
Every AI application needs a strong inference engine. Whether you’re deploying an image recognition service, intelligent virtual assistant, or a fraud detection application, a reliable inference server delivers fast, accurate, and scalable predictions with low latency (low response time to a single query) and strong throughput (large number of queries processed in a given time interval). Yet, checking all these boxes can be difficult and expensive to achieve.
Teams need to consider deploying applications that can leverage:
- Diverse frameworks with independent execution backends (ONNX Runtime, TensorFlow, PyTorch)
- Different inference types (real-time, batch, streaming)
- Disparate inference serving solutions for mixed infrastructure (CPU, GPU)
- Different model configuration settings (dynamic batching, model concurrency) that can significantly impact inference performance
These requirements can make AI inference an extremely challenging task, which can be simplified with NVIDIA Triton Inference Server.
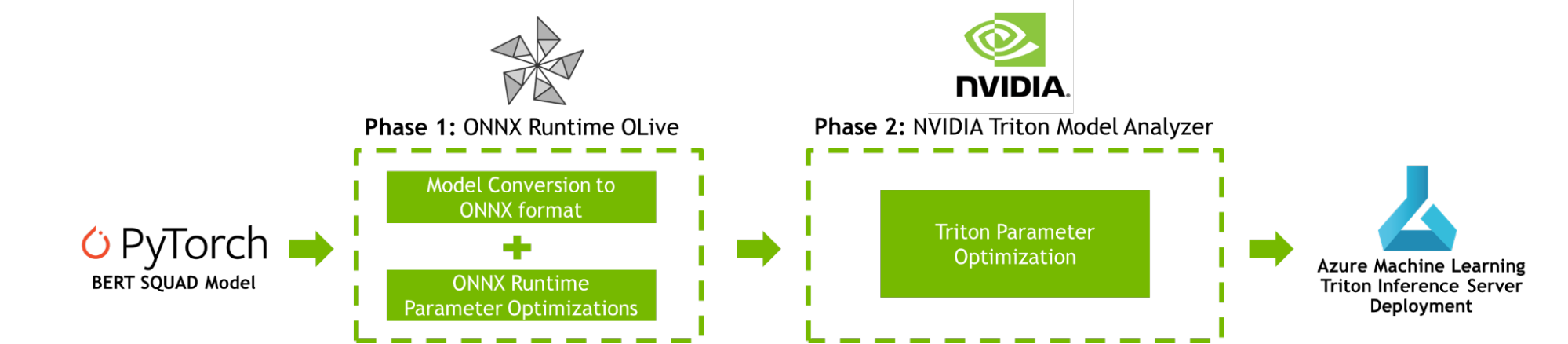
This post provides a step-by-step tutorial for boosting your AI inference performance on Azure Machine Learning using NVIDIA Triton Model Analyzer and ONNX Runtime OLive, as shown in Figure 1.
Machine learning model optimization workflow
To improve AI inference performance, both ONNX Runtime OLive and Triton Model Analyzer automate the parameter optimization steps prior to model deployment. These parameters define how the underlying inference engine will perform. You can use these tools to optimize the ONNX Runtime parameters (execution provider, session options, and precision parameters), and the Triton parameters (dynamic batching and model concurrency parameters).
Phase 1: ONNX Runtime OLive optimizations
If Azure Machine Learning is where you deploy AI applications, you may be familiar with ONNX Runtime. ONNX Runtime is Microsoft’s high-performance inference engine to run AI models across platforms. It can deploy models across numerous configuration settings and is now supported in Triton. Fine-tuning these configuration settings requires dedicated time and domain expertise.
OLive (ONNX Runtime Go Live) is a Python package that speeds up this process by automating the work of accelerating models with ONNX Runtime. It offers two capabilities: converting models to ONNX format and auto-tuning ONNX Runtime parameters to maximize inference performance. Running OLive will isolate and recommend ONNX Runtime configuration settings for the optimal core AI inference results.
You can optimize an ONNX Runtime BERT SQuAD model with OLive using the following ONNX Runtime parameters:
- Execution provider: ONNX Runtime works with different hardware acceleration libraries through its extensible Execution Providers (EP) framework to optimally run the ONNX models on the hardware platform, which can optimize the execution by taking advantage of the platform’s compute capabilities. OLive explores optimization on the following execution providers: MLAS (default CPU EP), Intel DNNL, and OpenVino for CPU, NVIDIA CUDA and TensorRT for GPU.
