

As of March 18, 2025, NVIDIA Triton Inference Server is now part of the NVIDIA Dynamo Platform and has been renamed to NVIDIA Dynamo Triton, accordingly.
AI is a new way to write software and AI inference is running this software. AI machine learning is unlocking breakthrough applications in various fields such as online product recommendations, image classification, chatbots, forecasting, and manufacturing quality inspection.
Building an efficient platform
A given inference platform should consider all the factors. That is why building an efficient high-performance platform is hard.
- Applications
- Model types
- Frameworks
- AI platforms
- Computing processors
- Deployment environments
Applications
Applications have different requirements, which require different optimizations based on users’ needs.
- Some want to continuously process streaming data from sensors such as cameras or microphones.
- Some want optimized throughput at the lowest cost, such as processing satellite images to create high-fidelity maps.
- Some require real-time responsiveness, such as conversational AI chatbots.
Model types
Different use cases leverage different model types, which generate different computational graphs that should be compiled for optimal performance. Here are some of the popular model types:
- Convolutional neural networks (CNNs)
- Recurrent neural networks (RNNs)
- Transformers
- Decision trees
- Random forests
- Graph neural networks (GNNs)
Frameworks
Models are trained in different frameworks and come in different formats:
- TensorFlow
- PyTorch
- TensorRT
- ONNX
- MXNet
- XGBoost
AI platforms
Applications run on top of many different AI platforms:
- Homegrown platforms such as Cloudera or Domino Data Labor
- Public cloud ML platforms such as Amazon SageMaker, Azure ML, or Google Vertex AI
Computing processors
Choosing a computing processor is the next step of the long journey. Different generations of GPUs and CPUs are available. Running models on bare metal or virtualized machines is another consideration.
Deployment environments
Inference deployment environments can vary depending on the application:
- Public cloud
- On-premises core (data center)
- Enterprise edge
- On embedded devices
NVIDIA Triton Inference Server
NVIDIA Triton Inference Server is an open-source inference-serving software for fast and scalable AI in applications. It can help satisfy many of the preceding considerations of an inference platform. Here is a summary of the features. For more information, see the Triton Inference Server readme on GitHub.
- NVIDIA Triton can be used to deploy models from all popular frameworks. It supports TensorFlow 1.x and 2.x, PyTorch, ONNX, TensorRT, RAPIDS FIL (for XGBoost, Scikit-learn Random Forest, and LightGBM), OpenVINO, Python, and even custom C++ backends.
- NVIDIA Triton optimizes inference for multiple query types (real-time, batch, streaming) and also supports model ensembles.
- Supports high-performance inference on both NVIDIA GPUs and x86 & ARM CPUs.
- Runs on scale-out cloud or data center, enterprise edge, and even on embedded devices like the NVIDIA Jetson. It supports both bare metal and virtualized environments (e.g. VMware vSphere) for AI inference. There are dedicated NVIDIA Triton builds for running on Windows, Jetson, and ARM SBSA.
- Kubernetes and AI platform support:
- It is available as a Docker container and integrates easily with Kubernetes platforms like Amazon EKS, Google GKE, Azure AKS, Alibaba ACK, Tencent TKE or Red Hat OpenShift.
- NVIDIA Triton is available in managed CloudAI workflow platforms like Amazon SageMaker, Azure ML, Google Vertex AI, Alibaba Platform for AI with Elastic Algorithm Service, and Tencent TI-EMS.
Concurrent execution
GPUs are compute powerhouses capable of executing multiple workloads at the same time. NVIDIA Triton Inference Server maximizes performance and reduces end-to-end latency by running multiple models concurrently on the GPU. These models can be all the same or different models from different frameworks. The GPU memory size is the only limitation to the number of models that can run concurrently. This results in high GPU utilization and throughput.
Dynamic batching
One factor in the optimization of inference is batch size, or how many samples you process at one time. GPUs deliver high throughput at a higher batch size. However, for real-time applications, the real constraint on services isn’t batch size or even throughput, but rather the latency required to deliver an outstanding experience for end customers.
Here is a simple example. For a network of smart speakers, the maximum latency for the BERT model used in the NLP portion of the pipeline must be 7 ms or less to deliver a great experience. Figure 1 shows that to maintain a latency threshold of <7 ms, you could run up to batch size 24 to meet your target latency and maximize throughput.
