
Large language models (LLMs) are transforming the AI landscape with their profound grasp of human and programming languages. Essential for next-generation enterprise productivity applications, they enhance user efficiency across tasks like programming, copy editing, brainstorming, and answering questions on a wide range of topics.
However, these models often struggle with real-time events and specific knowledge domains, leading to inaccuracies. Fine-tuning these models can enhance their knowledge, but it’s costly and requires regular updates.
Retrieval-augmented generation (RAG) offers a solution by combining information retrieval with LLMs for open-domain question-answering applications. RAG provides LLMs with vast, updatable knowledge, effectively addressing these limitations (Figure 1). NVIDIA NeMo Retriever, the latest service in the NVIDIA NeMo framework, optimizes the embedding and retrieval part of RAG to deliver higher accuracy and more efficient responses.
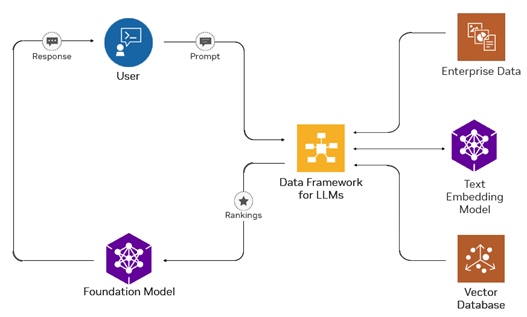
This post provides an overview of how RAG pipeline components work and the enterprise challenges associated with creating RAG-enabled AI applications, such as commercial viability. You will learn about NeMo Retriever, which includes production-ready components for enterprise RAG pipelines, and the model we are sharing today.
A canonical RAG pipeline
RAG applications typically have multiple stages, from embedding to retrieval and response. Let’s look at the canonical RAG pipeline to understand how the NeMo Retriever can help.
Encoding the knowledge base (offline)
In this phase, the knowledge base, typically consisting of documents in text, PDF, HTML, or other formats, is fragmented into chunks. These chunks are then fed to an embedding deep learning model, which produces a dense vector representation for each chunk.
The resulting embeddings, along with their corresponding documents and other metadata, are stored in a vector database (Figure 2). The chunking strategy depends on the type and content of documents, the use of metadata (such as document details), and the method of generating synthetic data if applicable. It must be carefully considered when developing a retrieval system.

The embeddings can be used for semantic search, by calculating the similarity (for example, dot product) between embeddings from a user’s query and those of the documents stored in the database. Vector databases are specialized in storing vast amounts of vectorized data and can perform fast approximate nearest-neighbor searches.
Deployment (online)
This stage focuses on deployment when the vector database is connected to the LLM application so it can answer questions in real time. It has two phases—retrieval from the vector database and generating a response.
Phase 1. Retrieval from vector database based on the user’s query
The user’s query is first embedded as a dense vector. Typically, a special prefix is added to the query, so that the embedding model used by the retriever can understand that it is a question. This enables asymmetric semantic search, where a short query can be used to find a longer paragraph that answers the query.
Next, the query embedding is used to search a vector database that retrieves a small number of the most relevant document chunks to the user’s query (Figure 3).

The vector database achieves this by employing a similarity/distance measure, such as cosine similarity, with an approximate search algorithm. This guarantees scalability and low latency.
Phase 2. Use an LLM to generate a response leveraging the context
In this phase, the most relevant chunks are combined to form a context, which is then combined with the user’s query as the final input for the LLM. The prompt usually contains extra instructions to guide the LLM to generate the response based on the context only. Figure 4 illustrates this response generation process.

Challenges of building a RAG pipeline for enterprise applications
While RAG offers significant advantages over an LLM by itself, it’s important to note that its benefits come with several challenges that must be addressed. One major issue is finding a commercially viable retriever, often constrained by licensing restrictions in training datasets like MSMARCO. Real-world queries further complicate matters with their ambiguity; users tend to enter incomplete or vague queries, making retrieval difficult.
In multi-turn conversations, this complexity increases as user queries often reference earlier parts of the conversation, necessitating contextual understanding for effective retrieval. Additionally, some queries require synthesizing information from multiple sources, demanding advanced integration capabilities.
For LLMs, handling long-context inputs is a challenge. These models, despite continuous improvements, often struggle with forgetting details in lengthy inputs and require substantial computational resources, which become more pronounced in multi-turn scenarios.
Deployment of these systems involves complex RAG pipelines, which include various microservices like embedding, vector databases, and LLMs. Setting up and managing these services in a secure, efficient manner is a significant task.
For more information about how to build a production-grade RAG pipeline, refer to the NVIDIA/GenerativeAIExamples GitHub repo.
Let’s look at how NeMo Retriever—which brings an optimized, commercially viable set of tools—streamlines the retrieval process in complex scenarios.