- Session options: OLive sweeps through ONNX Runtime session options to find the optimal configuration for thread control, which includes
inter_op_num_threads,intra_op_num_threads,execution_mode, andgraph_optimization_level. - Precision: OLive evaluates performance with different levels of precision, including
float32andfloat16, and returns the optimal precision configuration.
After running through the optimizations, you still may be leaving some performance on the table at application level. The end-to-end throughput and latency can be further improved using the Triton Model Analyzer, which is capable of supporting optimized ONNX Runtime models.
Phase 2: Triton Model Analyzer optimizations
NVIDIA Triton Inference Server is an open-source inference serving software that helps standardize model deployment and execution and delivers fast and scalable AI inferencing in production. Figure 2 shows how the Triton Inference Server manages client requests when integrated with client applications and multiple AI models.
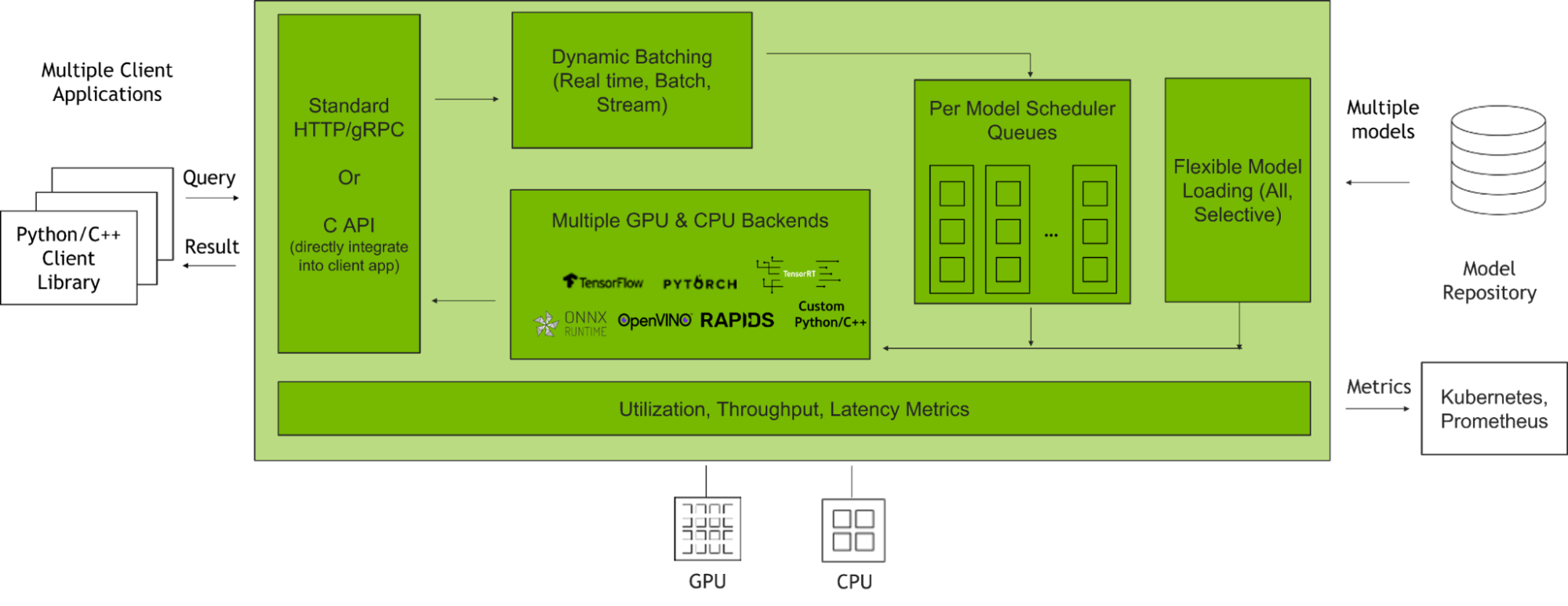
This post will focus on optimizing two major Triton features with Triton Model Analyzer:
- Dynamic Batching: Triton enables inference requests to be combined by the server, so that a batch is created dynamically. This results in increased throughput within a fixed latency budget.
- Model Concurrency: Triton allows multiple models or instances of the same model to execute in parallel on the same system. This results in increased throughput.
These features are extremely powerful when deployed at optimal levels. When deployed with suboptimal configurations, performance is compromised, leaving end applications vulnerable to current demanding quality-of-service standards (latency, throughput, and memory requirements).
