
Large language models (LLMs) are revolutionizing data science, enabling advanced capabilities in natural language understanding, AI, and machine learning. Custom LLMs, tailored for domain-specific insights, are finding increased traction in enterprise applications.
The NVIDIA Nemotron-3 8B family of foundation models is a powerful new tool for building production-ready generative AI applications for the enterprise–fostering innovations ranging from customer service AI chatbots to cutting-edge AI products.
These new foundation models join NVIDIA NeMo, an end-to-end framework for building, customizing, and deploying LLMs tailored for enterprise use. Businesses can now use these tools for developing AI applications quickly, cost-effectively, and on a large scale. These applications can run in the cloud, data center, and on Windows desktop and laptop machines.
The Nemotron-3 8B family is available in the Azure AI Model Catalog, HuggingFace, and the NVIDIA AI Foundation Model hub on the NVIDIA NGC Catalog. It includes base, chat, and question-and-answer (Q&A) models that are designed to solve a variety of downstream tasks. Table 1 shows the full family of foundation models.
| Model | Variant | Key Benefit |
Base | Nemotron-3-8B-Base | Enables customization, including parameter-efficient fine-tuning and continuous pretraining for domain-adapted LLMs |
Chat | Nemotron-3-8B-Chat-SFT | A building block for instruction tuning custom models or user-defined alignment, such as RLHF or SteerLM models |
| Nemotron-3-8B-Chat-RLHF | Best out-of-the-box chat model performance | |
| Nemotron-3-8B-Chat-SteerLM | Best out-of-the-box chat model with flexible alignment at inference time | |
| Question-and- Answer | Nemotron-3-8B-QA | Q&A LLMs customized on knowledge bases |
Designing foundation models for production use
Foundation models are a powerful building block that reduces the time and resources required to build useful, custom applications. However, organizations must make sure that these models meet their enterprise requirements.
NVIDIA AI Foundation Models are trained on responsibly sourced datasets, capturing myriad voices and experiences. Rigorous monitoring provides data fidelity and compliance with evolving legal stipulations. Any arising data issues are swiftly addressed, making sure that businesses are armed with AI applications that comply with both legal norms and user privacy. These models can assimilate both publicly available and proprietary datasets.
Nemotron-3-8B base
The Nemotron-3-8B base model is a compact, high-performance model for generating human-like text or code. The model has an MMLU 5-shot average of 54.4. The base model also caters to the needs of global enterprises with multilingual capabilities, as it is proficient in 53 languages including English, German, Russian, Spanish, French, Japanese, Chinese, Italian, and Dutch. This base model is also trained on 37 different coding languages.
Nemotron-3-8B chat
Adding to this suite are the Nemotron-3-8B chat models, which target LLM-powered chatbot interactions. There are three chat model versions, each designed for unique user-specific adjustments:
- Supervised fine-tuning (SFT)
- Reinforcement learning from human feedback (RLHF)
- NVIDIA SteerLM
The Nemotron-3-8B-SFT model is the first step in instruct-tuning, from which we build our RLHF model that has the highest MT-Bench score within the 8B category, the most cited metric for chat quality. We suggest the user begin with 8B-chat-RLHF for the best immediate chat interaction, but for enterprises interested in uniquely aligning with their end users’ preferences, we recommend the SFT model while applying their own RLHF.
Finally, the latest alignment method, SteerLM, offers a new level of flexibility for training and customizing LLMs at inference. With SteerLM, users define all the attributes they want and embed them in a single model. Then, they can choose the combination they need for a given use case while the model is running.
This method enables a continuous improvement cycle. Responses from a custom model can serve as data for a future training run that dials the model into new levels of usefulness.
Nemotron-3-8B question-and-answer
The Nemotron-3-8B-QA model is a question-and-answer (QA) model fine-tuned on a large amount of data focused on the target use case.
The Nemotron-3-8B-QA model offers state-of-the-art performance, achieving a zero-shot F1 score of 41.99% on the Natural Questions dataset. This metric measures how closely the generated answer resembles the truth in QA.
The Nemotron-3-8B-QA model has been tested against other state-of-the-art language models that have a larger parameter size. This testing was conducted on datasets created by NVIDIA, as well as on Natural Questions and Doc2Dial datasets. Results show that this model performs well.
Building custom LLMs with NVIDIA NeMo framework
NVIDIA NeMo simplifies the path to building customized, enterprise generative AI models by providing end-to-end capabilities and containerized recipes for several model architectures. With the Nemotron-3-8B family of models, developers have access to pretrained models from NVIDIA that can be easily adapted for their specific use cases.
Fast model deployment
When using the NeMo framework, there isn’t a need for collecting data or setting up infrastructure. NeMo streamlines the process. Developers can customize existing models and deploy them in production quickly.