NVIDIA NeMo Retriever for retrieval-augmented generation
We announced the latest addition to the NVIDIA NeMo framework, NVIDIA NeMo Retriever, an information retrieval service that can be deployed on-premises or in the cloud. It provides a secure and simplified path for enterprises to integrate enterprise-grade RAG capabilities into their customized production AI applications.
NeMo Retriever aims to provide state-of-the-art, commercially-ready models and microservices, optimized for the lowest latency and highest throughput. It also features a production-ready information retrieval pipeline with enterprise support. The models that form the core of this solution have been trained using responsibly selected, auditable data sources. With multiple pretrained models available as starting points, developers can also quickly customize them for their domain-specific use cases, such as IT or HR help assistants, and R&D research assistants.
Today, we are sharing our embedding model, optimized for text question-answering retrieval. We are in the process of developing reranking and retrieval microservices, which will be available soon.
NVIDIA Retrieval QA Embedding Model
An embedding model is a crucial component of a text retrieval system, as it transforms textual information into dense vector representations. They are usually transformer encoders that process tokens of input text (for example, question, passage) to output an embedding.
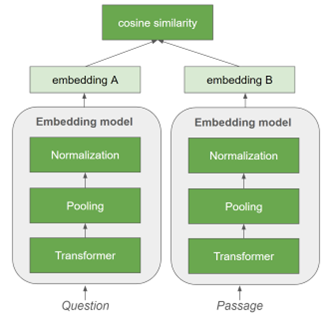
Embedding models for text retrieval are typically trained using a bi-encoder architecture, such as the one depicted in Figure 5. This involves encoding a pair of sentences (for example, query and chunked passages) independently using the embedding model. Contrastive learning is used to maximize the similarity between the query and the passage that contains the answer, while minimizing the similarity between the query and sampled negative passages not useful to answer the question.
The NVIDIA Retrieval QA Embedding Model is a transformer encoder—a fine-tuned version of E5-Large-Unsupervised, with 24 layers and an embedding size of 1024, trained on private and public datasets. It supports a maximum input of 512 tokens. Furthermore, we are committed to investigating cutting-edge model architectures and datasets to enable state-of-the-art (SOTA) retrieval models with NeMo Retriever.
Training dataset
The development of large-scale public open-QA datasets has enabled tremendous progress in powerful embedding models. However, one popular dataset named MSMARCO restricts commercial licensing, limiting the use of these models in commercial settings. To address this, we created our own internal open-domain QA dataset to train a commercially viable embedding model.
We searched weblogs for passages related to NVIDIA proprietary data collection and chose a set of passages that were relevant to customer use cases. These passages were annotated by the NVIDIA internal data annotation team.
To minimize the redundancy in our data collection process, we selected samples that maximized relevancy distance scores and increased diversity in the data. The pretrained embedding model was fine-tuned using a mixture of English language datasets, which includes our proprietary dataset, along with selected samples from public datasets that are available for commercial use.
Our main objective was to refine information retrieval capabilities, specifically tailoring the embedding model for the common enterprise LLM use case of text-based question-and-answering over knowledge bases.
Evaluation results
The NVIDIA Retrieval QA Embedding Model is focused on question-answering applications. This is an asymmetric semantic search problem, as the questions and passages typically have different distributions and patterns—the questions generally being shorter than paragraphs that contain the answer.
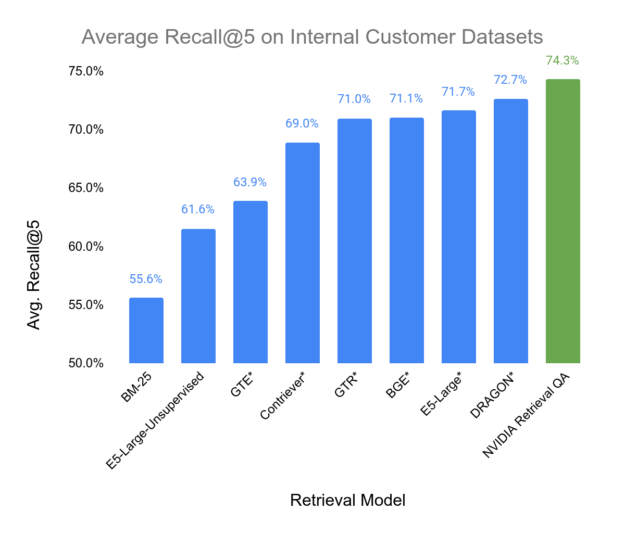
We evaluated our embedding model with real internal customer datasets from telco, IT, consulting, and energy industries. The metric was Recall@5, to emulate a RAG scenario where we provided the top five most relevant passages as context in the prompt for the LLM model to respond to the question. We compared our model’s information retrieval accuracy to a number of well-known embedding models made available by the AI community, including ones trained on non-commercial datasets, which are marked with a *. Recall@5 is a measure of how often the relevant item is present in the top five retrieved items.
You can see the results of the benchmark in Figure 6. Notice that our retriever model achieves the best performance among those baselines.