As a result, optimizing batch size and model concurrency levels based on expected user traffic is critical to unlock the full potential of Triton. These optimized model configuration settings will generate improved throughput under strict latency constraints, boosting GPU utilization when the application is deployed. This process can be automated using the Triton Model Analyzer.
Given a set of constraints including latency, throughput targets, or memory footprints, Triton Model Analyzer searches for and selects the best model configuration that maximizes inference performance based on different levels for batch size, model concurrency, or other Triton model configuration settings. When these features are deployed and optimized, you can expect to see incredible results.
Tutorial: Begin optimizing inference performance
Four steps are required to deploy optimized machine learning models with ONNX Runtime OLive and Triton Model Analyzer on Azure Machine Learning:
- Launch an Azure Virtual Machine with the NVIDIA GPU-optimized Virtual Machine Image (VMI)
- Execute ONNX Runtime OLive and Triton Model Analyzer parameter optimizations on your model
- Analyze and customize the results
- Deploy the optimized Triton-ONNX Runtime model onto an Azure Machine Learning endpoint
To work through this tutorial, ensure you have an Azure account with access to NVIDIA GPU-powered virtual machines. For example, use Azure ND A100 v4-series VMs for NVIDIA A100 GPUs, NCasT4 v3-series for NVIDIA T4 GPUs, or NCv3-series for NVIDIA V100 GPUs. While the ND A100 v4-series is recommended for maximum performance at scale, this tutorial uses a standard NC6s_v3 virtual machine using a single NVIDIA V100 GPU.
Step 1: Launching an Azure virtual machine with NVIDIA’s GPU-optimized VMI
This tutorial uses the NVIDIA GPU-optimized VMI available on the Azure Marketplace. It is preconfigured with NVIDIA GPU drivers, CUDA, Docker toolkit, Runtime, and other dependencies. Additionally, it provides a standardized stack for developers to build their AI applications.
To maximize performance, this VMI is validated and updated quarterly by NVIDIA with the newest drivers, security patches, and support for the latest GPUs.
For more details on how to launch and connect to the NVIDIA GPU-optimized VMI on your Azure VM, refer to the NGC on Azure Virtual Machines documentation.
Step 2: Executing ONNX Runtime OLive and Triton Model Analyzer optimizations
Once you have connected to your Azure VM using SSH with the NVIDIA GPU-optimized VMI loaded, you are ready to begin executing ONNX Runtime OLive and Triton Model Analyzer optimizations.
First, clone the GitHub Repository and navigate to the content root directory by running the following commands:
git clone https://github.com/microsoft/OLive.gitcd OLive/olive-model_analyzer-azureMLNext, load the Triton Server container. Note that this tutorial uses the version number 22.06.
docker run --gpus=1 --rm -it -v “$(pwd)”:/models nvcr.io/nvidia/tritonserver:22.06-py3 /bin/bashOnce loaded, navigate to the /models folder where the GitHub material is mounted:
cd /models Download the OLive and ONNX Runtime packages, along with the model you want to optimize. Then, specify the location of the model you want to optimize by setting up the following environmental variables:
- export model_location=https://olivewheels.blob.core.windows.net/models/bert-base-cased-squad.pth
- export model_filename=bert-base-cased-squad.pth
You may adjust the location and file name provided above with a model of your choice. For optimal performance, download certified pretrained models directly from the NGC catalog. These models are trained to high accuracy and are available with high-level credentials and code samples.
Next, run the following script:
bash download.sh $model_location $export model_filenameThe script will download three files onto your machine:
- OLive package:
onnxruntime_olive-0.3.0-py3-none-any.whl - ONNX Runtime package:
onnxruntime_gpu_tensorrt-1.9.0-cp38-cp38-linux_x86_64.whl - PyTorch Model:
bert-base-cased-squad.pth
Before running the pipeline in Figure 1, first specify its input parameters by setting up environmental variables:
- export
model_name=bertsquad - export
model_type=pytorch - export
in_names=input_names,input_mask,segment_ids - export
in_shapes=[[-1,256],[-1,256],[-1,256]] - export
in_types=int64,int64,int64 - export
out_names=start,end
The parameters in_names, in_shapes, and in_types refer to the names, shapes and types of the expected inputs for the model. In this case, inputs are sequences of length 256, however they are specified as [-1,256] to allow the batching of inputs. You can change the parameters values that correspond to your model and its expected inputs and outputs.
Now, you’re ready to run the pipeline by executing the following command:
bash optimize.sh $model_filename $model_name $model_type $in_names $in_shapes $in_types $out_namesThis command first installs all necessary libraries and dependencies, and calls on OLive to convert the original model into an ONNX format.