Optimal model performance
Furthermore, it integrates seamlessly with the NVIDIA TensorRT-LLM open-source library, which optimizes model performance, along with NVIDIA Triton Inference Server, which accelerates the inference serving process. This combination of tools enables cutting-edge accuracy, low latency, and high throughput.
Data privacy and security
NeMo enables secure, efficient large-scale deployments that comply with safety and security regulations. For example, if data privacy is a key concern for your business, you can use NeMo Guardrails to store customer data securely without compromising on performance or reliability.
Overall, building custom LLMs with the NeMo framework is an effective way to create enterprise AI applications quickly without sacrificing quality or security standards. It offers developers flexibility in terms of customization while providing the robust tools needed for rapid deployment at scale.
Getting started with Nemotron-3-8B
You can easily run inference on the Nemotron-3-8B model with the NeMo framework, which leverages TensorRT-LLM, an open source library that provides advanced optimizations for efficient and easy LLM inference on NVIDIA GPUs. It has built-in support for various optimization techniques including:
- KV caching
- Efficient Attention modules (including MQA, GQA, and Paged Attention)
- In-flight (or continuous) batching
- Support for low-precision (INT8/FP8) quantization, among other optimizations.
The NeMo framework inference container includes all the necessary scripts and dependencies to apply TensorRT-LLM optimizations on NeMo models such as the Nemotron-3-8B family, and host them with Triton Inference Server. With deployment, it exposes an endpoint you can send your inference queries to.
Prerequisites
To follow the instructions to deploy and infer, you’ll need access to:
- NVIDIA Data Center GPUs: at least (1) A100 – 40 GB / 80 GB, (2) H100 – 80 GB, or (3) L40S.
- NVIDIA NeMo framework: provides you with both the training and inference containers to customize or deploy the Nemotron-3-8B family of models.
Steps to deploy on Azure ML
The models in the Nemotron-3-8B family are available in the Azure ML Model Catalog for deploying in Azure ML-managed endpoints. AzureML provides an easy to use ‘no-code deployment’ flow hat makes deploying Nemotron-3-8B family models very easy. The underlying plumbing that is the NeMo framework inference container is integrated within the platform.
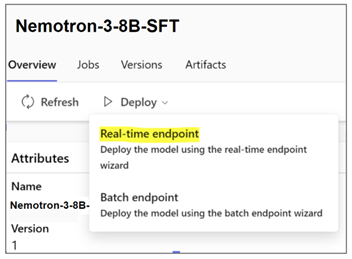
To deploy the NVIDIA foundation model on Azure ML for inference, follow the following steps:
- Log in to your Azure account: https://portal.azure.com/#home
- Navigate to Azure ML Machine Learning Studio
- Select your workspace & navigate to the model catalog
NVIDIA AI Foundation models are available for fine-tuning, evaluation, and deployment on Azure. Customization of the models can be done within Azure ML using the NeMo training framework. The NeMo framework, consisting of training and inference containers, is already integrated within AzureML.
To fine-tune the base model, select your favorite model variant, click ‘fine-tune’, fill in parameters like task type, custom training data, train and validation split, and the compute cluster.
To deploy the model, select your favorite model variant, click ‘Real-time endpoint’, select instance, endpoint, and other parameters for customizing deployment. Click deploy to deploy the model for inference to an endpoint.
Azure CLI and SDK support are also available for running fine-tuning jobs and deployments on Azure ML. For more information, please refer to Foundation Models in Azure ML documentation.
Steps for deploying on-prem or on other clouds
The models in the Nemotron-3-8B family have distinct prompt templates for inference requests that are recommended as best practice, however, the instructions to deploy them are similar, as they share the same base architecture.
For the latest deployment instructions using the NeMo framework inference container, see https://registry.ngc.nvidia.com/orgs/ea-bignlp/teams/ga-participants/containers/nemofw-inference.
To demonstrate, let’s deploy Nemotron-3-8B-Base-4k.
- Log in to the NGC Catalog, and fetch the Inference container.
# log in to your NGC organization
docker login nvcr.io
# Fetch the NeMo framework inference container
docker pull nvcr.io/ea-bignlp/ga-participants/nemofw-inference:23.10- Download the Nemotron-3-8B-Base-4k model. The 8B family of models is available on NGC Catalog, as well as on Hugging Face. You may choose to download the model from either one.
NVIDIA NGC
The easiest way to download the model from NGC is to use the CLI. If you don’t have the NGC CLI installed, follow the Getting Started instructions to install and configure it.
