Feb 05, 2024
Generate Code, Answer Queries, and Translate Text with New NVIDIA AI Foundation Models
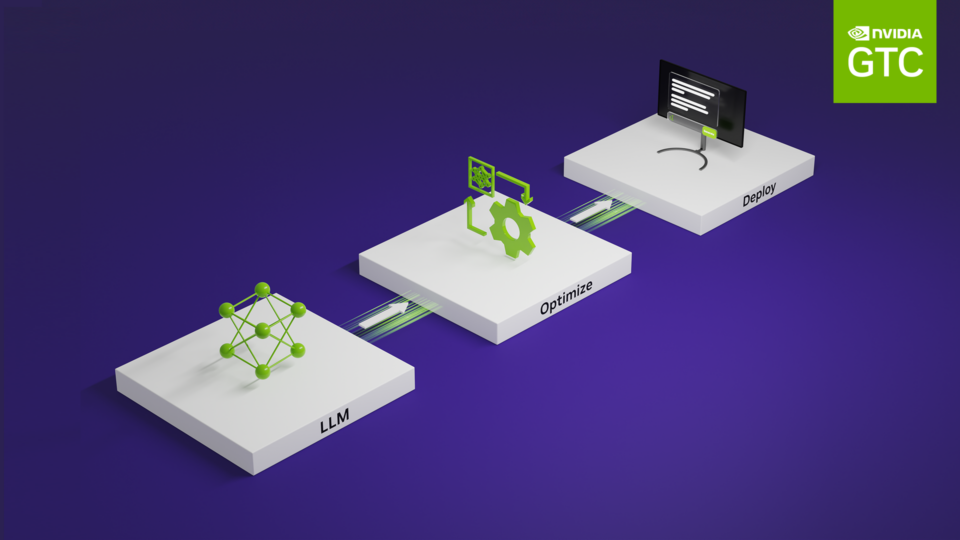
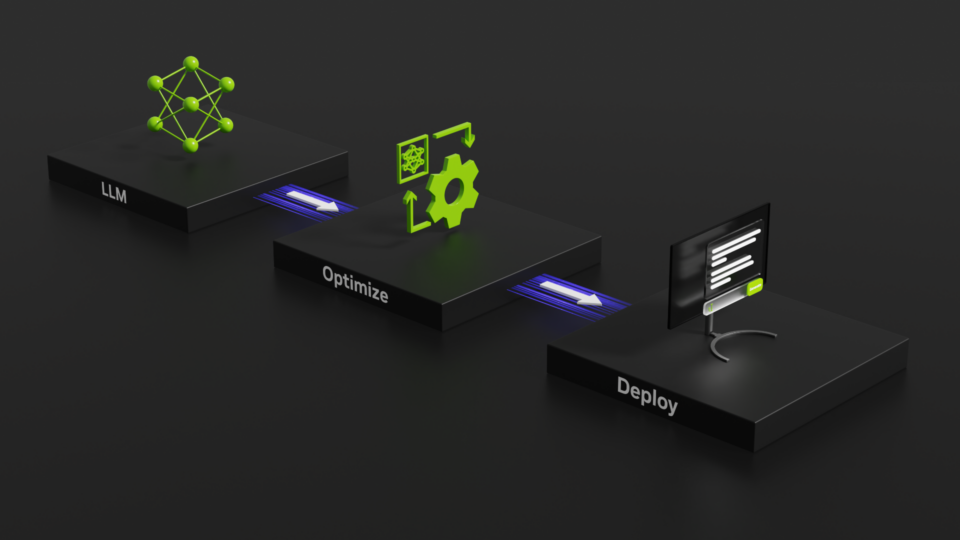
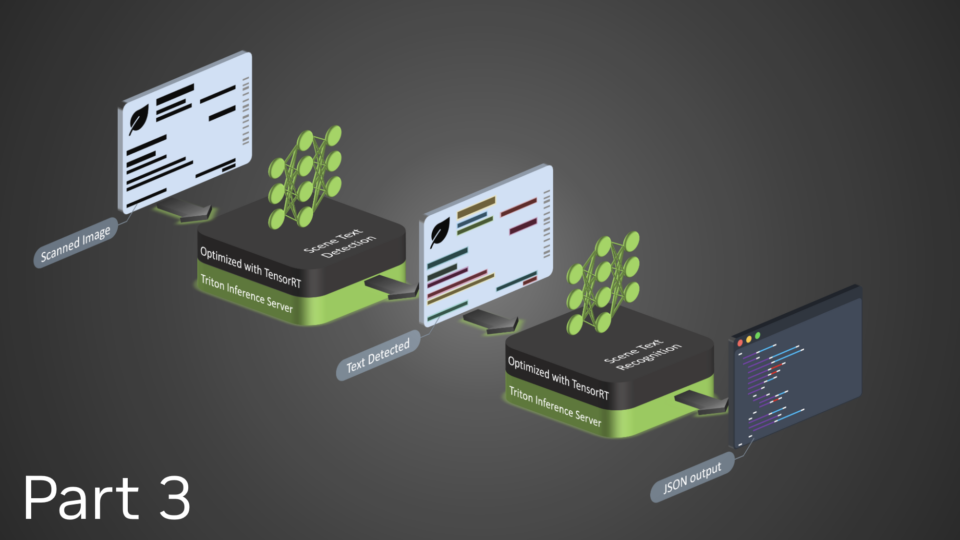
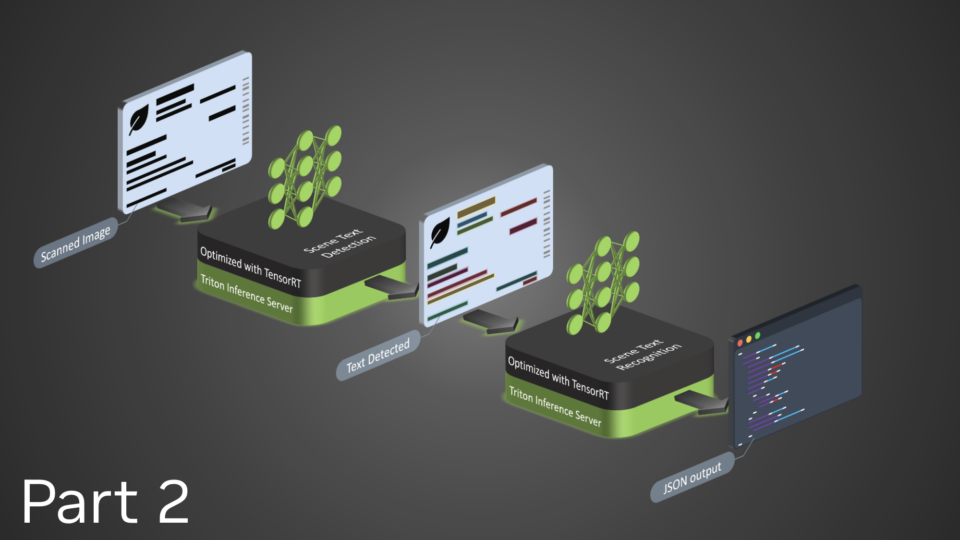
This week’s Model Monday release features the NVIDIA-optimized code Llama, Kosmos-2, and SeamlessM4T, which you can experience directly from your browser....
10 MIN READ