Next, Triton Model Analyzer is called to automatically generate the model’s configuration file with the model’s metadata. The configuration file is then passed back into OLive to optimize via the ONNX Runtime parameters discussed earlier (execution provider, session options, and precision).
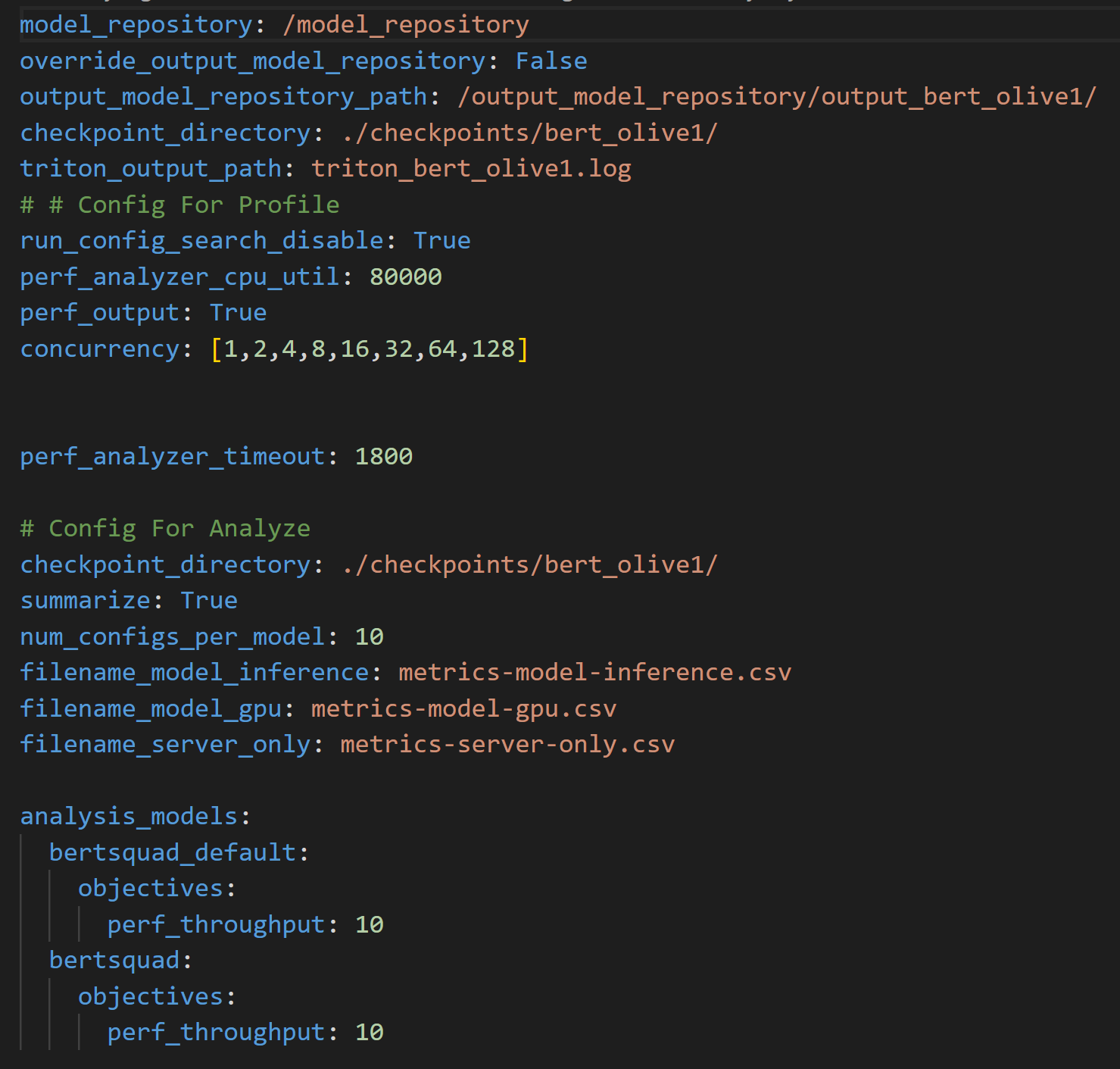
To further boost throughput and latency, the ONNX Runtime-optimized model configuration file is then passed into the Triton model repository for use by the Triton Model Analyzer tool. Triton Model Analyzer then runs the profile command, which sets up the optimization search space and specifies the location of the Triton Model repository using a .yaml configuration file (see Figure 3).
