

AI machine learning is unlocking breakthrough applications in fields such as online product recommendations, image classification, chatbots, forecasting, and manufacturing quality inspection. There are two parts to AI: training and inference.
Inference is the production phase of AI. The trained model and associated code are deployed in the data center or public cloud, or at the edge to make predictions. This process is called inference serving and is complex for the following reasons:
- Multiple model frameworks: Data scientists and researchers use different AI and deep learning frameworks like TensorFlow, PyTorch, TensorRT, ONNX Runtime, or just plain Python to build models. Each of these frameworks requires an execution backend to run the model in production.
- Different inference query types: Inference serving requires handling different types of inference queries like real time online predictions, offline batch, streaming data, and a complex pipeline of multiple models. Each of these requires special processing for inference.
- Constantly evolving models: Models are continuously retrained and updated based on new data and new algorithms. So, the models in production need to be updated continuously without restarting the server or any downtime. A given application can use many different models and it compounds the scale.
- Diverse CPUs and GPUs: The models can be executed on a CPU or GPU and there are different types of GPUs and CPUs.
Often, organizations end up having multiple, disparate inference serving solutions, per model, per framework, or per application.
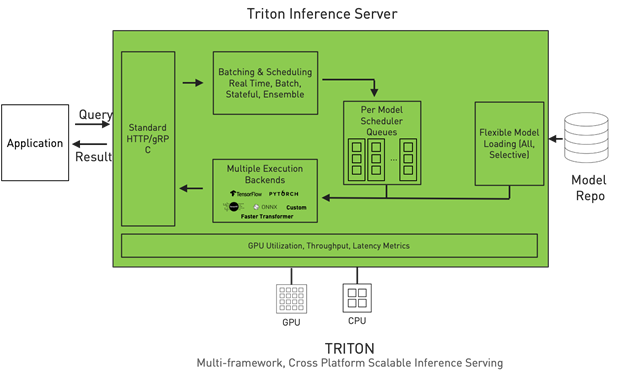
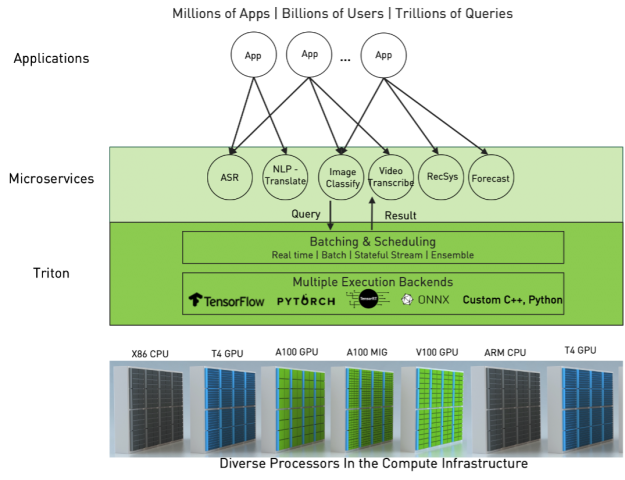
NVIDIA Triton Inference Server is an open-source inference serving software that simplifies inference serving for an organization by addressing the above complexities. Triton provides a single standardized inference platform which can support running inference on multi-framework models, on both CPU and GPU, and in different deployment environments such as datacenter, cloud, embedded devices, and virtualized environments.
It natively supports multiple framework backends like TensorFlow, PyTorch, ONNX Runtime, Python, and even custom backends. It supports different types of inference queries through advanced batching and scheduling algorithms, supports live model updates, and runs models on both CPUs and GPUs. Triton is also designed to increase inference performance by maximizing hardware utilization through concurrent model execution and dynamic batching. Concurrent execution allows you to run multiple copies of a model, and multiple different models, in parallel on the same GPU. Through dynamic batching, Triton can dynamically group together inference requests on the server-side to maximize performance.
Automatic model conversion and deployment
To further simplify the process of deploying models in production, the 2.9 release introduces a new suite of capabilities. A trained model is generally not optimized for deployment in production. You must go through a series of conversion and optimizations for your specific target environment. The following process shows a TensorRT deployment using Triton on a GPU. This applies to any inference framework, whether it’s deployed on CPU or GPU.
- Convert models from different frameworks (TensorFlow, PyTorch) to TensorRT to get the best performance.
- Check for optimizations, such as precision.
- Generate the optimized model.
- Validate the accuracy of the model post-conversion.
- Manually test different model configurations to find the one that maximizes performance, such as batch size, number of concurrent model instances per GPU.
- Prepare model configuration and repository for Triton.
- (Optional) Prepare a Helm chart for deploying Triton on Kubernetes.
As you can see, this process can take significant time and effort.
You can use the new Model Navigator in Triton to automate the process. Available as an alpha version, it can convert an input model from any framework (TensorFlow and PyTorch are supported in this release) to TensorRT, validate the conversion for correctness, automatically find and create the most optimal model configuration, and generate the repo structure for the model deployment. What could take days for each type of model now can be done in hours.
Optimizing model performance
For efficient inference serving, you must identify the optimal model configurations, such as the batch size and number of concurrent models. Today, you must try different combinations manually to eventually find the optimal configuration for your throughput, latency, and memory utilization requirements.
Triton Model Analyzer is another optimization tool that automates this selection for you by automatically finding the best configuration for models to get the highest performance. You can specify performance requirements, such as a latency constraint, throughput target, or memory footprint. The model analyzer searches through different model configurations and finds the one that provides the best performance under your constraints. To help visualize the performance of the top configurations, it then outputs a summary report, which includes charts (Figure 2).