As shown in Figure 7, we compared the NVIDIA Retrieval QA Embedding Model to popular open source and commercial retriever models on academic benchmarks NQ, HotpotQA, FiQA from BeIR benchmark, and the TechQA dataset. In this benchmark, the metric used is Normalized Discounted Cumulative Gain@10 (NDCG@10).
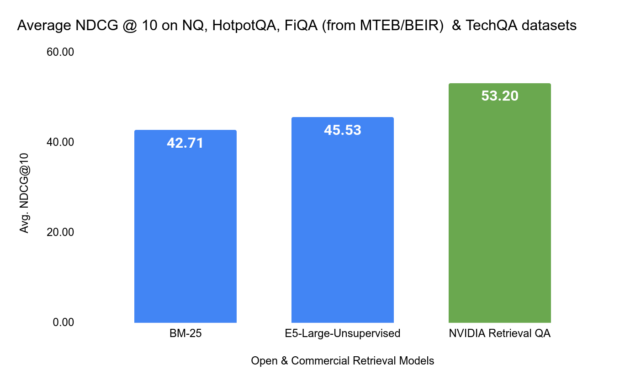
Note that the techQA dataset, consisting of questions and answers curated from the IBM technical forum together with 800k technotes as the knowledge base, wasn’t used in a retrieval benchmark setting before. We provide a notebook to convert this dataset to a BEIR-compliant format for benchmarking.
Getting started
The NVIDIA Retrieval QA Embedding Model will be available soon as part of a microservices container in early access (EA). Apply to be a part of the EA program.
You can also gain free-trial access to the NVIDIA Retrieval QA embedding API in the NGC catalog.
NVIDIA Retrieval QA Embedding Playground API
The NVIDIA Retriever QA Embedding Model is a fine-tuned version of E5-Large-Unsupervised and a similar input format requirement applies. When making a request, you must indicate if it is a “query” or “passage” in the payload. This is necessary for asymmetric tasks such as passage retrieval in open QA.
The API accepts a simple payload format, with the “input” being the chunk of text to produce embedding. In the following example API call, we embed two longer texts as “passages” and one smaller “query” text and then compute the similarity between the passages and the query using the dot product.
Note that you must log in the NGC AI Playground and obtain an API key, which is used as “API_KEY” in the following snippet.
1. Embed two passages.
import requests
import numpy as np
# Make sure to fill this. You will need to obtain the API_KEY from NGC playground
API_KEY="<YOUR_NGC_PLAYGROUND_API_KEY>"
invoke_url = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/functions/091a03bb-7364-4087-8090-bd71e9277520"
fetch_url_format = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/status/"
headers = {
"Authorization": "Bearer {}".format(API_KEY),
"Accept": "application/json",
}
# To re-use connections
session = requests.Session()
# Note the "model": "passage" field in the payload.
passage_payload = {
"input": ["Pablo Ruiz Picasso was a Spanish painter, sculptor, printmaker, ceramicist and theater designer who spent most of his adult life in France.",
"Albert Einstein was a German-born theoretical physicist who is widely held to be one of the greatest and most influential scientists of all time."],
"model" : "passage",
"encoding_format": "float"
}
passage_response = session.post(invoke_url, headers=headers, json=passage_payload)
while passage_response.status_code == 202:
request_id = passage_response.headers.get("NVCF-REQID")
fetch_url = fetch_url_format + request_id
passage_response = session.get(fetch_url, headers=headers)
passage_response.raise_for_status()
passage_embeddings = np.asarray([item['embedding'] for item in passage_response.json()['data']])
2. Embed the query
# Note the "model": "query" field in the payload
query_payload = {
"input": "Who is a great particle physicist?",
"model" : "query",
"encoding_format": "float"
}
query_response = session.post(invoke_url, headers=headers, json=query_payload)
while query_response.status_code == 202:
request_id = query_response.headers.get("NVCF-REQID")
fetch_url = fetch_url_format + request_id
query_response = session.get(fetch_url, headers=headers)
query_response.raise_for_status()
query_embedding = np.asarray(query_response.json()['data'][0]['embedding'])
3. Calculate the similarity between the passage and query embeddings
# A simple dot product
np.dot(passage_embeddings, query_embedding)
Output:
array([0.33193235, 0.52141018])
In this example, the query shares more similarities with the second paragraph, both related to the physics domain.
Conclusion
NVIDIA NeMo Retriever provides an embedding service tailored for question-answering applications. The embedding model and service are provided under a commercial use license. While this model has shown promising results on several public and internal benchmarks, we’re working to continually improve the model’s quality.
For those looking into building a production-grade RAG pipeline, see the NVIDIA/GenerativeAIExamples GitHub repo.
To get exclusive access to over 600 SDKs and AI models, free training, and network with our community of technical experts, join the free NVIDIA Developer Program. For a limited time, new members will get a free self-paced course from the NVIDIA Deep Learning Institute upon joining.