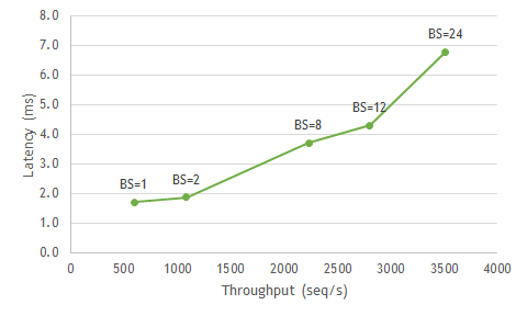
When running inference in a production environment, there are two types of batching: client-side (static) and server-side (dynamic). Typically, when a client sends a request to a server, the server by default processes each request sequentially, which isn’t optimal for throughput.
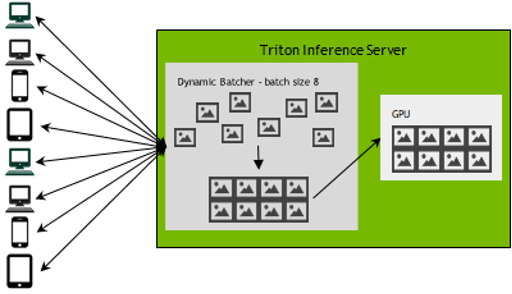
When implementing inference at scale, you may want to balance latency and throughput targets to meet the requirements of your application. Figure 2 shows how you can balance these priorities through the use of NVIDIA Triton Inference Server’s dynamic batching.
As independent inference requests come into the server, NVIDIA Triton dynamically groups client-side requests together on the server to form a larger batch. NVIDIA Triton can manage this batching to a specified latency target, enabling a balance of maximizing throughput within a specified latency target. NVIDIA Triton manages this task automatically, so you don’t have to make any changes to your code on the client.
For example, eight different devices might have a request for an image search at the same time, but NVIDIA Triton can batch them all together for a single query to the GPU to increase throughput rather than performing inference on each sequential request and still deliver a result at a low latency.
To understand how this works in practice, look at the example in Figure 3. The line shows the latency and throughput at different batch sizes for a given model. If the latency threshold to deliver a great experience to the users was 3 ms, you could set dynamic batching to 16 and meet the latency target while getting over 3x the performance compared to running at batch size 1. This example shows how NVIDIA Triton can help manage batch size and throughput to meet the requirements without relying on batch size to manage your service.
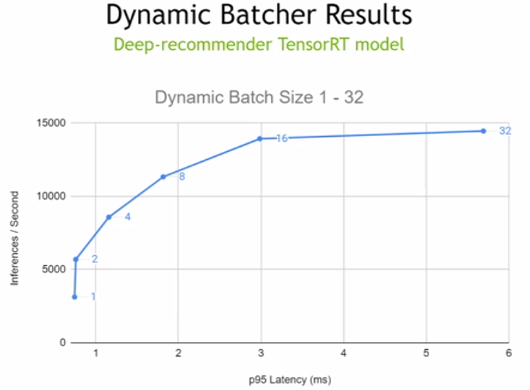
The NVIDIA Triton dynamic-batching feature can substantially increase throughput under strict latency constraints, thereby delivering high performance and utilization of the GPUs.
Here are some of the recently added features of NVIDIA Triton.
Model analyzer
For efficient inference serving, optimal model configurations such as the batch size and number of concurrent model instances should be identified for a given processor. Today, users manually try different, sometimes hundreds of, combinations to eventually find the optimal configuration for their throughput, latency, and memory utilization requirements.
NVIDIA Triton Model Analyzer is an optimization tool that automates this selection by automatically finding the best configuration for models to get the highest performance. You can specify performance requirements (such as a latency constraint, throughput target, or memory footprint) and the model analyzer searches through different configurations (batch sizes, concurrent model instances, and so on.) and find the one that provides the best performance under their constraints. It then outputs a summary report (Figure 3) to help visualize the performance of the top configurations.