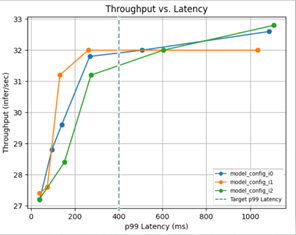
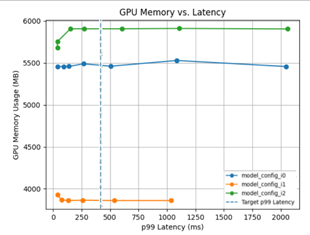
You do not have to settle for a less optimized inference service because of the inherent complexity in getting to an optimized model. You can use Triton to easily get to the most efficient inference.
Triton giant model inference
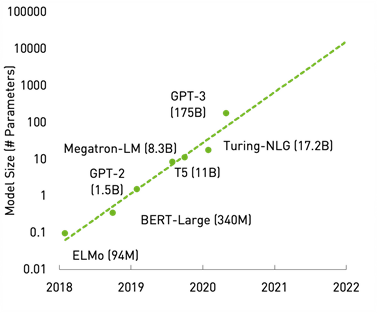
Models are rapidly growing especially in areas of natural language processing. For example, consider the GPT-3 model. Its full capabilities are still being explored. It has been shown to be effective in use cases such as reading comprehension and summarization of text, Q&A, human-like chatbots, and software code generation.
In this post, we don’t delve into the models. Instead, we look at the cost-effective inference of such giant models. GPUs are naturally the right compute resource for these workloads, but these models are so large that they cannot fit on a single GPU. For more information about a framework to train giant models on multi-GPU, multi-node systems, see Scaling Language Model Training to a Trillion Parameters Using Megatron.
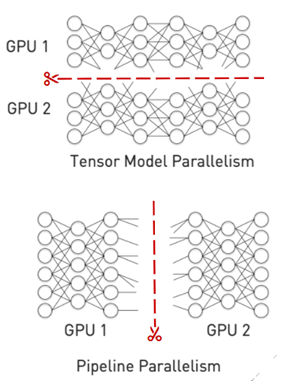
For inference, you must split the model into multiple smaller files and load each on a separate GPU. There are generally two approaches to splitting a model:
- Pipeline parallelism splits the model vertically across layer boundaries and runs these layers across multiple GPUs in a pipeline.
- Tensor parallelism cuts the network horizontally and splits individual layers across GPUs.
The Triton custom backend feature can be used to run multi-GPU, multi-node backends. In addition, Triton has a model ensemble feature that can be used for pipeline parallelism.
Giant models are still in their infancy, but it won’t be long until you see production AI running multiple giant models for different use cases.
Ecosystem integrations
Inference serving is a production activity and can require integration with many ecosystem software and tools. Triton integrates with several, with new integrations added regularly.
- Framework backends: Triton supports all the major deep learning framework execution backends out of the box, like TensorFlow, PyTorch, and ONNX RT. It allows custom backends in C++ and Python to be integrated easily. As part of the 21.03 release, a beta version of the OpenVINO backend in Triton is available for high performance CPU inferencing on the Intel platform.
- Kubernetes ecosystem: Triton is designed for scale. It integrates with major Kubernetes platforms on the cloud like AKS, EKS, and GKE and on-premises implementations including Red Hat OpenShift. It is also part of the Kubeflow project.
- Cloud AI platforms and MLOPs software: MLOps is a process that brings automation and governance to AI development and deployment workflow. Triton is integrated in cloud AI platforms such as Azure ML and can be deployed in Google CAIP and Amazon SageMaker as a custom container. It is also integrated with KFServing, Seldon Core, and Allegro ClearML.
Customer case studies
Triton is used by both large and small customers to serve models in production for all types of applications, such as computer vision, natural language processing, and financial services. Here are a few examples across different use cases:
Computer vision
- USPS: Uses Triton in a microservices architecture for package analytics in 192 USPS distribution centers. Multiple image models process billions of packages annually with Triton . For more information see the Deploying State-of-the-Art Machine Learning Algorithms at Scale to the Edge: A Case Study (Presented by Accenture Federal Services) GTC session.
- Volkswagen Smart Lab: Integrates Triton into its Volkswagen Computer Vision Workbench so users can make contributions to the Model Zoo without needing to worry about whether they are based on ONNX, PyTorch, or TensorFlow frameworks. Triton simplifies model management and deployment, and that’s key for VW’s work serving up AI models in new and interesting environments, Bormann says in his GTC session, Taming the Computer Vision Zoo with NVIDIA Triton for an easy scalable eco system.
Natural language processing
- Salesforce: Uses Triton to develop state-of-the-art transformer models. For more information, see the Benchmarking Triton Inference Server GTC 21 session.
- LivePerson: Uses Triton as a standardized platform to serve NLP models from different frameworks on CPUs for chatbot applications.
Financial services
- Intelligent Voice: Uses Triton to deploy speech and language models for sentiment analysis and fraud detection. For more information, see the Detecting Deception and Tackling Insurance Fraud with GPU-Powered Conversational AI (Presented by Intelligent Voice GTC 21 session.
- Ant Group: Uses Triton as a standardized platform to serve models for different applications, such as AntChain, copyright management platform, fraud detection, and more.
For more information about customers using Triton in production deployments, see NVIDIA Triton Tames the Seas of AI Inference.
Conclusion
Triton helps with a standardized scalable production AI in every data center, cloud, and embedded device. It supports multiple frameworks, runs models on both CPUs and GPUs, handles different types of inference queries, and integrates with Kubernetes and MLOPs platforms.
Download Triton today as a Docker container from NGC and find the documentation in the triton-inference-server GitHub repo. For more information, see the NVIDIA Triton Inference Server product page.
