLMs. It involves freezing the LLM and learning to predict virtual token embeddings that are combined with the original input text.
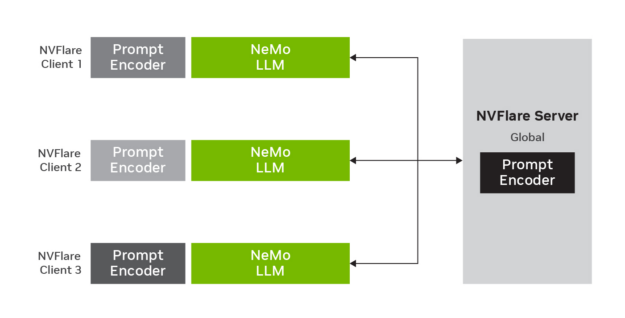
Figure 2 shows how p-tuning works with LLM in a federated learning setting. LLM parameters stay fixed but prompt encoder parameters are trained, updated, and aggregated on the FLARE server.
In this example, we used the NeMo prompt learning feature to showcase how to adapt an LLM to a downstream task, such as financial sentiment predictions. The prompt learning technique shown in the example is p-tuning, which adds a small prompt encoder network to the LLM to produce virtual tokens that guide the model toward the desired output of the downstream task.
In our federated implementation, we used a 20B-parameter model. While the LLM parameters stay fixed, the prompt encoder parameters are trained, updated, and averaged on the FL server.
Supervised fine-tuning
We also used the NeMo supervised fine-tuning (SFT) feature to showcase how to fine-tune the whole model on supervised data to learn how to follow user-specified instructions. For more information, see Supervised Fine-Tuning.
The example for a three-client 1.3B GPT model experiment can be performed on either three 32 -GB NVIDIA V100 GPUs or one 80-GB NVIDIA A100 GPU.
Due to the large model size of the LLM, we use the FLARE streaming feature to transfer the model in chunks.
Parameter-efficient fine-tuning
Parameter-efficient fine-tuning (PEFT) is a popular technique used to efficiently fine-tune LLMs for use in various downstream tasks.
When fine-tuning with PEFT, the base model weights are frozen, and a few trainable adapter modules are injected into the model, resulting in a small number (typically << 1%) of trainable weights.
With carefully chosen adapter modules and injection points, PEFT achieves comparable performance to full finetuning at a fraction of the computational and storage costs. We used NeMo PEFT methods to showcase how to adapt an LLM to a downstream task, such as financial sentiment predictions.
For more information, see Parameter-Efficient Fine-Tuning (PEFT) with NeMo.
SFT and PEFT
We also demonstrated both SFT and PEFT using the SFT Trainer from HuggingFace and the PEFT library. For more information, see Federated LLM SFT and PEFT with Hugging Face.
Our experiments showcasing the functionality of federated SFT and PEFT are based on the Llama-2-7b-hf model, enabling HuggingFace models to be trained and adapted with FLARE.
In this example, the model transmission size over the FLARE network is ~27 GB for SFT and ~134 MB for PEFT. The larger model is automatically streamed without having to call the streaming API manually.
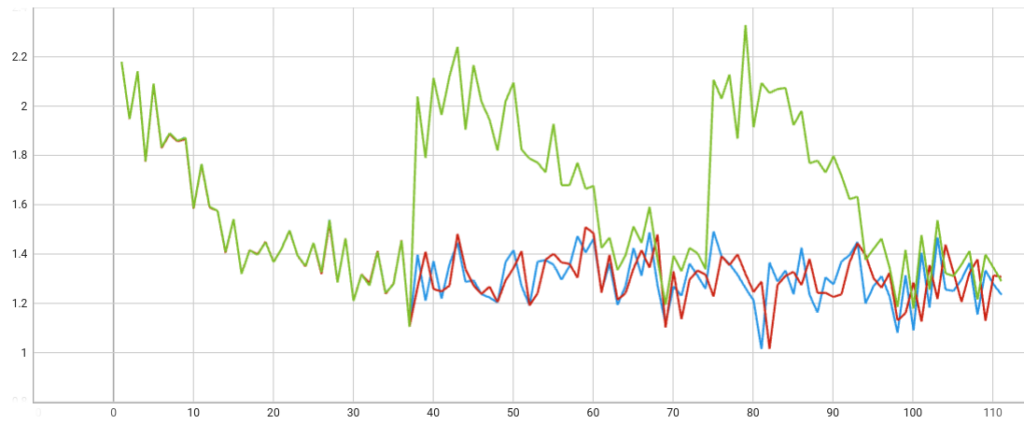
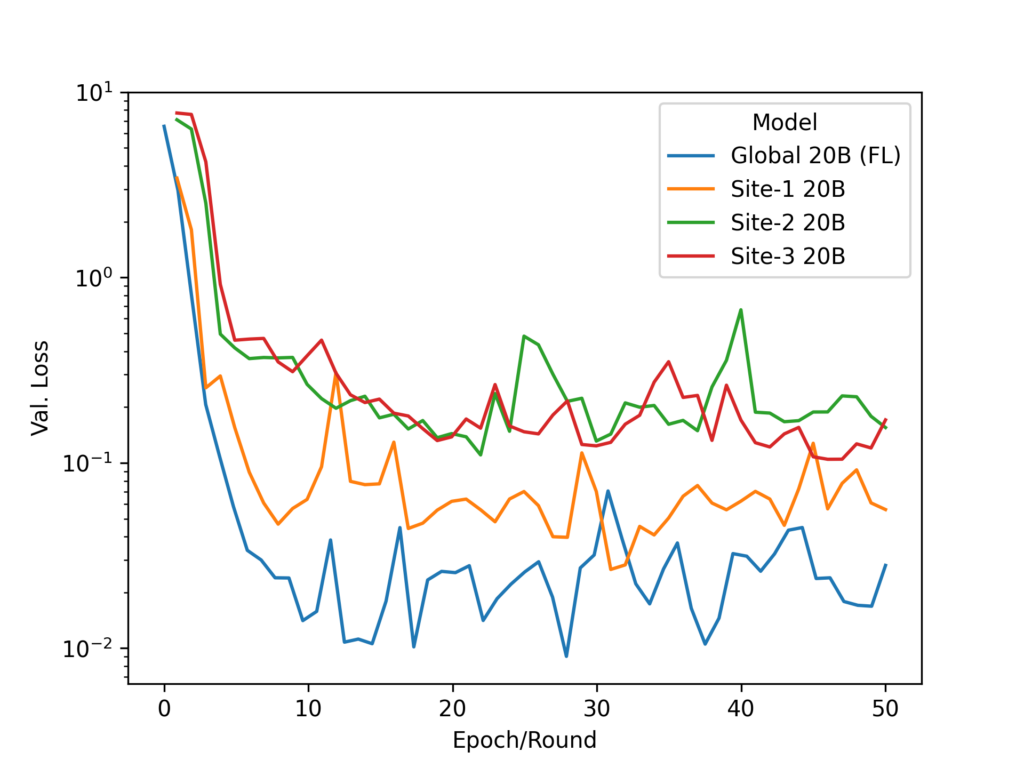