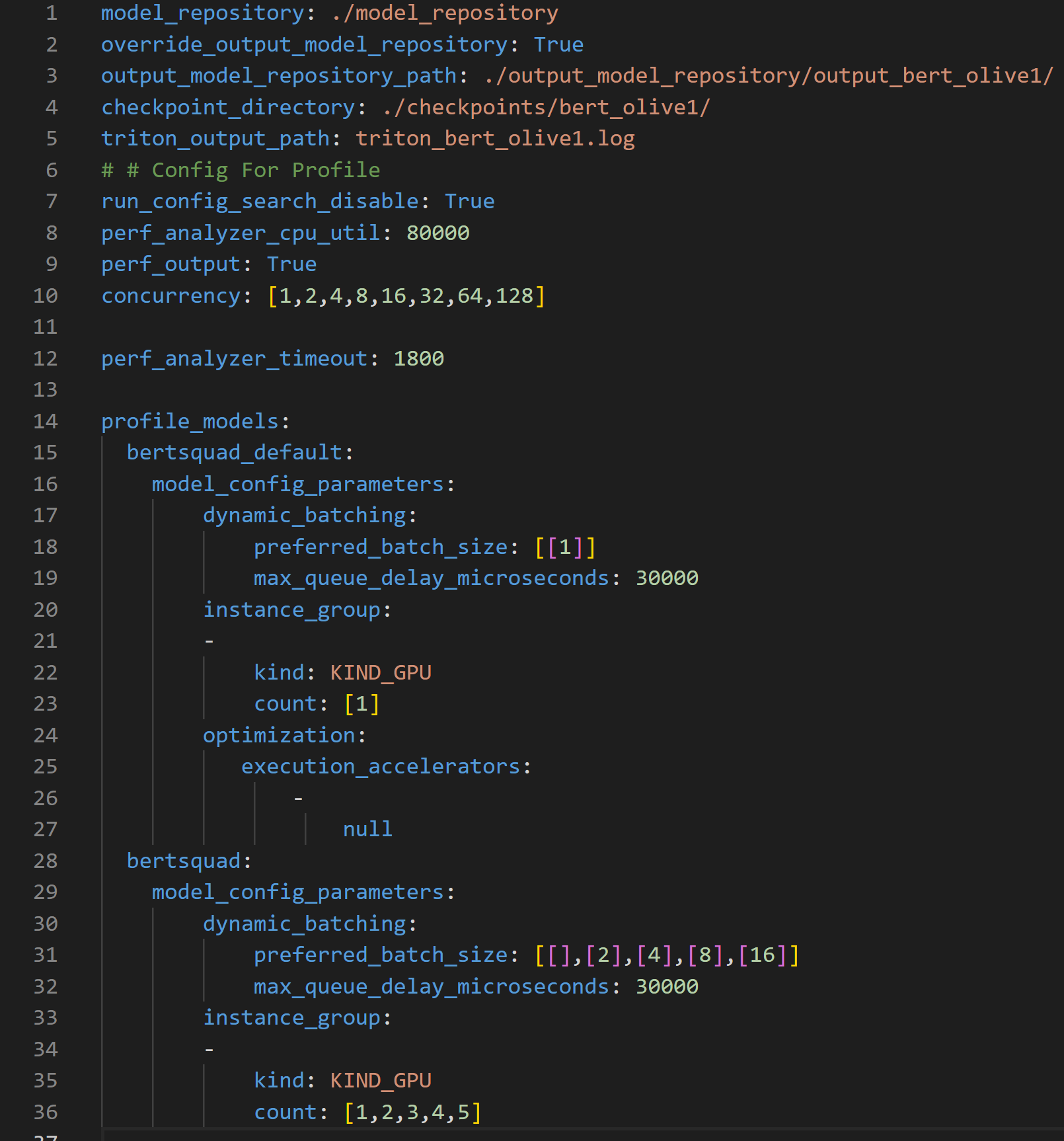
The configuration file above can be used to customize the search space for Triton Model Analyzer in a number of ways. The file requires the location of the Model Repository, parameters to optimize, and their ranges to create the search space used by Triton Model Analyzer to find the optimal configuration settings.
- Lines 1-5 specify important paths, such as the location of the Output Model Repository where the optimized models are placed.
- Line 10 specifies the parameter concurrency which dictates the concurrent inference request levels to be used by the Perf Analyzer, which emulates user traffic.
