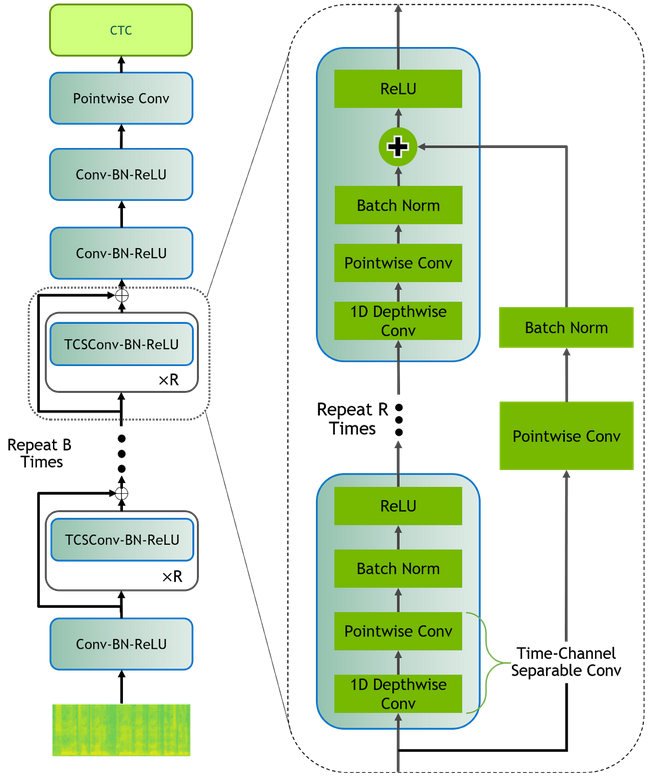
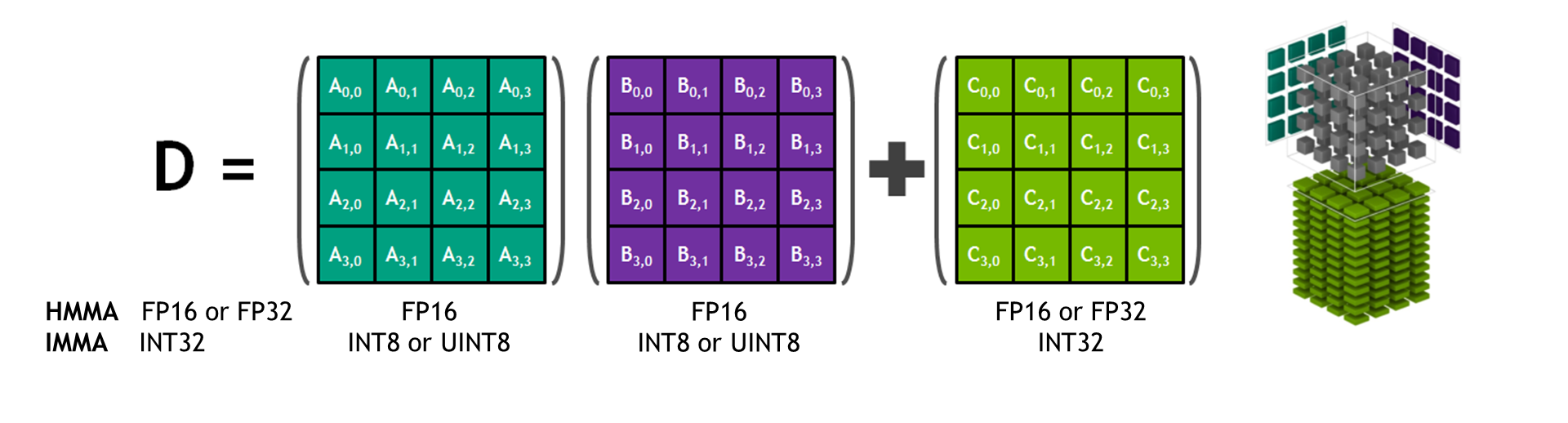
Dec 03, 2018
NVIDIA Apex: Tools for Easy Mixed-Precision Training in PyTorch
Most deep learning frameworks, including PyTorch, train using 32-bit floating point (FP32) arithmetic by default. However, using FP32 for all operations is not...
8 MIN READ