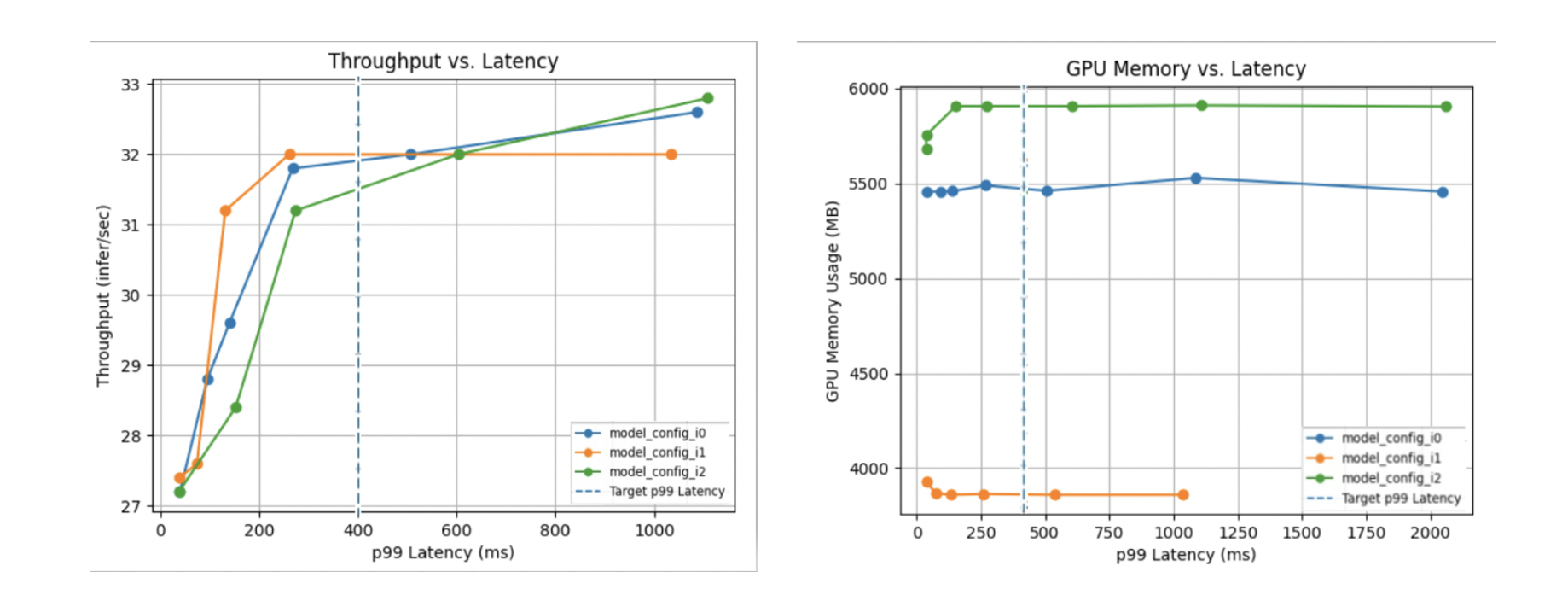
For more information, see the /triton-inference-server GitHub repo.
Multi-GPU Multi-node inference
NLP models are exponentially growing in size (doubling every 2.5 months). For example, NVIDIA Turing NLG (17B parameters) that came out in early 2020 should have at least 34 GB of GPU memory, GPT-3 (175B parameters) which was introduced middle of 2020 should have at least 350 GB of GPU memory, and the latest Megatron NVIDIA Turing NLG (530B parameters) model should have >1 TB of GPU memory. These large Transformer models cannot fit in a single GPU.
For these large Transformer models, NVIDIA Triton introduces Multi-GPU Multi-node inference. It uses the following model parallelism techniques to split a large model across multiple GPUs and nodes:
- Pipeline (inter-layer) parallelism that splits contiguous sets of layers across multiple GPUs. This maximizes GPU utilization in single-node.
- Tensor (intra-layer) parallelism that splits individual layers across multiple GPUs. This minimizes latency in single-node.
It uses NCCL in Magnum IO for topology-aware communication for high throughput.
Multi-GPU inference is required for real-time inference performance. The following is the comparison between running the Megatron Turing NLG (530B) model on both GPU and CPU-only servers.
- GPU: ~ ½ second with tensor and pipeline parallelism; 2 DGX-A100-80GB, Batch size=1, FP16, FasterTransformer 4.0, Triton 2.15.