- Line 15 specifies the
bert_defaultmodel, which corresponds to the default model obtained from the PyTorch to ONNX conversion. This model is the baseline model and therefore uses non-optimized values for dynamic batching (line 17) and model concurrency (line 20) - Lines 19 and 32 shows a latency constraint of 30ms that must be satisfied during the optimization process.
- Line 28 specifies the
bertsquadmodel, which corresponds to the OLive optimized model. This one differs from thebert_defaultmodel because the dynamic batching parameter search space here is set to 1, 2, 4, 8 and 16, and the model concurrency parameter search space is set to 1, 2, 3, 4 and 5.
The profile command records results across each concurrent inference request level, and for each concurrent inference request level, the results are recorded for 25 different parameters since the search space for both the dynamic batching and model concurrency parameters have five unique values each, equating to a total of 25 different parameters. Note that the time needed to run this will scale with the number of configurations provided in the search space within the profile configuration file in Figure 3.
The script then runs the Triton Model Analyzer analyze command to process the results using an additional configuration file shown in Figure 4. The file specifies the location of the output model repository where the results were generated from the profile command, along with the name of the CSV files where the performance results will be recorded.
analyze command and process the results from the profile commandWhile the profile and analyze commands may take a couple of hours to run, the optimized model configuration settings will ensure strong long-term inference performance for your deployed model. For shorter run times, adjust the model profile configuration file (Figure 3) with a smaller search space across the parameters you wish to optimize.
Once the demo completes running, there should be two files produced: Optimal_Results.png as shown in Figure 5, and Optimal_ConfigFile_Location.txt, which represents the location of the optimal config file to be deployed on Azure Machine Learning. A non-optimized baseline is established (blue line). The performance boost achieved through OLive optimizations is shown (light green line), along with OLive + Triton Model Analyzer optimizations (dark green line).
Step 3: Analyzing performance results
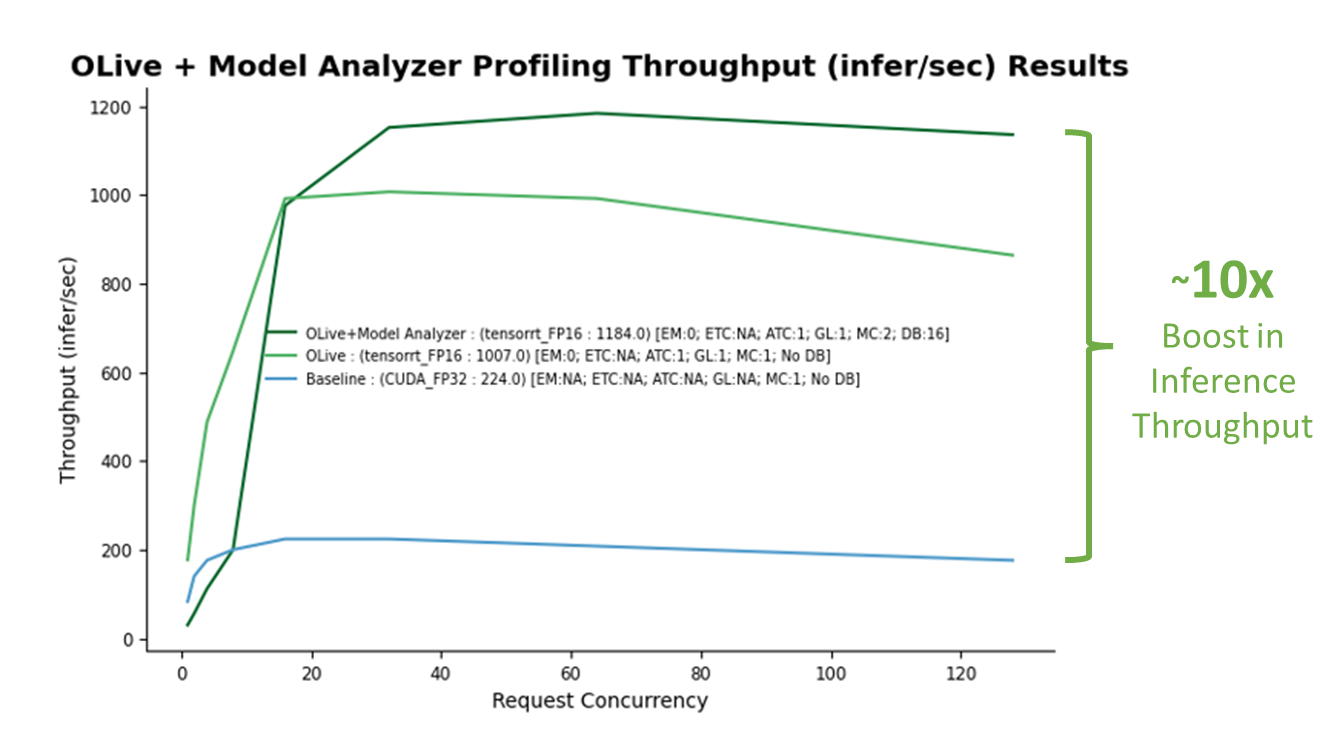
The baseline corresponds to a model with non-optimized ONNX Runtime parameters (CUDA backend with full precision) and non-optimized Triton parameters (no dynamic batching nor model concurrency). With the baseline established, it is clear there is a big boost in inference throughput performance (y-axis) obtained from both OLive and Triton Model Analyzer optimizations at various inference request concurrency levels (x-axis) emulated by Triton Perf Analyzer, a tool that mimics user traffic by generating inference requests.