To ensure the correct behavior of FLARE integrating with HuggingFace’s trainer, we performed single-client experiments under three settings (Figure 4):
- Local training for three epochs (red)
- Using FLARE for three federation rounds with one epoch per round (blue)
- Using FLARE for three federation rounds but with a fixed global model sent back every round (green)
As expected, with some training randomness, the two PEFT training loss curves align with each other.
As the HuggingFace trainer keeps track of training status of the model, we wanted to make sure that the global model from the server was loaded correctly, rather than re-using the local record). As shown, the correct fixed global model is loaded correctly. The training starts from the same point every round, showing the expected federated learning behavior.
Expanding federated learning workflow patterns
Some researchers prefer alternative workflow patterns to the FL workflow described earlier. For example, swarm learning is considered a decentralized peer-to-peer collaboration learning pattern alternative to FL. Similarly, split learning and gossip learning are alternative communication patterns to FL.
Among other things, here are some key difference between these alternative communication patterns:
- An emphasis on decentralized and peer-to-peer communication.
- No static server for model aggregation.
- Client communication is peer-to-peer communication.
- Algorithm workflows differ:
- Aggregator selection
- Client sampling and distribution (gossip protocol compared to broadcast-to-all)
When you look closer, “no central server” really means “no static aggregator node”. In most cases, the aggregator node is located at the FL server node.
In many FL frameworks, the server services two functions:
- Managing the job lifecycle (health of client sites, monitoring of job status).
- Serving as an aggregator that participates in the training process (task assignment, model initialization, aggregation, and obtaining the distributed final model).
By separating these two functions in FLARE and enabling direct peer-to-peer communication, the workflow patterns can support both swarm learning and gossip learning.
The aggregator function doesn’t have to be located in the FL server. You can put it into any client node. This essentially decentralizes the aggregation. You only need the FL server for job lifecycle management.
In the 2.4.0 release, we introduced client-controlled workflows to enable such capability.
Secure messaging
Peer-to-peer clients exchange messages using TLS encryption where the sender uses the public key of the receiver from certificates received, and encrypts messages with AES256 key. Only the sender and client can view the message.