- CPU: >1 minute; Xeon Platinum 8280 2S, Up to 1TB/socket System memory, Batch size=1, FP32, TensorFlow.
On two DGXs, the Megatron NVIDIA Turing NLG model can stream eight output tokens (six words) every ½ second to reduce the latency to display or speak for real-time conversation. As you can see, such large models should have the power of a GPU system to be practical.
Many GPU systems like DGX use NVLink for high-performance intra-node communication and Infiniband and Ethernet for inter-node communication.
New RAPIDS Forest Inference Library backend
NVIDIA Triton includes RAPIDS (FIL) as a backend for GPU or CPU inference of XGBoost, LightGBM, and ScikitLearn random forest models. With FIL integration, NVIDIA Triton is now a unified deployment engine for both deep learning and traditional machine learning workloads.
Tree models (XGBoost, Random Forest, LightGBM) are ubiquitous, especially in finance and recommender systems. However, packages that support deep-learning models rarely support tree model inference. In practice, many applications (especially recommender systems) use an ensemble of tree and DL models and require tools to support inference over these ensembles at massive scales.
For use cases like re-scoring all customers against all available products as often as possible or scoring every global credit card transaction against multiple fraud models, the FIL backend offers a highly optimized solution.
While other tree model deployment solutions often require converting models to specialized formats like ONNX, the FIL backend allows users to deploy XGBoost and LightGBM models as-trained. Furthermore, FIL’s GPU-accelerated inference means that you no longer have to compromise on small models to meet tight latency targets. Instead, you can take advantage of huge ensembles that offer far more sensitivity for uses cases such as fraud detection, without compromising your latency budgets.
NVIDIA Triton with FIL backend enables GPU-accelerated inference for even the largest tree models to be deployed for low-latency applications, improving accuracy for fraud detection, recommender systems, and more. Inference on XGBoost, LightGBM for non-categorical features, cuML/Scikit-Learn RandomForest for single-output regression, and binary classification can be done on both GPUs and CPUs. Categorical feature support for LightGBM models is coming soon.
New Amazon SageMaker integration
NVIDIA Triton Inference Server is now natively integrated and available in Amazon SageMaker. AWS and NVIDIA have worked closely to deliver this functionality to provide customers with NVIDIA Triton benefits in SageMaker. Amazon SageMaker is a fully managed service for data science and machine learning (ML) workflows.
Now, NVIDIA Triton Inference Server can be used to serve models for inference in Amazon SageMaker and benefit from the performance optimizations, dynamic batching, and multi-framework support provided by NVIDIA Triton:
- Create the NVIDIA Triton model repo and configuration in Amazon S3.
- Create the SageMaker NVIDIA Triton endpoint and deploy.
For more information, see Deploy fast and scalable AI with NVIDIA Triton Inference Server in Amazon SageMaker. NVIDIA Triton Inference Server Containers are available in all regions where Amazon SageMaker is available and comes at no additional cost.
NVIDIA Triton can be used in all the major cloud service providers, AWS, Google Cloud, Microsoft Azure, Alibaba Cloud, and Tencent Cloud, in managed Kubernetes and AI platform services.
Customer success stories
Here are some new customer success stories with NVIDIA Triton:
- Microsoft Teams
- Microsoft Azure Cognitive Services uses Triton on GPUs for ASR in Microsoft Teams for live captioning and transcription. For more information, see Live Captions, Transcription on Microsoft Teams Boosted With Microsoft Azure Cognitive Services and NVIDIA AI.
- Siemens Energy
- Siemens Energy uses NVIDIA Triton for autonomous operations in power plants. Computer vision models served by NVIDIA Triton Inference Server detect leaks and other abnormalities. For more information, see Electrifying AI: Siemens Energy Taps NVIDIA Triton Inference Server for Power Plant Inspections, Autonomy.
Conclusion
NVIDIA Triton helps with a standardized scalable production AI in every data center, cloud, and embedded device. It supports multiple frameworks, runs models on both CPUs and GPUs, handles different types of inference queries, and integrates with Kubernetes and MLOPs platforms.
Download NVIDIA Triton today as a Docker container from NGC and find the documentation on the /triton-inference-server GitHub repo. To learn more, see NVIDIA Triton Inference Server.