OLive optimizations improved model performance (light green line) by tuning the execution provider to TensorRT with mixed precision, along with other ONNX Runtime parameters. However, this shows performance without Triton dynamic batching or model concurrency. Therefore, this model can be further optimized with Triton Model Analyzer.
Triton Model Analyzer further boosts inference performance by 20% (dark green line) after optimizing model concurrency and dynamic batching. The final optimal values selected by Triton Model Analyzer are a model concurrency of two (two copies of the BERT model will be saved on the GPU) and a maximum dynamic batching level of 16 (up to 16 inference requests will be batched together at one time).
Overall, the gain on inference performance using optimized parameters is more than 10x.
Additionally, if you are expecting certain levels of inference requests for your application, you may adjust the emulated user traffic by configuring the Triton perf_analyzer. You may also adjust the model configuration file to include additional parameters to optimize such as Delayed Batching.
You’re now ready to deploy your optimized model with Azure Machine Learning.
Step 4: Deploying the optimized model onto an Azure Machine Learning endpoint
Deploying your optimized AI model for inference on Azure Machine Learning with Triton involves using a managed online endpoint with the Azure Machine Learning Studio no code interface.
Managed online endpoints help you deploy ML models in a turnkey manner. It takes care of serving, scaling, securing, and monitoring your models, freeing you from the overhead of setting up and managing the underlying infrastructure.
To continue, ensure you have downloaded the Azure CLI, and have at hand the YAML file shown in Figure 6.
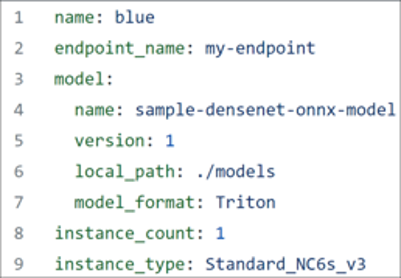
First, register your model in Triton format using the above YAML file. Your registered model should look similar to Figure 7 as shown on the Models page of Azure Machine Learning Studio.
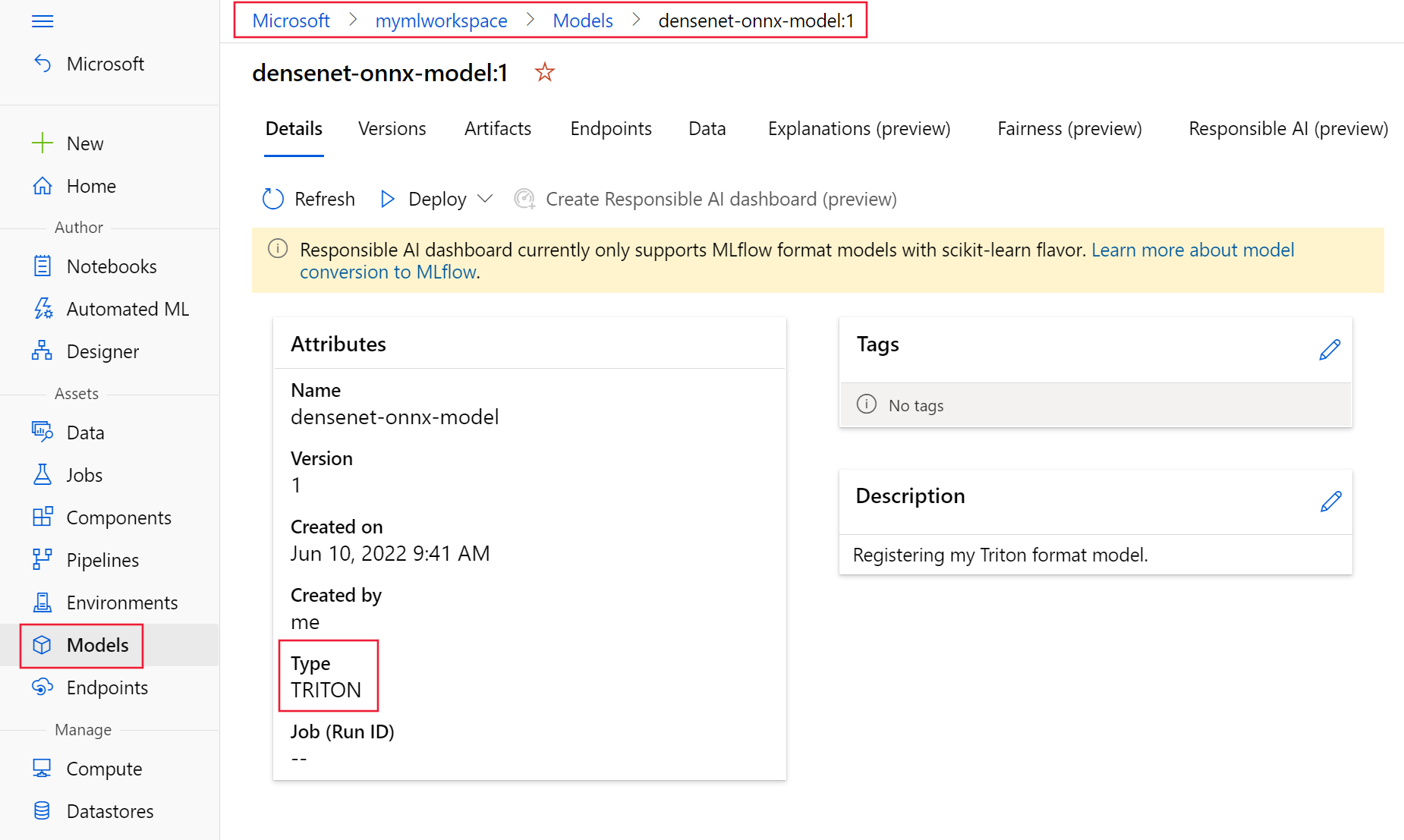