In the case where there is no direct connection between clients and the message is routed via the server, the server is unable to decrypt the message.
The following commonly used types of client-side controlled workflows are provided:
- Cyclic learning: Passes the model from client to client.
- Swarm learning: Randomly selects clients as client-side aggregators.
- Cross-site evaluation: Enables clients to evaluate other sites’ models.
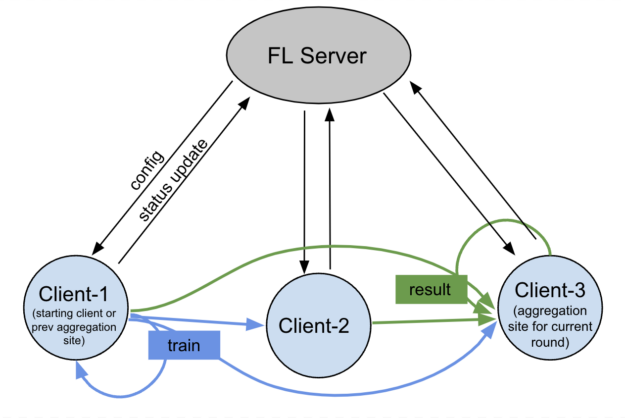
In Figure 5, the FL server triggers the start of the training job, while monitoring the overall job lifecycle. The communication is peer-to-peer among different clients without the FL server’s involvement.
Some would like to use the blockchain network as the communication layer for swarm learning, but this is not a requirement of swarm learning. The key is to make sure the aggregator is unable to decipher the message if the message is routed through the FL server.
Federated learning is transforming multiple industry sectors
FL has been adopted at an accelerated speed, transforming multiple industry sectors, such as healthcare and BFSI.
Healthcare
In healthcare, FL is used for medical image analysis, predicting clinical outcomes, and many other applications.
The FLIP project from the UK AI Centre for Value Based Healthcare, led by King’s College London, is powered by FLARE. FLIP is being deployed in at least five NHS trusts serving over 10M patients in early 2023. The first projects using FLIP include research into AI that can diagnose strokes from head CT scans, an algorithm that can help radiologists detect and diagnose prostate cancer and software that uses AI to reduce the time of cardiac MRI scans.
Rhino Health, a federated computing company, is powered by FLARE to enable the transformative power of federated computing. For more information, see Federated Learning for Healthcare AI: NVIDIA and Rhino Health Accelerate Research Collaborations (video).
Roche is a leading pharmaceutical and diagnostics company with a focus on advancing medical science to improve people’s lives. It realizes the power of FL and has been adopting and working with NVIDIA to improve all aspects of FL. For more information, see Preventing Health Data Leaks with Federated Learning Using NVIDIA FLARE.
Siemens Healthineers is a prominent medical technology company that specializes in providing advanced solutions for medical imaging, laboratory diagnostics, and in-vitro diagnostics. It has developed its federated learning solution using FLARE and Azure ML.
Banking, financial services, and insurance
With each country and region developing new AI strategies, FL becomes a necessity.
A pivotal application within BFSI involves fraud detection. The model, collectively built, based on the insights derived from varied customer profiles and credit histories across different banks or institutions, all without necessitating the exchange of raw data. This challenge is particularly pronounced for institutions with internal business practices bound by stringent privacy laws or regulations.
Based on the recently published State of AI in Financial Services: 2024 Trends, fraud detection is among the top AI use cases in the investing sector and one of the top security challenges in financial service organizations (Figure 6).


Fraud detection stands as one of the paramount applications in financial services. With an overwhelming expectation (51%) that AI technology can effectively combat fraud, the integration of FL with zero-trust confidential computing emerges as a critical approach to addressing these challenges and delivering robust solutions.
In NVFlare 2.4.0, we’ve developed several examples showcasing the use of FL:
- Fraud detection using XGBoost with Kaggle’s Credit Card Fraud Detection dataset
- Financial transaction classification employing Graph Neural Networks (GNN)
Summary
FL is experiencing rapid growth. FLARE has developed a suite of features to help companies adopt this new technology. You can find a lot more features than we had room to discuss in this post.
The new FLARE features, in addition to those mentioned earlier:
- Experiment tracking support for MLFlow and Weights & Biases
- Secure enhancements to enable site-specific customized authentication and authorization
- Multi-format configuration
- Third-party integration patterns
- Job CLI and job templates
- POC command upgrade
- Step-by-step series examples
NVIDIA has made it a lot easier to convert your existing ML/DL to FL, supercharge LLM training, and expand the workflow patterns.
For more information, see the following resources:
