Jun 11, 2024
Maximum Performance and Minimum Footprint for AI Apps with NVIDIA TensorRT Weight-Stripped Engines
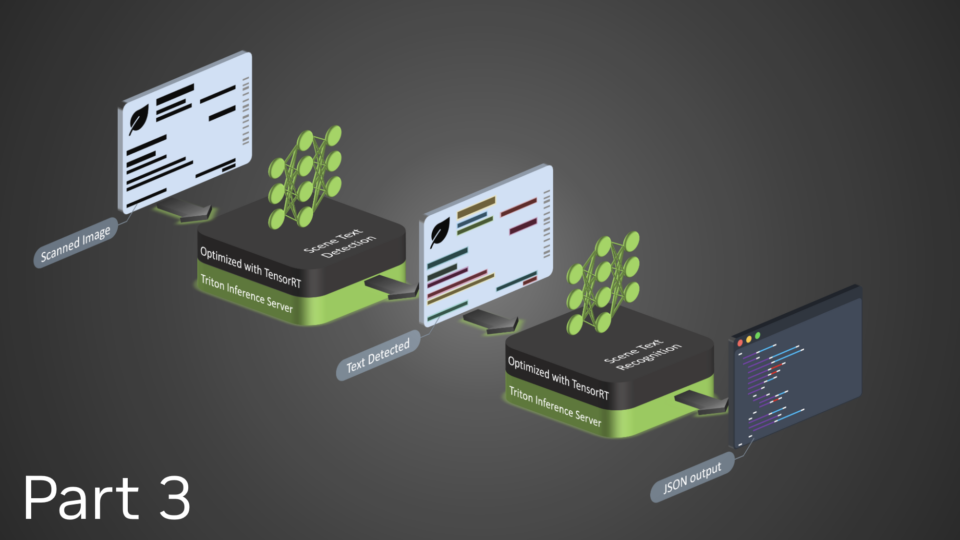
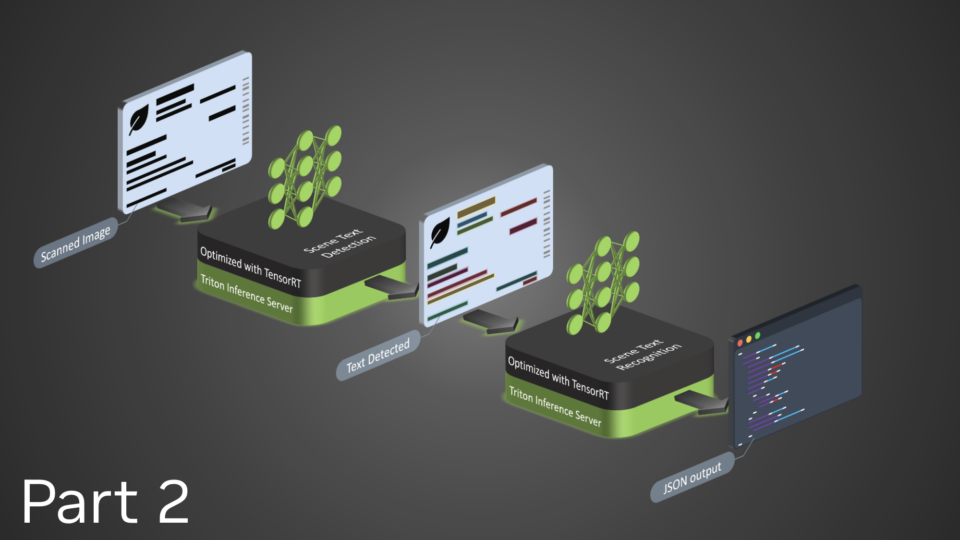
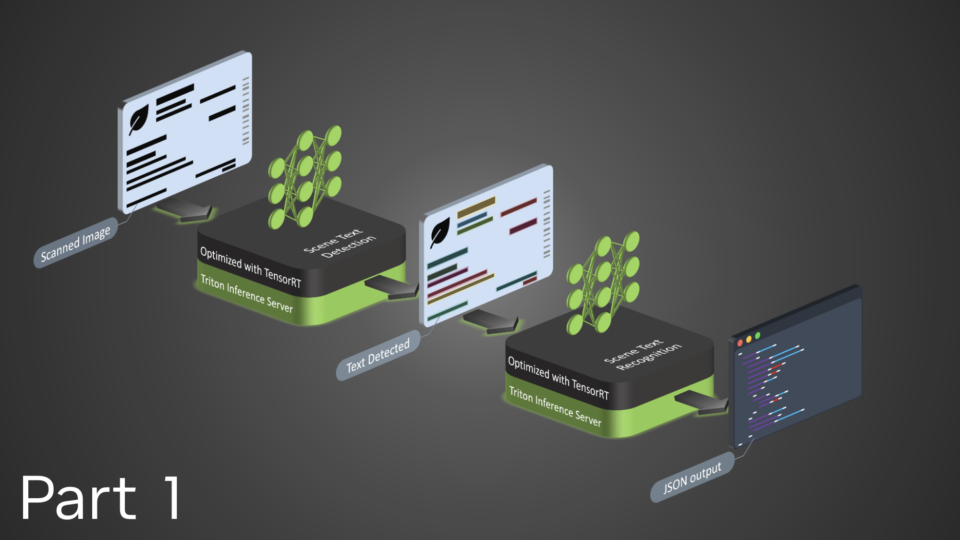
NVIDIA TensorRT, an established inference library for data centers, has rapidly emerged as a desirable inference backend for NVIDIA GeForce RTX and NVIDIA RTX...
8 MIN READ