Next, select the Triton model, select ‘Deploy,’ and then ‘Deploy to real-time endpoint.’ Continue through the wizard to deploy the ONNX Runtime and Triton optimized model to the endpoint. Note that no scoring script is required when you deploy a Triton model to an Azure Machine Learning managed endpoint.
Congratulations! You have now deployed a BERT SQuAD model optimized for inference performance using ONNX Runtime and Triton parameters on Azure Machine Learning. By optimizing these parameters, you have unlocked a 10x increase in performance relative to the non-optimized baseline BERT SQuAD model.
Resources for exploring machine learning model inference tools
Explore more resources about deploying AI applications with NVIDIA Triton, ONNX Runtime, and Azure Machine Learning below:
Triton
- Download NVIDIA Triton as a Docker container from NGC.
- Get started with Triton using tutorials, notebooks, and documentation.
- Visit the Triton and Model Analyzer GitHub repositories, along with blog posts about Triton and Triton Inference Server Technical Overview to dive deeper into what Triton has to offer and how it works.
- Learn how to deploy models to NVIDIA Triton on Azure Machine Learning.
- Watch Triton-specific GTC sessions on demand.
- Deploy Triton at scale with Multi-Instance GPUs and Kubernetes.
Learn how Siemens Energy and American Express have accelerated AI inference workflows with Triton. See how your company can get started with Triton using NVIDIA AI Enterprise and NVIDIA LaunchPad.
ONNX Runtime and Azure Machine Learning
- Deploy machine learning models with Azure Machine Learning managed online endpoints.
- Understand the fundamentals of deploying real-time machine learning services on Azure Machine Learning.
- Learn more about the journey to optimize large scale transformer model inferences with ONNX Runtime.
- Optimize and deploy transformer INT8 inference with ONNX Runtime-TensorRT on NVIDIA GPUs.
- Discover how to run and deploy machine learning models on the web with ORT Web.
Find out how Microsoft Bing has improved BERT inference on NVIDIA GPUs for real-time service needs, serving more than one million BERT inferences per second.