# Downloading using CLI. The model path can be obtained from it’s page on NGC
ngc registry model download-version "dztrnjtldi02/nemotron-3-8b-base-4k:1.0"Hugging Face Hub
The following command uses git-lfs, but you may use any of the methods supported by Hugging Face to download models.
git lfs install
git clone https://huggingface.co/nvidia/nemotron-3-8b-base-4k nemotron-3-8b-base-4k_v1.0- Run the NeMo inference container in interactive mode, mounting the relevant paths
# Create a folder to cache the built TRT engines. This is recommended so they don’t have to be built on every deployment call.
mkdir -p trt-cache
# Run the container, mounting the checkpoint and the cache directory
docker run --rm --net=host \
--gpus=all \
-v $(pwd)/nemotron-3-8b-base-4k_v1.0:/opt/checkpoints/ \
-v $(pwd)/trt-cache:/trt-cache \
-w /opt/NeMo \
-it nvcr.io/ea-bignlp/ga-participants/nemofw-inference:23.10 bash4. Convert and Deploy the model on Triton Inference Server with TensorRT-LLM backend.
python scripts/deploy/deploy_triton.py \
--nemo_checkpoint /opt/checkpoints/Nemotron-3-8B-Base-4k.nemo \
--model_type="gptnext" \
--triton_model_name Nemotron-3-8B-4K \
--triton_model_repository /trt-cache/8b-base-4k \
--max_input_len 3000 \
--max_output_len 1000 \
--max_batch_size 2Note that this script will export the built TensorRT-LLM engine files at the path specified in “–triton_model_repository”. To load the exported model without rebuilding engines in subsequent deployments, you can skip the “–nemo_checkpoint”, “–max_input_len”, “–max_output_len”, and “max_batch_size” arguments. More information about using this script can be found in the documentation.
When this command is successfully completed, it exposes an endpoint you can query. Let’s look at how you can do that.
Steps to run inference
There are several options available to run inference depending on how you want to integrate the service:
- Using NeMo client APIs available in the NeMo framework inference container
- Using PyTriton to create a client app in your environment
- Using any library/tool that can send an HTTP request, as the deployed service exposes an HTTP endpoint.
An example of option 1, using NeMo client APIs is as follows. You can use this from the NeMo framework inference container on the same machine or a different machine with access to the service IP and ports.
from nemo.deploy import NemoQuery
# In this case, we run inference on the same machine
nq = NemoQuery(url="localhost:8000", model_name="Nemotron-3-8B-4K")
output = nq.query_llm(prompts=["The meaning of life is"], max_output_token=200, top_k=1, top_p=0.0, temperature=0.1)
print(output)Examples of the other options are available in the README of the inference container.
NOTE: The chat models (SFT, RLHF and SteerLM) require post-processing the output as these three models have been trained to end their response with “<extra_id_1>”, but the `NemoQuery` API does not yet support stopping the generation automatically when this special token is generated. This can be achieved by modifying `output` as follows:
output = nq.query_llm(...)
output = [[s.split("<extra_id_1>", 1)[0].strip() for s in out] for out in output]Prompting the 8B family of models
The models in the NVIDIA Nemotron-3-8B family share a common pretrained foundation. However, the datasets used to tune the chat (SFT, RLHF, SteerLM), and QA models are customized for their specific purposes. Also, building these models employs different training techniques. Consequently, these models are most effective with tailored prompts that follow a template similar to how they were trained.
The recommended prompt templates for these models can be found on their respective model cards.
As an example, here are the single-turn and multi-turn formats applicable to Nemotron-3-8B-Chat-SFT and Nemotron-3-8B-Chat-RLHF models:
| Nemotron-3-8B-Chat-SFT and Nemotron-3-8B-Chat-RLHF | |
| Single-turn prompting | Multi-turn or Few-shot |
<extra_id_0>System | <extra_id_0>System |
The prompt and response fields correspond to where your input will go. Here’s an example of formatting your input using the single-turn template.
PROMPT_TEMPLATE = """<extra_id_0>System
{system}
<extra_id_1>User
{prompt}
<extra_id_1>Assistant
"""
system = ""
prompt = "Write a poem on NVIDIA in the style of Shakespeare"
prompt = PROMPT_TEMPLATE.format(prompt=prompt, system=system)
print(prompt)NOTE: For the Nemotron-3-8B-Chat-SFT and Nemotron-3-8B-Chat-RLHF models, we recommend keeping the system prompt empty.
Further training and customization
The NVIDIA Nemotron-3-8B family of models is suitable for further customization for domain-specific datasets. There are several options for this, such as continuing pretraining from checkpoints, SFT or parameter-efficient fine-tuning, alignment on human demonstrations with RLHF, or using the new SteerLM technique from NVIDIA.
Easy-to-use scripts for the mentioned techniques exist in the NeMo framework training container. We also provide tools for data curation, identifying optimal hyperparameters for training and inference, and running the NeMo framework on your choice of hardware that is on-prem DGX cloud, Kubernetes-enabled platform, or a Cloud Service Provider.
For more information, check out the NeMo Framework User Guide or container README.
The Nemotron-3-8B family of models is designed for diverse use cases, that not only perform competitively on various benchmarks but are also capable of multiple languages.
Take them for a spin, and let us know what you think in the comments.
